 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Mindset: Reasoning with Adaptive Cognitive Modes
Feb 10, 2026Human problem-solving is never the repetition of a single mindset, by which we mean a distinct mode of cognitive processing. When tackling a specific task, we do not rely on a single mindset; instead, we integrate multiple mindsets within the single solution process. However, existing LLM reasoning methods fall into a common trap: they apply the same fixed mindset across all steps, overlooking that different stages of solving the same problem require fundamentally different mindsets. This single-minded assumption prevents models from reaching the next level of intelligence. To address this limitation, we propose Chain of Mindset (CoM), a training-free agentic framework that enables step-level adaptive mindset orchestration. CoM decomposes reasoning into four functionally heterogeneous mindsets: Spatial, Convergent, Divergent, and Algorithmic. A Meta-Agent dynamically selects the optimal mindset based on the evolving reasoning state, while a bidirectional Context Gate filters cross-module information flow to maintain effectiveness and efficiency. Experiments across six challenging benchmarks spanning mathematics, code generation, scientific QA, and spatial reasoning demonstrate that CoM achieves state-of-the-art performance, outperforming the strongest baseline by 4.96\% and 4.72\% in overall accuracy on Qwen3-VL-32B-Instruct and Gemini-2.0-Flash, while balancing reasoning efficiency. Our code is publicly available at \href{https://github.com/QuantaAlpha/chain-of-mindset}{https://github.com/QuantaAlpha/chain-of-mindset}.
QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
Feb 06, 2026Financial markets are noisy and non-stationary, making alpha mining highly sensitive to noise in backtesting results and sudden market regime shifts. While recent agentic frameworks improve alpha mining automation, they often lack controllable multi-round search and reliable reuse of validated experience. To address these challenges, we propose QuantaAlpha, an evolutionary alpha mining framework that treats each end-to-end mining run as a trajectory and improves factors through trajectory-level mutation and crossover operations. QuantaAlpha localizes suboptimal steps in each trajectory for targeted revision and recombines complementary high-reward segments to reuse effective patterns, enabling structured exploration and refinement across mining iterations. During factor generation, QuantaAlpha enforces semantic consistency across the hypothesis, factor expression, and executable code, while constraining the complexity and redundancy of the generated factor to mitigate crowding. Extensive experiments on the China Securities Index 300 (CSI 300) demonstrate consistent gains over strong baseline models and prior agentic systems. When utilizing GPT-5.2, QuantaAlpha achieves an Information Coefficient (IC) of 0.1501, with an Annualized Rate of Return (ARR) of 27.75% and a Maximum Drawdown (MDD) of 7.98%. Moreover, factors mined on CSI 300 transfer effectively to the China Securities Index 500 (CSI 500) and the Standard & Poor's 500 Index (S&P 500), delivering 160% and 137% cumulative excess return over four years, respectively, which indicates strong robustness of QuantaAlpha under market distribution shifts.
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
Feb 02, 2026Despite the success of multimodal contrastive learning in aligning visual and linguistic representations, a persistent geometric anomaly, the Modality Gap, remains: embeddings of distinct modalities expressing identical semantics occupy systematically offset regions. Prior approaches to bridge this gap are largely limited by oversimplified isotropic assumptions, hindering their application in large-scale scenarios. In this paper, we address these limitations by precisely characterizing the geometric shape of the modality gap and leveraging it for efficient model scaling. First, we propose the Fixed-frame Modality Gap Theory, which decomposes the modality gap within a frozen reference frame into stable biases and anisotropic residuals. Guided by this precise modeling, we introduce ReAlign, a training-free modality alignment strategy. Utilizing statistics from massive unpaired data, ReAlign aligns text representation into the image representation distribution via a three-step process comprising Anchor, Trace, and Centroid Alignment, thereby explicitly rectifying geometric misalignment. Building on ReAlign, we propose ReVision, a scalable training paradigm for Multimodal Large Language Models (MLLMs). ReVision integrates ReAlign into the pretraining stage, enabling the model to learn the distribution of visual representations from unpaired text before visual instruction tuning, without the need for large-scale, high-quality image-text pairs. Our framework demonstrates that statistically aligned unpaired data can effectively substitute for expensive image-text pairs, offering a robust path for the efficient scaling of MLLMs.
