 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraFlwr -- An Efficient Federated Medical and Surgical Object Detection Framework
Mar 19, 2025Object detection shows promise for medical and surgical applications such as cell counting and tool tracking. However, its faces multiple real-world edge deployment challenges including limited high-quality annotated data, data sharing restrictions, and computational constraints. In this work, we introduce UltraFlwr, a framework for federated medical and surgical object detection. By leveraging Federated Learning (FL), UltraFlwr enables decentralized model training across multiple sites without sharing raw data. To further enhance UltraFlwr's efficiency, we propose YOLO-PA, a set of novel Partial Aggregation (PA) strategies specifically designed for YOLO models in FL. YOLO-PA significantly reduces communication overhead by up to 83% per round while maintaining performance comparable to Full Aggregation (FA) strategies. Our extensive experiments on BCCD and m2cai16-tool-locations datasets demonstrate that YOLO-PA not only provides better client models compared to client-wise centralized training and FA strategies, but also facilitates efficient training and deployment across resource-constrained edge devices. Further, we also establish one of the first benchmarks in federated medical and surgical object detection. This paper advances the feasibility of training and deploying detection models on the edge, making federated object detection more practical for time-critical and resource-constrained medical and surgical applications. UltraFlwr is publicly available at https://github.com/KCL-BMEIS/UltraFlwr.
SWAG: Long-term Surgical Workflow Prediction with Generative-based Anticipation
Dec 25, 2024
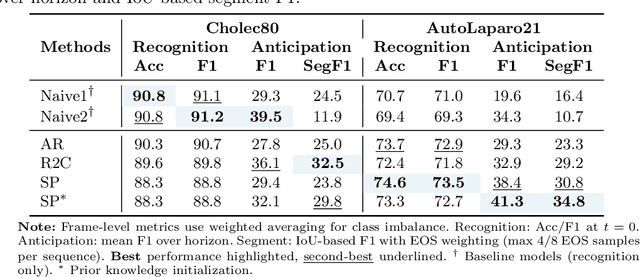
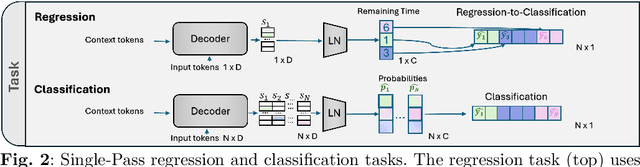
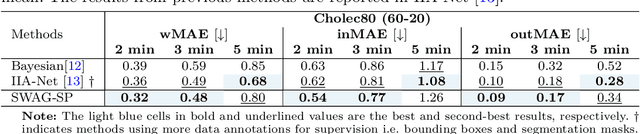
While existing recognition approaches excel at identifying current surgical phases, they provide limited foresight into future procedural steps, restricting their intraoperative utility. Similarly, current anticipation methods are constrained to predicting short-term events or singular future occurrences, neglecting the dynamic and sequential nature of surgical workflows. To address these limitations, we propose SWAG (Surgical Workflow Anticipative Generation), a unified framework for phase recognition and long-term anticipation of surgical workflows. SWAG employs two generative decoding methods -- single-pass (SP) and auto-regressive (AR) -- to predict sequences of future surgical phases. A novel prior knowledge embedding mechanism enhances the accuracy of anticipatory predictions. The framework addresses future phase classification and remaining time regression tasks. Additionally, a regression-to-classification (R2C) method is introduced to map continuous predictions to discrete temporal segments. SWAG's performance was evaluated on the Cholec80 and AutoLaparo21 datasets. The single-pass classification model with prior knowledge embeddings (SWAG-SP\*) achieved 53.5\% accuracy in 15-minute anticipation on AutoLaparo21, while the R2C model reached 60.8\% accuracy on Cholec80. SWAG's single-pass regression approach outperformed existing methods for remaining time prediction, achieving weighted mean absolute errors of 0.32 and 0.48 minutes for 2- and 3-minute horizons, respectively. SWAG demonstrates versatility across classification and regression tasks, offering robust tools for real-time surgical workflow anticipation. By unifying recognition and anticipatory capabilities, SWAG provides actionable predictions to enhance intraoperative decision-making.
