 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniAppBench: Evaluating the Shift from Text to Interactive HTML Responses in LLM-Powered Assistants
Mar 10, 2026With the rapid advancement of Large Language Models (LLMs) in code generation, human-AI interaction is evolving from static text responses to dynamic, interactive HTML-based applications, which we term MiniApps. These applications require models to not only render visual interfaces but also construct customized interaction logic that adheres to real-world principles. However, existing benchmarks primarily focus on algorithmic correctness or static layout reconstruction, failing to capture the capabilities required for this new paradigm. To address this gap, we introduce MiniAppBench, the first comprehensive benchmark designed to evaluate principle-driven, interactive application generation. Sourced from a real-world application with 10M+ generations, MiniAppBench distills 500 tasks across six domains (e.g., Games, Science, and Tools). Furthermore, to tackle the challenge of evaluating open-ended interactions where no single ground truth exists, we propose MiniAppEval, an agentic evaluation framework. Leveraging browser automation, it performs human-like exploratory testing to systematically assess applications across three dimensions: Intention, Static, and Dynamic. Our experiments reveal that current LLMs still face significant challenges in generating high-quality MiniApps, while MiniAppEval demonstrates high alignment with human judgment, establishing a reliable standard for future research. Our code is available in github.com/MiniAppBench.
LiveAgentBench: Comprehensive Benchmarking of Agentic Systems Across 104 Real-World Challenges
Mar 03, 2026As large language models grow more capable, general AI agents have become increasingly prevalent in practical applications. However, existing benchmarks face significant limitations, failing to represent real-world user tasks accurately. To address this gap, we present LiveAgentBench, a comprehensive benchmark with 104 scenarios that reflect real user requirements. It is constructed from publicly sourced questions on social media and real-world products. Central to our approach is the Social Perception-Driven Data Generation (SPDG) method, a novel process we developed to ensure each question's real-world relevance, task complexity, and result verifiability. We evaluate various models, frameworks, and commercial products using LiveAgentBench, revealing their practical performance and identifying areas for improvement. This release includes 374 tasks, with 125 for validation and 249 for testing. The SPDG process enables continuous updates with fresh queries from real-world interactions.
V2P: Visual Attention Calibration for GUI Grounding via Background Suppression and Center Peaking
Jan 11, 2026Precise localization of GUI elements is crucial for the development of GUI agents. Traditional methods rely on bounding box or center-point regression, neglecting spatial interaction uncertainty and visual-semantic hierarchies. Recent methods incorporate attention mechanisms but still face two key issues: (1) ignoring processing background regions causes attention drift from the desired area, and (2) uniform modeling the target UI element fails to distinguish between its center and edges, leading to click imprecision. Inspired by how humans visually process and interact with GUI elements, we propose the Valley-to-Peak (V2P) method to address these issues. To mitigate background distractions, V2P introduces a suppression attention mechanism that minimizes the model's focus on irrelevant regions to highlight the intended region. For the issue of center-edge distinction, V2P applies a Fitts' Law-inspired approach by modeling GUI interactions as 2D Gaussian heatmaps where the weight gradually decreases from the center towards the edges. The weight distribution follows a Gaussian function, with the variance determined by the target's size. Consequently, V2P effectively isolates the target area and teaches the model to concentrate on the most essential point of the UI element. The model trained by V2P achieves the performance with 92.4\% and 52.5\% on two benchmarks ScreenSpot-v2 and ScreenSpot-Pro (see Fig.~\ref{fig:main_results_charts}). Ablations further confirm each component's contribution, underscoring V2P's generalizability in precise GUI grounding tasks and its potential for real-world deployment in future GUI agents.
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
AWorld: Dynamic Multi-Agent System with Stable Maneuvering for Robust GAIA Problem Solving
Aug 13, 2025The rapid advancement of large language models (LLMs) has empowered intelligent agents to leverage diverse external tools for solving complex real-world problems. However, as agents increasingly depend on multiple tools, they encounter new challenges: extended contexts from disparate sources and noisy or irrelevant tool outputs can undermine system reliability and accuracy. These challenges underscore the necessity for enhanced stability in agent-based systems. To address this, we introduce dynamic supervision and maneuvering mechanisms, constructing a robust and dynamic Multi-Agent System (MAS) architecture within the AWorld framework. In our approach, the Execution Agent invokes the Guard Agent at critical steps to verify and correct the reasoning process, effectively reducing errors arising from noise and bolstering problem-solving robustness. Extensive experiments on the GAIA test dataset reveal that our dynamic maneuvering mechanism significantly improves both the effectiveness and stability of solutions, outperforming single-agent system (SAS) and standard tool-augmented systems. As a result, our dynamic MAS system achieved first place among open-source projects on the prestigious GAIA leaderboard. These findings highlight the practical value of collaborative agent roles in developing more reliable and trustworthy intelligent systems.