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Jan 11, 2026In real-world video question answering scenarios, videos often provide only localized visual cues, while verifiable answers are distributed across the open web; models therefore need to jointly perform cross-frame clue extraction, iterative retrieval, and multi-hop reasoning-based verification. To bridge this gap, we construct the first video deep research benchmark, VideoDR. VideoDR centers on video-conditioned open-domain video question answering, requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over joint video-web evidence; through rigorous human annotation and quality control, we obtain high-quality video deep research samples spanning six semantic domains. We evaluate multiple closed-source and open-source multimodal large language models under both the Workflow and Agentic paradigms, and the results show that Agentic is not consistently superior to Workflow: its gains depend on a model's ability to maintain the initial video anchors over long retrieval chains. Further analysis indicates that goal drift and long-horizon consistency are the core bottlenecks. In sum, VideoDR provides a systematic benchmark for studying video agents in open-web settings and reveals the key challenges for next-generation video deep research agents.
SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning
May 18, 2025



Despite impressive advancements in Visual-Language Models (VLMs) for multi-modal tasks, their reliance on RGB inputs limits precise spatial understanding. Existing methods for integrating spatial cues, such as point clouds or depth, either require specialized sensors or fail to effectively exploit depth information for higher-order reasoning. To this end, we propose a novel Spatial Sense and Reasoning method, dubbed SSR, a novel framework that transforms raw depth data into structured, interpretable textual rationales. These textual rationales serve as meaningful intermediate representations to significantly enhance spatial reasoning capabilities. Additionally, we leverage knowledge distillation to compress the generated rationales into compact latent embeddings, which facilitate resource-efficient and plug-and-play integration into existing VLMs without retraining. To enable comprehensive evaluation, we introduce a new dataset named SSR-CoT, a million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations, and present SSRBench, a comprehensive multi-task benchmark. Extensive experiments on multiple benchmarks demonstrate SSR substantially improves depth utilization and enhances spatial reasoning, thereby advancing VLMs toward more human-like multi-modal understanding. Our project page is at https://yliu-cs.github.io/SSR.
Unicorn: Text-Only Data Synthesis for Vision Language Model Training
Mar 28, 2025Training vision-language models (VLMs) typically requires large-scale, high-quality image-text pairs, but collecting or synthesizing such data is costly. In contrast, text data is abundant and inexpensive, prompting the question: can high-quality multimodal training data be synthesized purely from text? To tackle this, we propose a cross-integrated three-stage multimodal data synthesis framework, which generates two datasets: Unicorn-1.2M and Unicorn-471K-Instruction. In Stage 1: Diverse Caption Data Synthesis, we construct 1.2M semantically diverse high-quality captions by expanding sparse caption seeds using large language models (LLMs). In Stage 2: Instruction-Tuning Data Generation, we further process 471K captions into multi-turn instruction-tuning tasks to support complex reasoning. Finally, in Stage 3: Modality Representation Transfer, these textual captions representations are transformed into visual representations, resulting in diverse synthetic image representations. This three-stage process enables us to construct Unicorn-1.2M for pretraining and Unicorn-471K-Instruction for instruction-tuning, without relying on real images. By eliminating the dependency on real images while maintaining data quality and diversity, our framework offers a cost-effective and scalable solution for VLMs training. Code is available at https://github.com/Yu-xm/Unicorn.git.
CubeRobot: Grounding Language in Rubik's Cube Manipulation via Vision-Language Model
Mar 25, 2025



Proving Rubik's Cube theorems at the high level represents a notable milestone in human-level spatial imagination and logic thinking and reasoning. Traditional Rubik's Cube robots, relying on complex vision systems and fixed algorithms, often struggle to adapt to complex and dynamic scenarios. To overcome this limitation, we introduce CubeRobot, a novel vision-language model (VLM) tailored for solving 3x3 Rubik's Cubes, empowering embodied agents with multimodal understanding and execution capabilities. We used the CubeCoT image dataset, which contains multiple-level tasks (43 subtasks in total) that humans are unable to handle, encompassing various cube states. We incorporate a dual-loop VisionCoT architecture and Memory Stream, a paradigm for extracting task-related features from VLM-generated planning queries, thus enabling CubeRobot to independent planning, decision-making, reflection and separate management of high- and low-level Rubik's Cube tasks. Furthermore, in low-level Rubik's Cube restoration tasks, CubeRobot achieved a high accuracy rate of 100%, similar to 100% in medium-level tasks, and achieved an accuracy rate of 80% in high-level tasks.