DDSB: An Unsupervised and Training-free Method for Phase Detection in Echocardiography
Mar 19, 2024



Accurate identification of End-Diastolic (ED) and End-Systolic (ES) frames is key for cardiac function assessment through echocardiography. However, traditional methods face several limitations: they require extensive amounts of data, extensive annotations by medical experts, significant training resources, and often lack robustness. Addressing these challenges, we proposed an unsupervised and training-free method, our novel approach leverages unsupervised segmentation to enhance fault tolerance against segmentation inaccuracies. By identifying anchor points and analyzing directional deformation, we effectively reduce dependence on the accuracy of initial segmentation images and enhance fault tolerance, all while improving robustness. Tested on Echo-dynamic and CAMUS datasets, our method achieves comparable accuracy to learning-based models without their associated drawbacks. The code is available at https://github.com/MRUIL/DDSB
Rethinking Low-quality Optical Flow in Unsupervised Surgical Instrument Segmentation
Mar 15, 2024
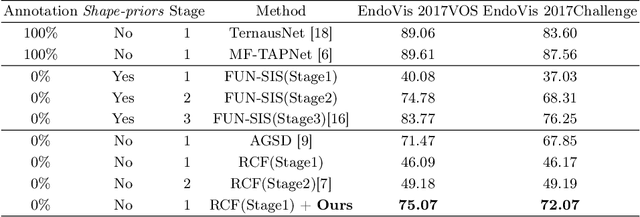
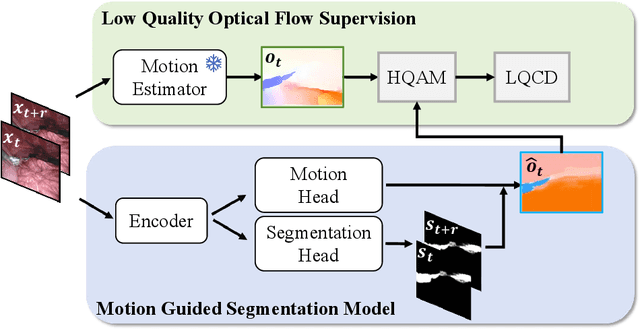
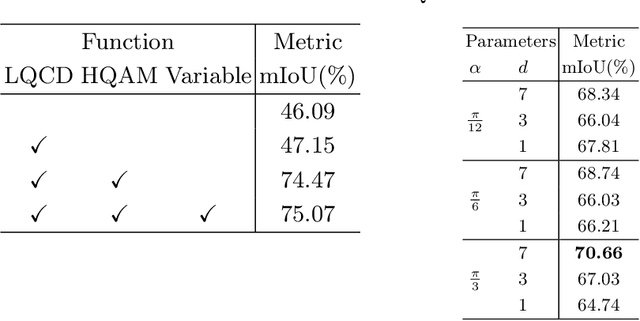
Video-based surgical instrument segmentation plays an important role in robot-assisted surgeries. Unlike supervised settings, unsupervised segmentation relies heavily on motion cues, which are challenging to discern due to the typically lower quality of optical flow in surgical footage compared to natural scenes. This presents a considerable burden for the advancement of unsupervised segmentation techniques. In our work, we address the challenge of enhancing model performance despite the inherent limitations of low-quality optical flow. Our methodology employs a three-pronged approach: extracting boundaries directly from the optical flow, selectively discarding frames with inferior flow quality, and employing a fine-tuning process with variable frame rates. We thoroughly evaluate our strategy on the EndoVis2017 VOS dataset and Endovis2017 Challenge dataset, where our model demonstrates promising results, achieving a mean Intersection-over-Union (mIoU) of 0.75 and 0.72, respectively. Our findings suggest that our approach can greatly decrease the need for manual annotations in clinical environments and may facilitate the annotation process for new datasets. The code is available at https://github.com/wpr1018001/Rethinking-Low-quality-Optical-Flow.git
SuPRA: Surgical Phase Recognition and Anticipation for Intra-Operative Planning
Mar 10, 2024



Intra-operative recognition of surgical phases holds significant potential for enhancing real-time contextual awareness in the operating room. However, we argue that online recognition, while beneficial, primarily lends itself to post-operative video analysis due to its limited direct impact on the actual surgical decisions and actions during ongoing procedures. In contrast, we contend that the prediction and anticipation of surgical phases are inherently more valuable for intra-operative assistance, as they can meaningfully influence a surgeon's immediate and long-term planning by providing foresight into future steps. To address this gap, we propose a dual approach that simultaneously recognises the current surgical phase and predicts upcoming ones, thus offering comprehensive intra-operative assistance and guidance on the expected remaining workflow. Our novel method, Surgical Phase Recognition and Anticipation (SuPRA), leverages past and current information for accurate intra-operative phase recognition while using future segments for phase prediction. This unified approach challenges conventional frameworks that treat these objectives separately. We have validated SuPRA on two reputed datasets, Cholec80 and AutoLaparo21, where it demonstrated state-of-the-art performance with recognition accuracies of 91.8% and 79.3%, respectively. Additionally, we introduce and evaluate our model using new segment-level evaluation metrics, namely Edit and F1 Overlap scores, for a more temporal assessment of segment classification. In conclusion, SuPRA presents a new multi-task approach that paves the way for improved intra-operative assistance through surgical phase recognition and prediction of future events.
