 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetiGen: A Framework for Generalized Retinal Diagnosis Using Multi-View Fundus Images
Mar 22, 2024



This study introduces a novel framework for enhancing domain generalization in medical imaging, specifically focusing on utilizing unlabelled multi-view colour fundus photographs. Unlike traditional approaches that rely on single-view imaging data and face challenges in generalizing across diverse clinical settings, our method leverages the rich information in the unlabelled multi-view imaging data to improve model robustness and accuracy. By incorporating a class balancing method, a test-time adaptation technique and a multi-view optimization strategy, we address the critical issue of domain shift that often hampers the performance of machine learning models in real-world applications. Experiments comparing various state-of-the-art domain generalization and test-time optimization methodologies show that our approach consistently outperforms when combined with existing baseline and state-of-the-art methods. We also show our online method improves all existing techniques. Our framework demonstrates improvements in domain generalization capabilities and offers a practical solution for real-world deployment by facilitating online adaptation to new, unseen datasets. Our code is available at https://github.com/zgy600/RetiGen .
Rethinking Low-quality Optical Flow in Unsupervised Surgical Instrument Segmentation
Mar 15, 2024
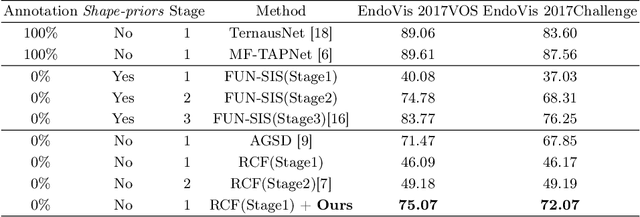
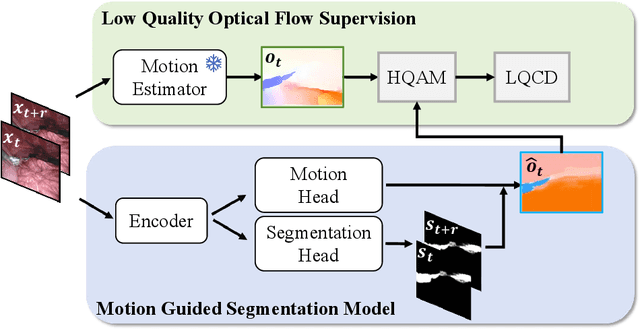
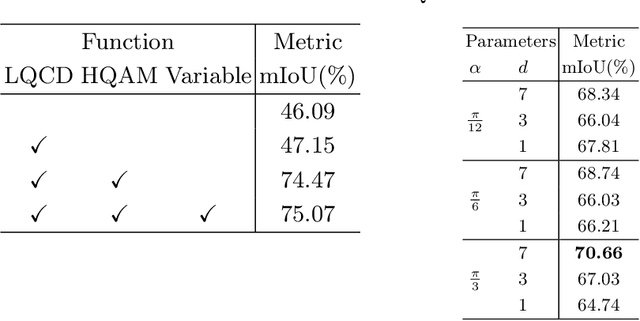
Video-based surgical instrument segmentation plays an important role in robot-assisted surgeries. Unlike supervised settings, unsupervised segmentation relies heavily on motion cues, which are challenging to discern due to the typically lower quality of optical flow in surgical footage compared to natural scenes. This presents a considerable burden for the advancement of unsupervised segmentation techniques. In our work, we address the challenge of enhancing model performance despite the inherent limitations of low-quality optical flow. Our methodology employs a three-pronged approach: extracting boundaries directly from the optical flow, selectively discarding frames with inferior flow quality, and employing a fine-tuning process with variable frame rates. We thoroughly evaluate our strategy on the EndoVis2017 VOS dataset and Endovis2017 Challenge dataset, where our model demonstrates promising results, achieving a mean Intersection-over-Union (mIoU) of 0.75 and 0.72, respectively. Our findings suggest that our approach can greatly decrease the need for manual annotations in clinical environments and may facilitate the annotation process for new datasets. The code is available at https://github.com/wpr1018001/Rethinking-Low-quality-Optical-Flow.git
ArcSin: Adaptive ranged cosine Similarity injected noise for Language-Driven Visual Tasks
Feb 27, 2024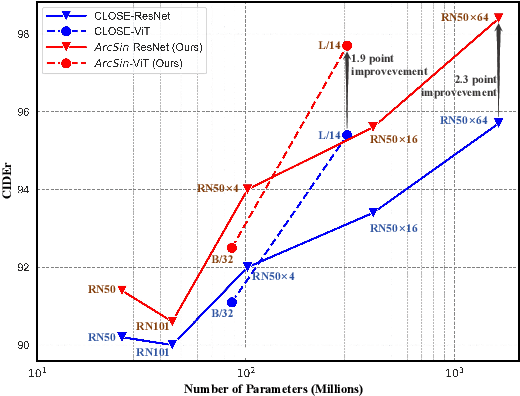
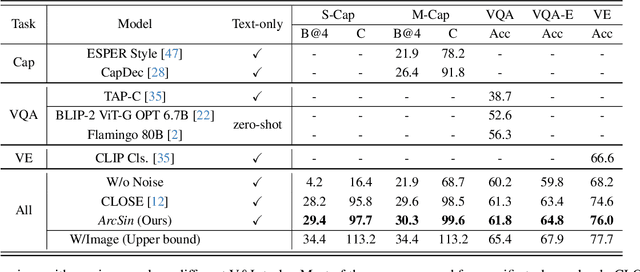
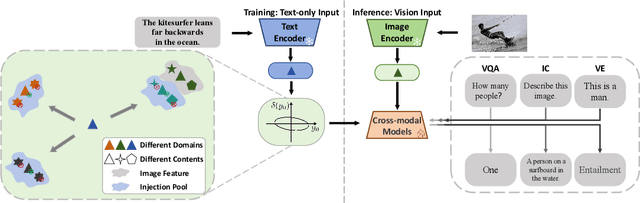

In this study, we address the challenging task of bridging the modality gap between learning from language and inference for visual tasks, including Visual Question Answering (VQA), Image Captioning (IC) and Visual Entailment (VE). We train models for these tasks in a zero-shot cross-modal transfer setting, a domain where the previous state-of-the-art method relied on the fixed scale noise injection, often compromising the semantic content of the original modality embedding. To combat it, we propose a novel method called Adaptive ranged cosine Similarity injected noise (ArcSin). First, we introduce an innovative adaptive noise scale that effectively generates the textual elements with more variability while preserving the original text feature's integrity. Second, a similarity pool strategy is employed, expanding the domain generalization potential by broadening the overall noise scale. This dual strategy effectively widens the scope of the original domain while safeguarding content integrity. Our empirical results demonstrate that these models closely rival those trained on images in terms of performance. Specifically, our method exhibits substantial improvements over the previous state-of-the-art, achieving gains of 1.9 and 1.1 CIDEr points in S-Cap and M-Cap, respectively. Additionally, we observe increases of 1.5 percentage points (pp), 1.4 pp, and 1.4 pp in accuracy for VQA, VQA-E, and VE, respectively, pushing the boundaries of what is achievable within the constraints of image-trained model benchmarks. The code will be released.