 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
Exploring Superior Function Calls via Reinforcement Learning
Aug 07, 2025Function calling capabilities are crucial for deploying Large Language Models in real-world applications, yet current training approaches fail to develop robust reasoning strategies. Supervised fine-tuning produces models that rely on superficial pattern matching, while standard reinforcement learning methods struggle with the complex action space of structured function calls. We present a novel reinforcement learning framework designed to enhance group relative policy optimization through strategic entropy based exploration specifically tailored for function calling tasks. Our approach addresses three critical challenges in function calling: insufficient exploration during policy learning, lack of structured reasoning in chain-of-thought generation, and inadequate verification of parameter extraction. Our two-stage data preparation pipeline ensures high-quality training samples through iterative LLM evaluation and abstract syntax tree validation. Extensive experiments on the Berkeley Function Calling Leaderboard demonstrate that this framework achieves state-of-the-art performance among open-source models with 86.02\% overall accuracy, outperforming standard GRPO by up to 6\% on complex multi-function scenarios. Notably, our method shows particularly strong improvements on code-pretrained models, suggesting that structured language generation capabilities provide an advantageous starting point for reinforcement learning in function calling tasks. We will release all the code, models and dataset to benefit the community.
Hierarchical Language Models for Semantic Navigation and Manipulation in an Aerial-Ground Robotic System
Jun 05, 2025Heterogeneous multi-robot systems show great potential in complex tasks requiring coordinated hybrid cooperation. However, traditional approaches relying on static models often struggle with task diversity and dynamic environments. This highlights the need for generalizable intelligence that can bridge high-level reasoning with low-level execution across heterogeneous agents. To address this, we propose a hierarchical framework integrating a prompted Large Language Model (LLM) and a GridMask-enhanced fine-tuned Vision Language Model (VLM). The LLM performs task decomposition and global semantic map construction, while the VLM extracts task-specified semantic labels and 2D spatial information from aerial images to support local planning. Within this framework, the aerial robot follows a globally optimized semantic path and continuously provides bird-view images, guiding the ground robot's local semantic navigation and manipulation, including target-absent scenarios where implicit alignment is maintained. Experiments on a real-world letter-cubes arrangement task demonstrate the framework's adaptability and robustness in dynamic environments. To the best of our knowledge, this is the first demonstration of an aerial-ground heterogeneous system integrating VLM-based perception with LLM-driven task reasoning and motion planning.
FunReason: Enhancing Large Language Models' Function Calling via Self-Refinement Multiscale Loss and Automated Data Refinement
May 26, 2025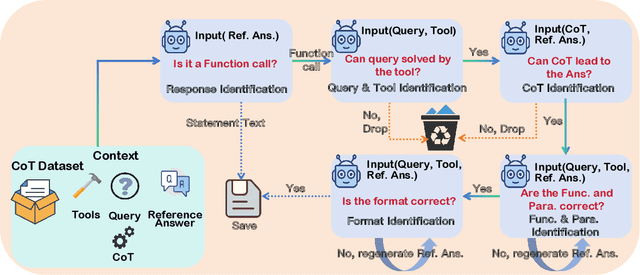
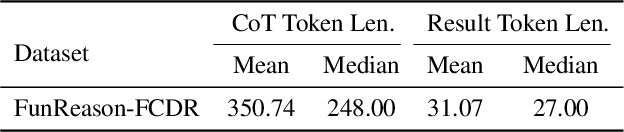
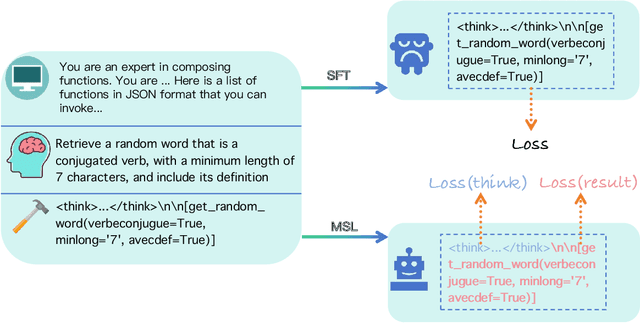