Exploring Superior Function Calls via Reinforcement Learning
Aug 07, 2025Function calling capabilities are crucial for deploying Large Language Models in real-world applications, yet current training approaches fail to develop robust reasoning strategies. Supervised fine-tuning produces models that rely on superficial pattern matching, while standard reinforcement learning methods struggle with the complex action space of structured function calls. We present a novel reinforcement learning framework designed to enhance group relative policy optimization through strategic entropy based exploration specifically tailored for function calling tasks. Our approach addresses three critical challenges in function calling: insufficient exploration during policy learning, lack of structured reasoning in chain-of-thought generation, and inadequate verification of parameter extraction. Our two-stage data preparation pipeline ensures high-quality training samples through iterative LLM evaluation and abstract syntax tree validation. Extensive experiments on the Berkeley Function Calling Leaderboard demonstrate that this framework achieves state-of-the-art performance among open-source models with 86.02\% overall accuracy, outperforming standard GRPO by up to 6\% on complex multi-function scenarios. Notably, our method shows particularly strong improvements on code-pretrained models, suggesting that structured language generation capabilities provide an advantageous starting point for reinforcement learning in function calling tasks. We will release all the code, models and dataset to benefit the community.
FunReason: Enhancing Large Language Models' Function Calling via Self-Refinement Multiscale Loss and Automated Data Refinement
May 26, 2025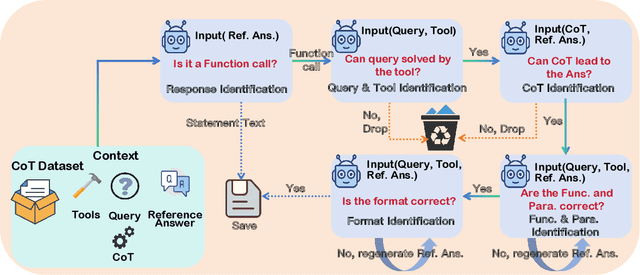
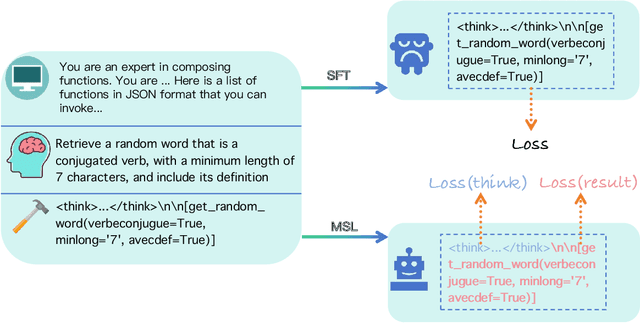

The integration of large language models (LLMs) with function calling has emerged as a crucial capability for enhancing their practical utility in real-world applications. However, effectively combining reasoning processes with accurate function execution remains a significant challenge. Traditional training approaches often struggle to balance the detailed reasoning steps with the precision of function calls, leading to suboptimal performance. To address these limitations, we introduce FunReason, a novel framework that enhances LLMs' function calling capabilities through an automated data refinement strategy and a Self-Refinement Multiscale Loss (SRML) approach. FunReason leverages LLMs' natural