 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcSin: Adaptive ranged cosine Similarity injected noise for Language-Driven Visual Tasks
Paper and Code
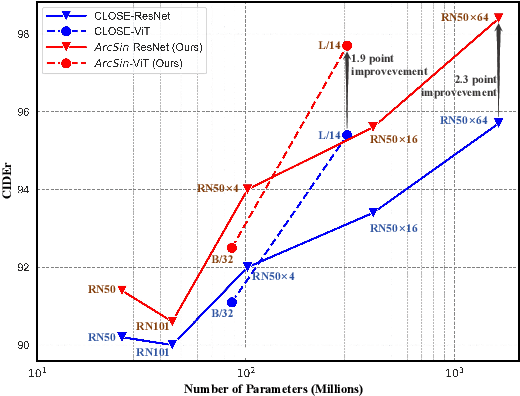
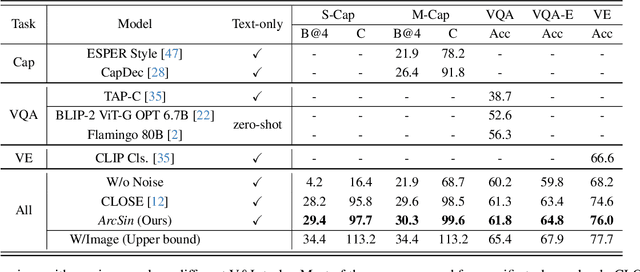
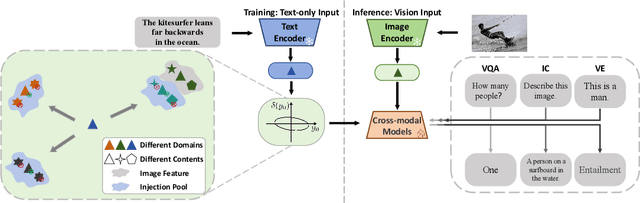

In this study, we address the challenging task of bridging the modality gap between learning from language and inference for visual tasks, including Visual Question Answering (VQA), Image Captioning (IC) and Visual Entailment (VE). We train models for these tasks in a zero-shot cross-modal transfer setting, a domain where the previous state-of-the-art method relied on the fixed scale noise injection, often compromising the semantic content of the original modality embedding. To combat it, we propose a novel method called Adaptive ranged cosine Similarity injected noise (ArcSin). First, we introduce an innovative adaptive noise scale that effectively generates the textual elements with more variability while preserving the original text feature's integrity. Second, a similarity pool strategy is employed, expanding the domain generalization potential by broadening the overall noise scale. This dual strategy effectively widens the scope of the original domain while safeguarding content integrity. Our empirical results demonstrate that these models closely rival those trained on images in terms of performance. Specifically, our method exhibits substantial improvements over the previous state-of-the-art, achieving gains of 1.9 and 1.1 CIDEr points in S-Cap and M-Cap, respectively. Additionally, we observe increases of 1.5 percentage points (pp), 1.4 pp, and 1.4 pp in accuracy for VQA, VQA-E, and VE, respectively, pushing the boundaries of what is achievable within the constraints of image-trained model benchmarks. The code will be released.