The integration of large language models (LLMs) with function calling has emerged as a crucial capability for enhancing their practical utility in real-world applications. However, effectively combining reasoning processes with accurate function execution remains a significant challenge. Traditional training approaches often struggle to balance the detailed reasoning steps with the precision of function calls, leading to suboptimal performance. To address these limitations, we introduce FunReason, a novel framework that enhances LLMs' function calling capabilities through an automated data refinement strategy and a Self-Refinement Multiscale Loss (SRML) approach. FunReason leverages LLMs' natural reasoning abilities to generate high-quality training examples, focusing on query parseability, reasoning coherence, and function call precision. The SRML approach dynamically balances the contribution of reasoning processes and function call accuracy during training, addressing the inherent trade-off between these two critical aspects. FunReason achieves performance comparable to GPT-4o while effectively mitigating catastrophic forgetting during fine-tuning. FunReason provides a comprehensive solution for enhancing LLMs' function calling capabilities by introducing a balanced training methodology and a data refinement pipeline. For code and dataset, please refer to our repository at GitHub https://github.com/BingguangHao/FunReason
MIG: Automatic Data Selection for Instruction Tuning by Maximizing Information Gain in Semantic Space
Apr 18, 2025Data quality and diversity are key to the construction of effective instruction-tuning datasets. % With the increasing availability of open-source instruction-tuning datasets, it is advantageous to automatically select high-quality and diverse subsets from a vast amount of data. % Existing methods typically prioritize instance quality and use heuristic rules to maintain diversity. % However, this absence of a comprehensive view of the entire collection often leads to suboptimal results. % Moreover, heuristic rules generally focus on distance or clustering within the embedding space, which fails to accurately capture the intent of complex instructions in the semantic space. % To bridge this gap, we propose a unified method for quantifying the information content of datasets. This method models the semantic space by constructing a label graph and quantifies diversity based on the distribution of information within the graph. % Based on such a measurement, we further introduce an efficient sampling method that selects data samples iteratively to \textbf{M}aximize the \textbf{I}nformation \textbf{G}ain (MIG) in semantic space. % Experiments on various datasets and base models demonstrate that MIG consistently outperforms state-of-the-art methods. % Notably, the model fine-tuned with 5\% Tulu3 data sampled by MIG achieves comparable performance to the official SFT model trained on the full dataset, with improvements of +5.73\% on AlpacaEval and +6.89\% on Wildbench.
A Comprehensive Survey of Reward Models: Taxonomy, Applications, Challenges, and Future
Apr 12, 2025Reward Model (RM) has demonstrated impressive potential for enhancing Large Language Models (LLM), as RM can serve as a proxy for human preferences, providing signals to guide LLMs' behavior in various tasks. In this paper, we provide a comprehensive overview of relevant research, exploring RMs from the perspectives of preference collection, reward modeling, and usage. Next, we introduce the applications of RMs and discuss the benchmarks for evaluation. Furthermore, we conduct an in-depth analysis of the challenges existing in the field and dive into the potential research directions. This paper is dedicated to providing beginners with a comprehensive introduction to RMs and facilitating future studies. The resources are publicly available at github\footnote{https://github.com/JLZhong23/awesome-reward-models}.