reasoning abilities to generate high-quality training examples, focusing on query parseability, reasoning coherence, and function call precision. The SRML approach dynamically balances the contribution of reasoning processes and function call accuracy during training, addressing the inherent trade-off between these two critical aspects. FunReason achieves performance comparable to GPT-4o while effectively mitigating catastrophic forgetting during fine-tuning. FunReason provides a comprehensive solution for enhancing LLMs' function calling capabilities by introducing a balanced training methodology and a data refinement pipeline. For code and dataset, please refer to our repository at GitHub https://github.com/BingguangHao/FunReason
PiCo: Enhancing Text-Image Alignment with Improved Noise Selection and Precise Mask Control in Diffusion Models
May 06, 2025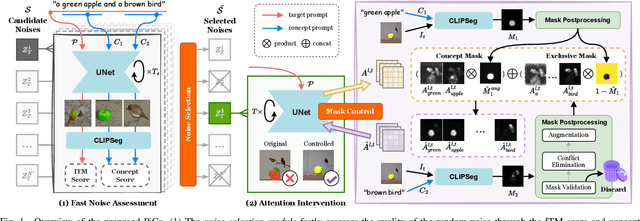
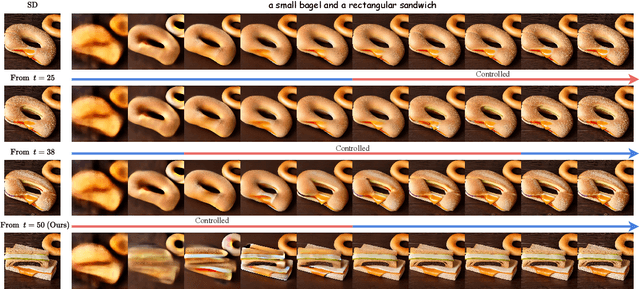


Advanced diffusion models have made notable progress in text-to-image compositional generation. However, it is still a challenge for existing models to achieve text-image alignment when confronted with complex text prompts. In this work, we highlight two factors that affect this alignment: the quality of the randomly initialized noise and the reliability of the generated controlling mask. We then propose PiCo (Pick-and-Control), a novel training-free approach with two key components to tackle these two factors. First, we develop a noise selection module to assess the quality of the random noise and determine whether the noise is suitable for the target text. A fast sampling strategy is utilized to ensure efficiency in the noise selection stage. Second, we introduce a referring mask module to generate pixel-level masks and to precisely modulate the cross-attention maps. The referring mask is applied to the standard diffusion process to guide the reasonable interaction between text and image features. Extensive experiments have been conducted to verify the effectiveness of PiCo in liberating users from the tedious process of random generation and in enhancing the text-image alignment for diverse text descriptions.
Uni4D: A Unified Self-Supervised Learning Framework for Point Cloud Videos
Apr 07, 2025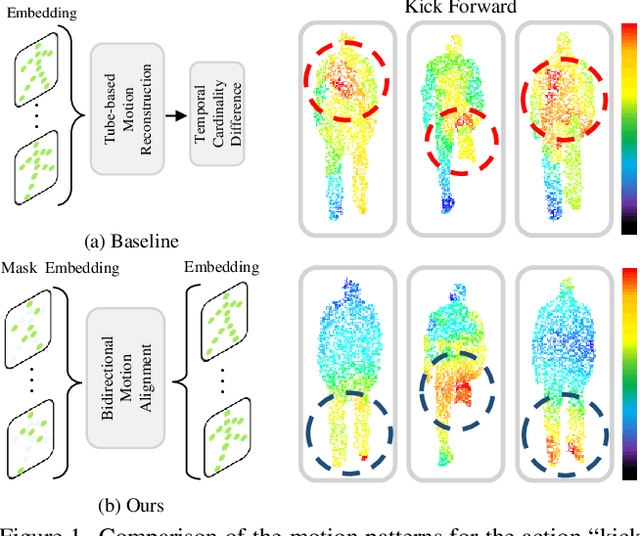
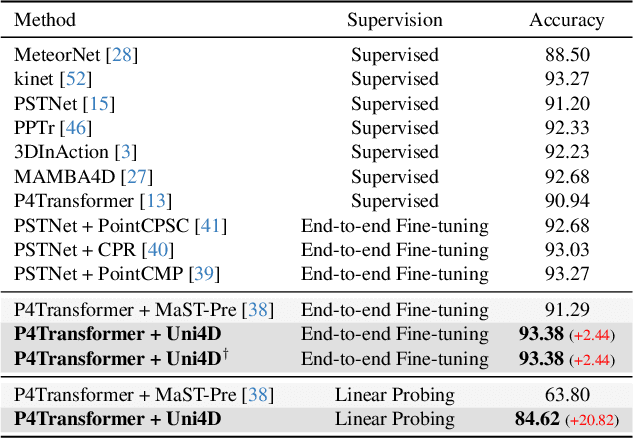
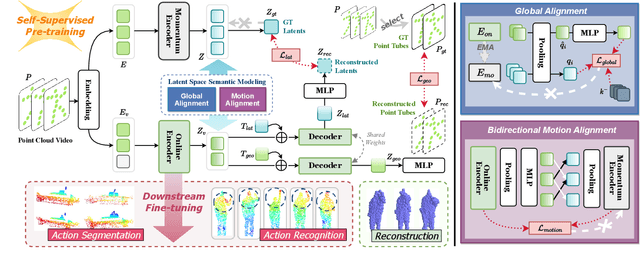