Fake Artificial Intelligence Generated Contents (FAIGC): A Survey of Theories, Detection Methods, and Opportunities
Apr 25, 2024



In recent years, generative artificial intelligence models, represented by Large Language Models (LLMs) and Diffusion Models (DMs), have revolutionized content production methods. These artificial intelligence-generated content (AIGC) have become deeply embedded in various aspects of daily life and work, spanning texts, images, videos, and audio. The authenticity of AI-generated content is progressively enhancing, approaching human-level creative standards. However, these technologies have also led to the emergence of Fake Artificial Intelligence Generated Content (FAIGC), posing new challenges in distinguishing genuine information. It is crucial to recognize that AIGC technology is akin to a double-edged sword; its potent generative capabilities, while beneficial, also pose risks for the creation and dissemination of FAIGC. In this survey, We propose a new taxonomy that provides a more comprehensive breakdown of the space of FAIGC methods today. Next, we explore the modalities and generative technologies of FAIGC, categorized under AI-generated disinformation and AI-generated misinformation. From various perspectives, we then introduce FAIGC detection methods, including Deceptive FAIGC Detection, Deepfake Detection, and Hallucination-based FAIGC Detection. Finally, we discuss outstanding challenges and promising areas for future research.
ArcSin: Adaptive ranged cosine Similarity injected noise for Language-Driven Visual Tasks
Feb 27, 2024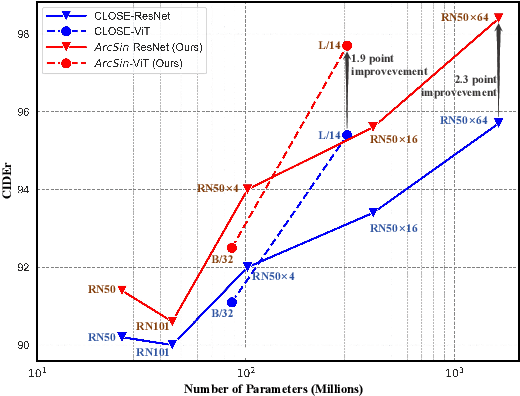
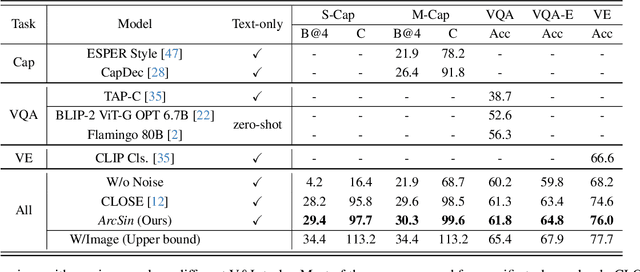
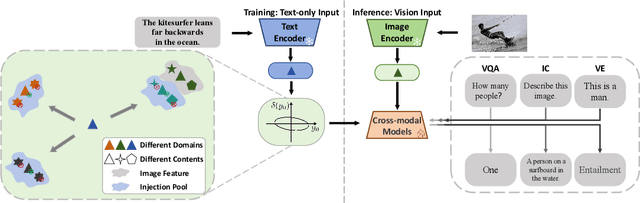

In this study, we address the challenging task of bridging the modality gap between learning from language and inference for visual tasks, including Visual Question Answering (VQA), Image Captioning (IC) and Visual Entailment (VE). We train models for these tasks in a zero-shot cross-modal transfer setting, a domain where the previous state-of-the-art method relied on the fixed scale noise injection, often compromising the semantic content of the original modality embedding. To combat it, we propose a novel method called Adaptive ranged cosine Similarity injected noise (ArcSin). First, we introduce an innovative adaptive noise scale that effectively generates the textual elements with more variability while preserving the original text feature's integrity. Second, a similarity pool strategy is employed, expanding the domain generalization potential by broadening the overall noise scale. This dual strategy effectively widens the scope of the original domain while safeguarding content integrity. Our empirical results demonstrate that these models closely rival those trained on images in terms of performance. Specifically, our method exhibits substantial improvements over the previous state-of-the-art, achieving gains of 1.9 and 1.1 CIDEr points in S-Cap and M-Cap, respectively. Additionally, we observe increases of 1.5 percentage points (pp), 1.4 pp, and 1.4 pp in accuracy for VQA, VQA-E, and VE, respectively, pushing the boundaries of what is achievable within the constraints of image-trained model benchmarks. The code will be released.