 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRDE: Retrieval-Augmented Large Language Models for Chinese Health Rumor Detection and Explainability
Jun 30, 2024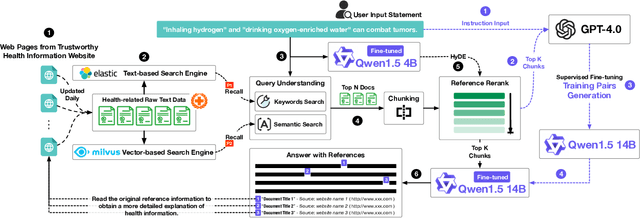

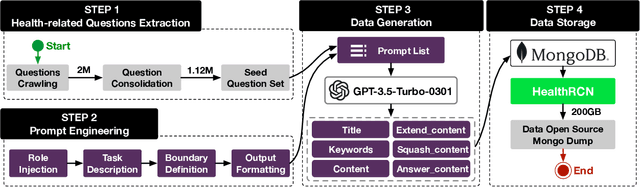

As people increasingly prioritize their health, the speed and breadth of health information dissemination on the internet have also grown. At the same time, the presence of false health information (health rumors) intermingled with genuine content poses a significant potential threat to public health. However, current research on Chinese health rumors still lacks a large-scale, public, and open-source dataset of health rumor information, as well as effective and reliable rumor detection methods. This paper addresses this gap by constructing a dataset containing 1.12 million health-related rumors (HealthRCN) through web scraping of common health-related questions and a series of data processing steps. HealthRCN is the largest known dataset of Chinese health information rumors to date. Based on this dataset, we propose retrieval-augmented large language models for Chinese health rumor detection and explainability (HRDE). This model leverages retrieved relevant information to accurately determine whether the input health information is a rumor and provides explanatory responses, effectively aiding users in verifying the authenticity of health information. In evaluation experiments, we compared multiple models and found that HRDE outperformed them all, including GPT-4-1106-Preview, in rumor detection accuracy and answer quality. HRDE achieved an average accuracy of 91.04% and an F1 score of 91.58%.
Fake Artificial Intelligence Generated Contents (FAIGC): A Survey of Theories, Detection Methods, and Opportunities
Apr 25, 2024



In recent years, generative artificial intelligence models, represented by Large Language Models (LLMs) and Diffusion Models (DMs), have revolutionized content production methods. These artificial intelligence-generated content (AIGC) have become deeply embedded in various aspects of daily life and work, spanning texts, images, videos, and audio. The authenticity of AI-generated content is progressively enhancing, approaching human-level creative standards. However, these technologies have also led to the emergence of Fake Artificial Intelligence Generated Content (FAIGC), posing new challenges in distinguishing genuine information. It is crucial to recognize that AIGC technology is akin to a double-edged sword; its potent generative capabilities, while beneficial, also pose risks for the creation and dissemination of FAIGC. In this survey, We propose a new taxonomy that provides a more comprehensive breakdown of the space of FAIGC methods today. Next, we explore the modalities and generative technologies of FAIGC, categorized under AI-generated disinformation and AI-generated misinformation. From various perspectives, we then introduce FAIGC detection methods, including Deceptive FAIGC Detection, Deepfake Detection, and Hallucination-based FAIGC Detection. Finally, we discuss outstanding challenges and promising areas for future research.
BookGPT: A General Framework for Book Recommendation Empowered by Large Language Model
May 25, 2023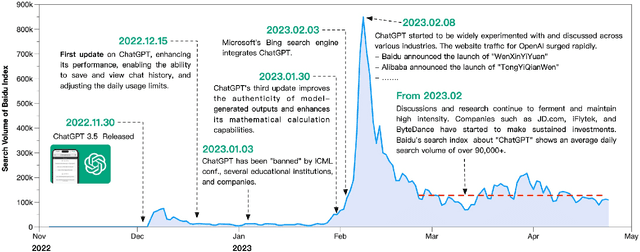

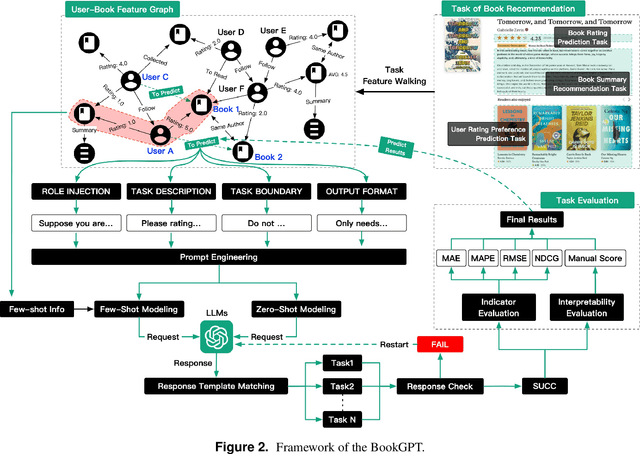
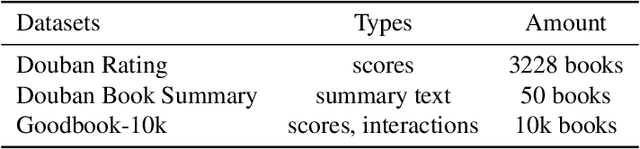
With the continuous development and change exhibited by large language model (LLM) technology, represented by generative pretrained transformers (GPTs), many classic scenarios in various fields have re-emerged with new opportunities. This paper takes ChatGPT as the modeling object, incorporates LLM technology into the typical book resource understanding and recommendation scenario for the first time, and puts it into practice. By building a ChatGPT-like book recommendation system (BookGPT) framework based on ChatGPT, this paper attempts to apply ChatGPT to recommendation modeling for three typical tasks, book rating recommendation, user rating recommendation, and book summary recommendation, and explores the feasibility of LLM technology in book recommendation scenarios. At the same time, based on different evaluation schemes for book recommendation tasks and the existing classic recommendation models, this paper discusses the advantages and disadvantages of the BookGPT in book recommendation scenarios and analyzes the opportunities and improvement directions for subsequent LLMs in these scenarios.