 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTII-Bench: A Comprehensive Multimodal Benchmark for Flow Text with Image Insertion
Oct 16, 2024



Benefiting from the revolutionary advances in large language models (LLMs) and foundational vision models, large vision-language models (LVLMs) have also made significant progress. However, current benchmarks focus on tasks that evaluating only a single aspect of LVLM capabilities (e.g., recognition, detection, understanding). These tasks fail to fully demonstrate LVLMs' potential in complex application scenarios. To comprehensively assess the performance of existing LVLMs, we propose a more challenging task called the Flow Text with Image Insertion task (FTII). This task requires LVLMs to simultaneously possess outstanding abilities in image comprehension, instruction understanding, and long-text interpretation. Specifically, given several text paragraphs and a set of candidate images, as the text paragraphs accumulate, the LVLMs are required to select the most suitable image from the candidates to insert after the corresponding paragraph. Constructing a benchmark for such a task is highly challenging, particularly in determining the sequence of flowing text and images. To address this challenge, we turn to professional news reports, which naturally contain a gold standard for image-text sequences. Based on this, we introduce the Flow Text with Image Insertion Benchmark (FTII-Bench), which includes 318 high-quality Chinese image-text news articles and 307 high-quality English image-text news articles, covering 10 different news domains. Using these 625 high-quality articles, we construct problems of two different types with multiple levels of difficulty. Furthermore, we establish two different evaluation pipelines based on the CLIP model and existing LVLMs. We evaluate 9 open-source and 2 closed-source LVLMs as well as 2 CLIP-based models. Results indicate that even the most advanced models (e.g., GPT-4o) face significant challenges when tackling the FTII task.
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
HRDE: Retrieval-Augmented Large Language Models for Chinese Health Rumor Detection and Explainability
Jun 30, 2024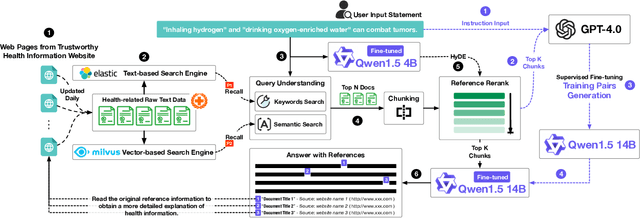

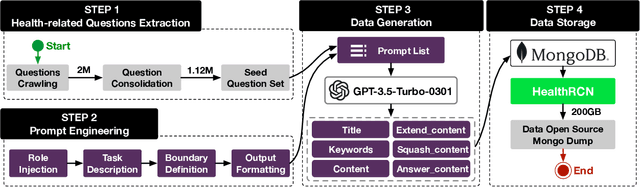

As people increasingly prioritize their health, the speed and breadth of health information dissemination on the internet have also grown. At the same time, the presence of false health information (health rumors) intermingled with genuine content poses a significant potential threat to public health. However, current research on Chinese health rumors still lacks a large-scale, public, and open-source dataset of health rumor information, as well as effective and reliable rumor detection methods. This paper addresses this gap by constructing a dataset containing 1.12 million health-related rumors (HealthRCN) through web scraping of common health-related questions and a series of data processing steps. HealthRCN is the largest known dataset of Chinese health information rumors to date. Based on this dataset, we propose retrieval-augmented large language models for Chinese health rumor detection and explainability (HRDE). This model leverages retrieved relevant information to accurately determine whether the input health information is a rumor and provides explanatory responses, effectively aiding users in verifying the authenticity of health information. In evaluation experiments, we compared multiple models and found that HRDE outperformed them all, including GPT-4-1106-Preview, in rumor detection accuracy and answer quality. HRDE achieved an average accuracy of 91.04% and an F1 score of 91.58%.
Multi-hop Reading Comprehension across Documents with Path-based Graph Convolutional Network
Jun 12, 2020
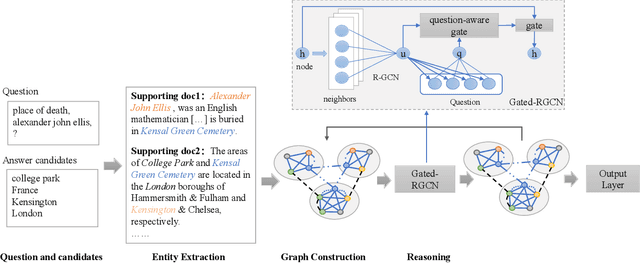

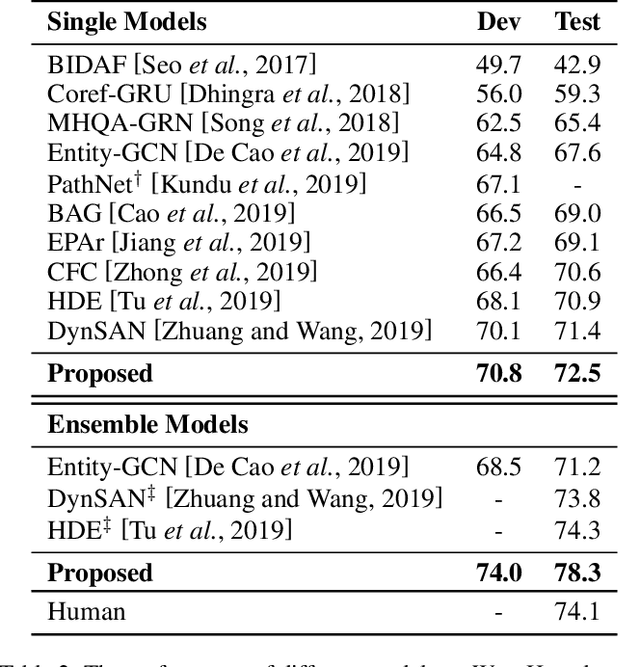
Multi-hop reading comprehension across multiple documents attracts much attention recently. In this paper, we propose a novel approach to tackle this multi-hop reading comprehension problem. Inspired by human reasoning processing, we construct a path-based reasoning graph from supporting documents. This graph can combine both the idea of the graph-based and path-based approaches, so it is better for multi-hop reasoning. Meanwhile, we propose Gated-RGCN to accumulate evidence on the path-based reasoning graph, which contains a new question-aware gating mechanism to regulate the usefulness of information propagating across documents and add question information during reasoning. We evaluate our approach on WikiHop dataset, and our approach achieves state-of-the-art accuracy against previously published approaches. Especially, our ensemble model surpasses human performance by 4.2%.