 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
Controlled Self-Evolution for Algorithmic Code Optimization
Jan 13, 2026Self-evolution methods enhance code generation through iterative "generate-verify-refine" cycles, yet existing approaches suffer from low exploration efficiency, failing to discover solutions with superior complexity within limited budgets. This inefficiency stems from initialization bias trapping evolution in poor solution regions, uncontrolled stochastic operations lacking feedback guidance, and insufficient experience utilization across tasks. To address these bottlenecks, we propose Controlled Self-Evolution (CSE), which consists of three key components. Diversified Planning Initialization generates structurally distinct algorithmic strategies for broad solution space coverage. Genetic Evolution replaces stochastic operations with feedback-guided mechanisms, enabling targeted mutation and compositional crossover. Hierarchical Evolution Memory captures both successful and failed experiences at inter-task and intra-task levels. Experiments on EffiBench-X demonstrate that CSE consistently outperforms all baselines across various LLM backbones. Furthermore, CSE achieves higher efficiency from early generations and maintains continuous improvement throughout evolution. Our code is publicly available at https://github.com/QuantaAlpha/EvoControl.
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
Jan 13, 2026While autonomous software engineering (SWE) agents are reshaping programming paradigms, they currently suffer from a "closed-world" limitation: they attempt to fix bugs from scratch or solely using local context, ignoring the immense historical human experience available on platforms like GitHub. Accessing this open-world experience is hindered by the unstructured and fragmented nature of real-world issue-tracking data. In this paper, we introduce MemGovern, a framework designed to govern and transform raw GitHub data into actionable experiential memory for agents. MemGovern employs experience governance to convert human experience into agent-friendly experience cards and introduces an agentic experience search strategy that enables logic-driven retrieval of human expertise. By producing 135K governed experience cards, MemGovern achieves a significant performance boost, improving resolution rates on the SWE-bench Verified by 4.65%. As a plug-in approach, MemGovern provides a solution for agent-friendly memory infrastructure.
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Jan 11, 2026In real-world video question answering scenarios, videos often provide only localized visual cues, while verifiable answers are distributed across the open web; models therefore need to jointly perform cross-frame clue extraction, iterative retrieval, and multi-hop reasoning-based verification. To bridge this gap, we construct the first video deep research benchmark, VideoDR. VideoDR centers on video-conditioned open-domain video question answering, requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over joint video-web evidence; through rigorous human annotation and quality control, we obtain high-quality video deep research samples spanning six semantic domains. We evaluate multiple closed-source and open-source multimodal large language models under both the Workflow and Agentic paradigms, and the results show that Agentic is not consistently superior to Workflow: its gains depend on a model's ability to maintain the initial video anchors over long retrieval chains. Further analysis indicates that goal drift and long-horizon consistency are the core bottlenecks. In sum, VideoDR provides a systematic benchmark for studying video agents in open-web settings and reveals the key challenges for next-generation video deep research agents.
CloneMem: Benchmarking Long-Term Memory for AI Clones
Jan 11, 2026AI Clones aim to simulate an individual's thoughts and behaviors to enable long-term, personalized interaction, placing stringent demands on memory systems to model experiences, emotions, and opinions over time. Existing memory benchmarks primarily rely on user-agent conversational histories, which are temporally fragmented and insufficient for capturing continuous life trajectories. We introduce CloneMem, a benchmark for evaluating longterm memory in AI Clone scenarios grounded in non-conversational digital traces, including diaries, social media posts, and emails, spanning one to three years. CloneMem adopts a hierarchical data construction framework to ensure longitudinal coherence and defines tasks that assess an agent's ability to track evolving personal states. Experiments show that current memory mechanisms struggle in this setting, highlighting open challenges for life-grounded personalized AI. Code and dataset are available at https://github.com/AvatarMemory/CloneMemBench
RealMem: Benchmarking LLMs in Real-World Memory-Driven Interaction
Jan 11, 2026As Large Language Models (LLMs) evolve from static dialogue interfaces to autonomous general agents, effective memory is paramount to ensuring long-term consistency. However, existing benchmarks primarily focus on casual conversation or task-oriented dialogue, failing to capture **"long-term project-oriented"** interactions where agents must track evolving goals. To bridge this gap, we introduce **RealMem**, the first benchmark grounded in realistic project scenarios. RealMem comprises over 2,000 cross-session dialogues across eleven scenarios, utilizing natural user queries for evaluation. We propose a synthesis pipeline that integrates Project Foundation Construction, Multi-Agent Dialogue Generation, and Memory and Schedule Management to simulate the dynamic evolution of memory. Experiments reveal that current memory systems face significant challenges in managing the long-term project states and dynamic context dependencies inherent in real-world projects. Our code and datasets are available at [https://github.com/AvatarMemory/RealMemBench](https://github.com/AvatarMemory/RealMemBench).
KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions
Jan 08, 2026Existing long-horizon memory benchmarks mostly use multi-turn dialogues or synthetic user histories, which makes retrieval performance an imperfect proxy for person understanding. We present \BenchName, a publicly releasable benchmark built from long-form autobiographical narratives, where actions, context, and inner thoughts provide dense evidence for inferring stable motivations and decision principles. \BenchName~reconstructs each narrative into a flashback-aware, time-anchored stream and evaluates models with evidence-linked questions spanning factual recall, subjective state attribution, and principle-level reasoning. Across diverse narrative sources, retrieval-augmented systems mainly improve factual accuracy, while errors persist on temporally grounded explanations and higher-level inferences, highlighting the need for memory mechanisms beyond retrieval. Our data is in \href{KnowMeBench}{https://github.com/QuantaAlpha/KnowMeBench}.