ArcSin: Adaptive ranged cosine Similarity injected noise for Language-Driven Visual Tasks
Feb 27, 2024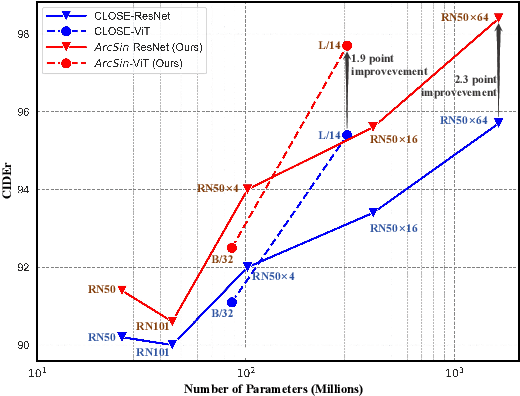
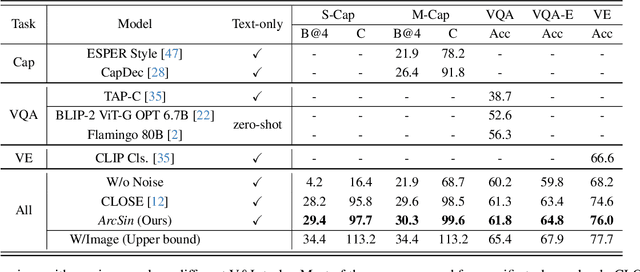
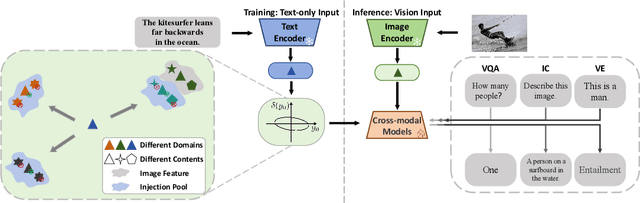

In this study, we address the challenging task of bridging the modality gap between learning from language and inference for visual tasks, including Visual Question Answering (VQA), Image Captioning (IC) and Visual Entailment (VE). We train models for these tasks in a zero-shot cross-modal transfer setting, a domain where the previous state-of-the-art method relied on the fixed scale noise injection, often compromising the semantic content of the original modality embedding. To combat it, we propose a novel method called Adaptive ranged cosine Similarity injected noise (ArcSin). First, we introduce an innovative adaptive noise scale that effectively generates the textual elements with more variability while preserving the original text feature's integrity. Second, a similarity pool strategy is employed, expanding the domain generalization potential by broadening the overall noise scale. This dual strategy effectively widens the scope of the original domain while safeguarding content integrity. Our empirical results demonstrate that these models closely rival those trained on images in terms of performance. Specifically, our method exhibits substantial improvements over the previous state-of-the-art, achieving gains of 1.9 and 1.1 CIDEr points in S-Cap and M-Cap, respectively. Additionally, we observe increases of 1.5 percentage points (pp), 1.4 pp, and 1.4 pp in accuracy for VQA, VQA-E, and VE, respectively, pushing the boundaries of what is achievable within the constraints of image-trained model benchmarks. The code will be released.
SAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023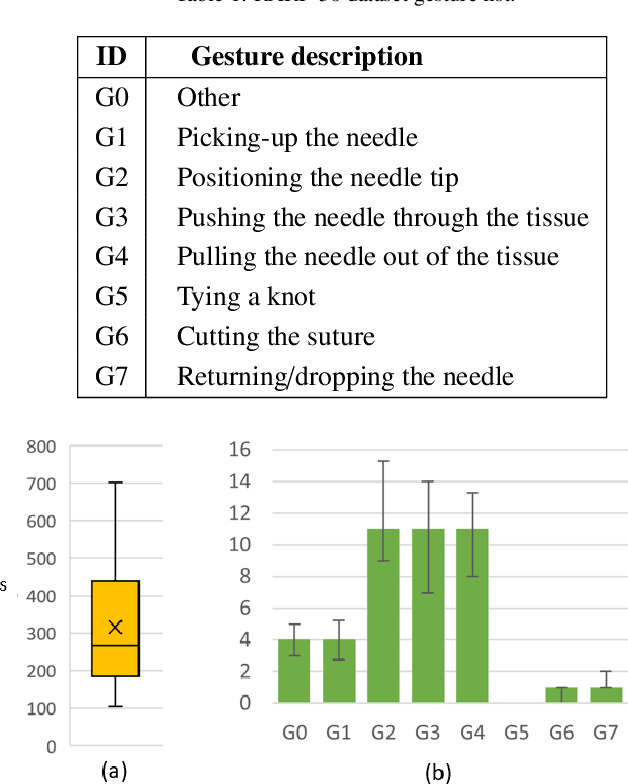
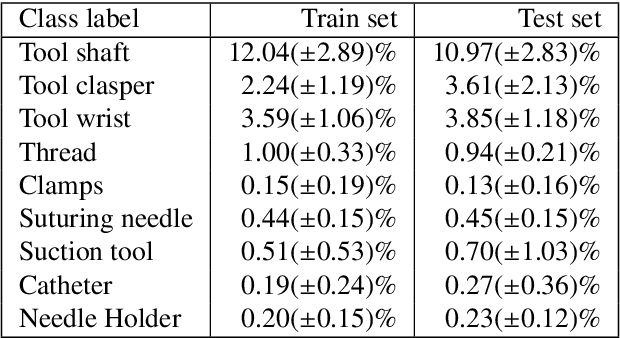
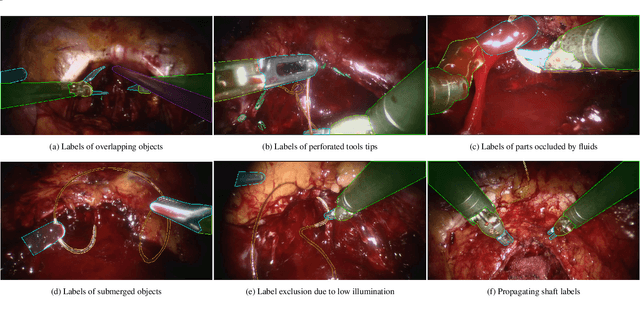
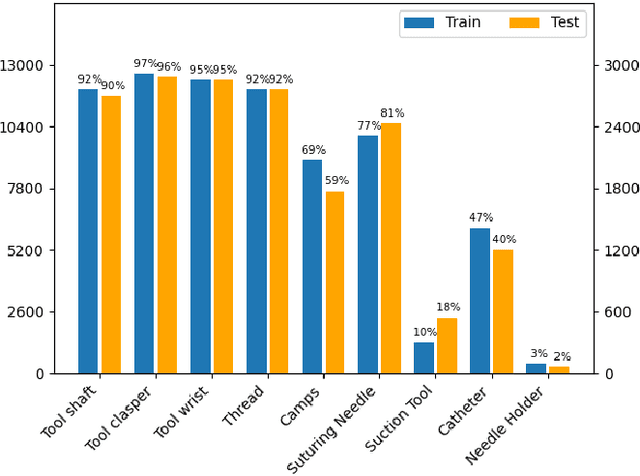
Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
LoViT: Long Video Transformer for Surgical Phase Recognition
May 18, 2023



Online surgical phase recognition plays a significant role towards building contextual tools that could quantify performance and oversee the execution of surgical workflows. Current approaches are limited since they train spatial feature extractors using frame-level supervision that could lead to incorrect predictions due to similar frames appearing at different phases, and poorly fuse local and global features due to computational constraints which can affect the analysis of long videos commonly encountered in surgical interventions. In this paper, we present a two-stage method, called Long Video Transformer (LoViT) for fusing short- and long-term temporal information that combines a temporally-rich spatial feature extractor and a multi-scale temporal aggregator consisting of two cascaded L-Trans modules based on self-attention, followed by a G-Informer module based on ProbSparse self-attention for processing global temporal information. The multi-scale temporal head then combines local and global features and classifies surgical phases using phase transition-aware supervision. Our approach outperforms state-of-the-art methods on the Cholec80 and AutoLaparo datasets consistently. Compared to Trans-SVNet, LoViT achieves a 2.39 pp (percentage point) improvement in video-level accuracy on Cholec80 and a 3.14 pp improvement on AutoLaparo. Moreover, it achieves a 5.25 pp improvement in phase-level Jaccard on AutoLaparo and a 1.55 pp improvement on Cholec80. Our results demonstrate the effectiveness of our approach in achieving state-of-the-art performance of surgical phase recognition on two datasets of different surgical procedures and temporal sequencing characteristics whilst introducing mechanisms that cope with long videos.