Auto Cherry-Picker: Learning from High-quality Generative Data Driven by Language
Jun 28, 2024



Diffusion-based models have shown great potential in generating high-quality images with various layouts, which can benefit downstream perception tasks. However, a fully automatic layout generation driven only by language and a suitable metric for measuring multiple generated instances has not been well explored. In this work, we present Auto Cherry-Picker (ACP), a novel framework that generates high-quality multi-modal training examples to augment perception and multi-modal training. Starting with a simple list of natural language concepts, we prompt large language models (LLMs) to generate a detailed description and design reasonable layouts. Next, we use an off-the-shelf text-to-image model to generate multiple images. Then, the generated data are refined using a comprehensively designed metric to ensure quality. In particular, we present a new metric, Composite Layout and Image Score (CLIS), to evaluate the generated images fairly. Our synthetic high-quality examples boost performance in various scenarios by customizing the initial concept list, especially in addressing challenges associated with long-tailed distribution and imbalanced datasets. Experiment results on downstream tasks demonstrate that Auto Cherry-Picker can significantly improve the performance of existing models. In addition, we have thoroughly investigated the correlation between CLIS and performance gains in downstream tasks, and we find that a better CLIS score results in better performance. This finding shows the potential for evaluation metrics as the role for various visual perception and MLLM tasks. Code will be available.
Are LLM-based Evaluators Confusing NLG Quality Criteria?
Feb 19, 2024



Some prior work has shown that LLMs perform well in NLG evaluation for different tasks. However, we discover that LLMs seem to confuse different evaluation criteria, which reduces their reliability. For further verification, we first consider avoiding issues of inconsistent conceptualization and vague expression in existing NLG quality criteria themselves. So we summarize a clear hierarchical classification system for 11 common aspects with corresponding different criteria from previous studies involved. Inspired by behavioral testing, we elaborately design 18 types of aspect-targeted perturbation attacks for fine-grained analysis of the evaluation behaviors of different LLMs. We also conduct human annotations beyond the guidance of the classification system to validate the impact of the perturbations. Our experimental results reveal confusion issues inherent in LLMs, as well as other noteworthy phenomena, and necessitate further research and improvements for LLM-based evaluation.
An Open and Comprehensive Pipeline for Unified Object Grounding and Detection
Jan 05, 2024Grounding-DINO is a state-of-the-art open-set detection model that tackles multiple vision tasks including Open-Vocabulary Detection (OVD), Phrase Grounding (PG), and Referring Expression Comprehension (REC). Its effectiveness has led to its widespread adoption as a mainstream architecture for various downstream applications. However, despite its significance, the original Grounding-DINO model lacks comprehensive public technical details due to the unavailability of its training code. To bridge this gap, we present MM-Grounding-DINO, an open-source, comprehensive, and user-friendly baseline, which is built with the MMDetection toolbox. It adopts abundant vision datasets for pre-training and various detection and grounding datasets for fine-tuning. We give a comprehensive analysis of each reported result and detailed settings for reproduction. The extensive experiments on the benchmarks mentioned demonstrate that our MM-Grounding-DINO-Tiny outperforms the Grounding-DINO-Tiny baseline. We release all our models to the research community. Codes and trained models are released at https://github.com/open-mmlab/mmdetection/tree/main/configs/mm_grounding_dino.
S2M: Converting Single-Turn to Multi-Turn Datasets for Conversational Question Answering
Dec 27, 2023Supplying data augmentation to conversational question answering (CQA) can effectively improve model performance. However, there is less improvement from single-turn datasets in CQA due to the distribution gap between single-turn and multi-turn datasets. On the other hand, while numerous single-turn datasets are available, we have not utilized them effectively. To solve this problem, we propose a novel method to convert single-turn datasets to multi-turn datasets. The proposed method consists of three parts, namely, a QA pair Generator, a QA pair Reassembler, and a question Rewriter. Given a sample consisting of context and single-turn QA pairs, the Generator obtains candidate QA pairs and a knowledge graph based on the context. The Reassembler utilizes the knowledge graph to get sequential QA pairs, and the Rewriter rewrites questions from a conversational perspective to obtain a multi-turn dataset S2M. Our experiments show that our method can synthesize effective training resources for CQA. Notably, S2M ranks 1st place on the QuAC leaderboard at the time of submission (Aug 24th, 2022).