Does Memory Need Graphs? A Unified Framework and Empirical Analysis for Long-Term Dialog Memory
Jan 07, 2026Graph structures are increasingly used in dialog memory systems, but empirical findings on their effectiveness remain inconsistent, making it unclear which design choices truly matter. We present an experimental, system-oriented analysis of long-term dialog memory architectures. We introduce a unified framework that decomposes dialog memory systems into core components and supports both graph-based and non-graph approaches. Under this framework, we conduct controlled, stage-wise experiments on LongMemEval and HaluMem, comparing common design choices in memory representation, organization, maintenance, and retrieval. Our results show that many performance differences are driven by foundational system settings rather than specific architectural innovations. Based on these findings, we identify stable and reliable strong baselines for future dialog memory research.
Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration
Nov 19, 2025Existing multimodal reasoning models and frameworks suffer from fundamental architectural limitations: most lack the human-like ability to autonomously explore diverse reasoning pathways-whether in direct inference, tool-driven visual exploration, programmatic visual manipulation, or intrinsic visual imagination. Consequently, they struggle to adapt to dynamically changing capability requirements in real-world tasks. Meanwhile, humans exhibit a complementary set of thinking abilities when addressing such tasks, whereas existing methods typically cover only a subset of these dimensions. Inspired by this, we propose Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration, a new paradigm for multimodal agentic reasoning. We define six core capabilities essential for multimodal reasoning and organize a comprehensive evaluation benchmark, Octopus-Bench, accordingly. Octopus is capable of autonomously exploring during reasoning and dynamically selecting the most appropriate capability based on the current state. Experimental results show that Octopus achieves the best performance on the vast majority of tasks in Octopus-Bench, highlighting the crucial role of capability coordination in agentic multimodal reasoning.
GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
Aug 26, 2025

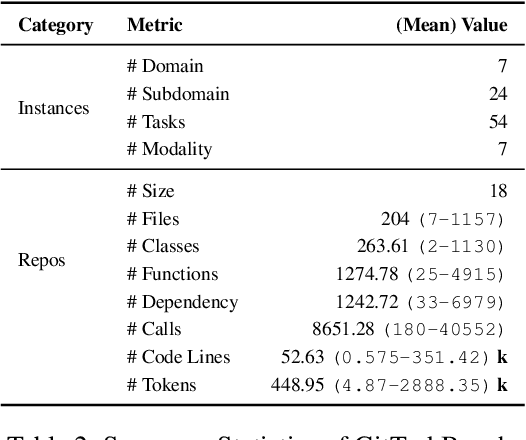
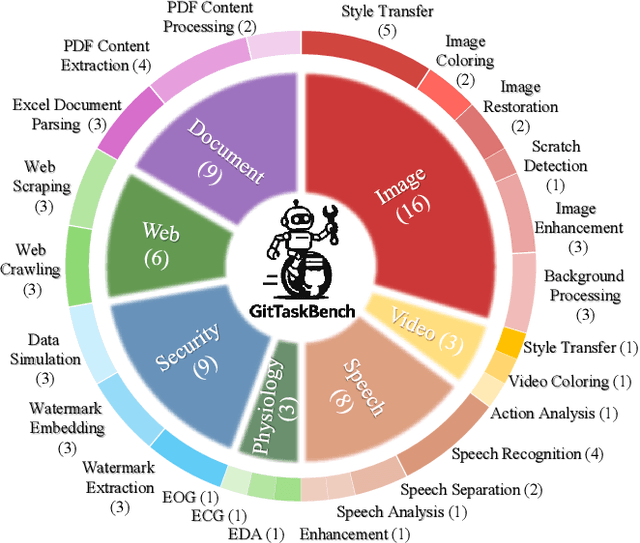
Beyond scratch coding, exploiting large-scale code repositories (e.g., GitHub) for practical tasks is vital in real-world software development, yet current benchmarks rarely evaluate code agents in such authentic, workflow-driven scenarios. To bridge this gap, we introduce GitTaskBench, a benchmark designed to systematically assess this capability via 54 realistic tasks across 7 modalities and 7 domains. Each task pairs a relevant repository with an automated, human-curated evaluation harness specifying practical success criteria. Beyond measuring execution and task success, we also propose the alpha-value metric to quantify the economic benefit of agent performance, which integrates task success rates, token cost, and average developer salaries. Experiments across three state-of-the-art agent frameworks with multiple advanced LLMs show that leveraging code repositories for complex task solving remains challenging: even the best-performing system, OpenHands+Claude 3.7, solves only 48.15% of tasks. Error analysis attributes over half of failures to seemingly mundane yet critical steps like environment setup and dependency resolution, highlighting the need for more robust workflow management and increased timeout preparedness. By releasing GitTaskBench, we aim to drive progress and attention toward repository-aware code reasoning, execution, and deployment -- moving agents closer to solving complex, end-to-end real-world tasks. The benchmark and code are open-sourced at https://github.com/QuantaAlpha/GitTaskBench.