Point cloud video representation learning is primarily built upon the masking strategy in a self-supervised manner. However, the progress is slow due to several significant challenges: (1) existing methods learn the motion particularly with hand-crafted designs, leading to unsatisfactory motion patterns during pre-training which are non-transferable on fine-tuning scenarios. (2) previous Masked AutoEncoder (MAE) frameworks are limited in resolving the huge representation gap inherent in 4D data. In this study, we introduce the first self-disentangled MAE for learning discriminative 4D representations in the pre-training stage. To address the first challenge, we propose to model the motion representation in a latent space. The second issue is resolved by introducing the latent tokens along with the typical geometry tokens to disentangle high-level and low-level features during decoding. Extensive experiments on MSR-Action3D, NTU-RGBD, HOI4D, NvGesture, and SHREC'17 verify this self-disentangled learning framework. We demonstrate that it can boost the fine-tuning performance on all 4D tasks, which we term Uni4D. Our pre-trained model presents discriminative and meaningful 4D representations, particularly benefits processing long videos, as Uni4D gets $+3.8\%$ segmentation accuracy on HOI4D, significantly outperforming either self-supervised or fully-supervised methods after end-to-end fine-tuning.
CSR:Achieving 1 Bit Key-Value Cache via Sparse Representation
Dec 16, 2024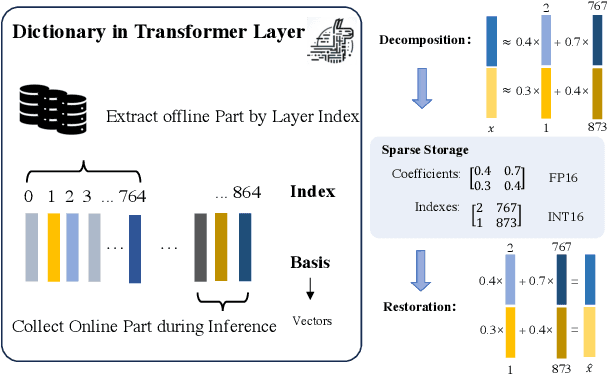

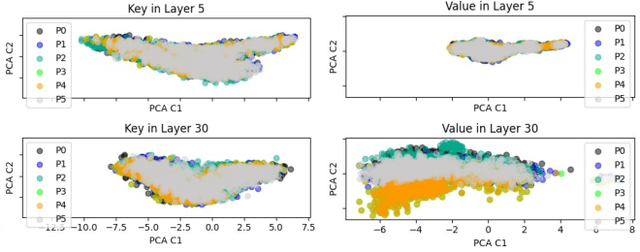
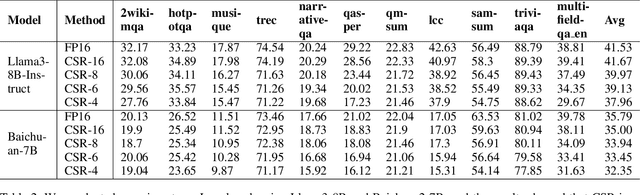
The emergence of long-context text applications utilizing large language models (LLMs) has presented significant scalability challenges, particularly in memory footprint. The linear growth of the Key-Value (KV) cache responsible for storing attention keys and values to minimize redundant computations can lead to substantial increases in memory consumption, potentially causing models to fail to serve with limited memory resources. To address this issue, we propose a novel approach called Cache Sparse Representation (CSR), which converts the KV cache by transforming the dense Key-Value cache tensor into sparse indexes and weights, offering a more memory-efficient representation during LLM inference. Furthermore, we introduce NeuralDict, a novel neural network-based method for automatically generating the dictionary used in our sparse representation. Our extensive experiments demonstrate that CSR achieves performance comparable to state-of-the-art KV cache quantization algorithms while maintaining robust functionality in memory-constrained environments.