 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuseST: Unleashing the Capability of the Diffusion Model for Style Transfer
Paper and Code

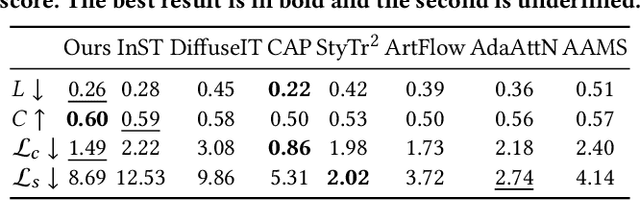
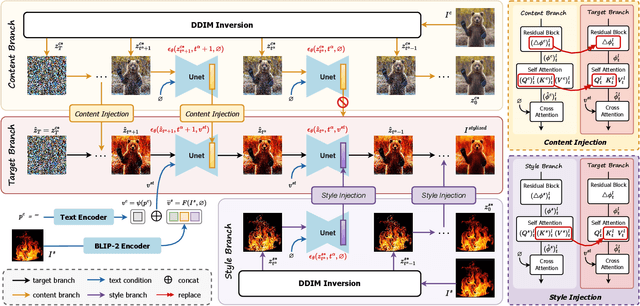

Style transfer aims to fuse the artistic representation of a style image with the structural information of a content image. Existing methods train specific networks or utilize pre-trained models to learn content and style features. However, they rely solely on textual or spatial representations that are inadequate to achieve the balance between content and style. In this work, we propose a novel and training-free approach for style transfer, combining textual embedding with spatial features and separating the injection of content or style. Specifically, we adopt the BLIP-2 encoder to extract the textual representation of the style image. We utilize the DDIM inversion technique to extract intermediate embeddings in content and style branches as spatial features. Finally, we harness the step-by-step property of diffusion models by separating the injection of content and style in the target branch, which improves the balance between content preservation and style fusion. Various experiments have demonstrated the effectiveness and robustness of our proposed DiffeseST for achieving balanced and controllable style transfer results, as well as the potential to extend to other tasks.