 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multi-Satellite Cooperative Transmission: A Joint Framework for CSI Acquisition, Feedback, and Phase Synchronization
Mar 30, 2026The stringent link budget, caused by long propagation distances and payload constraints, poses a fundamental bottleneck for single-satellite transmission. Although LEO mega-constellations make multi-satellite cooperative transmission (MSCT), such as distributed precoding (DP), increasingly feasible, its cooperative gains critically rely on stringent time-frequency-phase synchronization (TFP-Sync), which is difficult to maintain under rapid channel variation and feedback latency. To address this issue, this paper proposes a joint CSI acquisition, feedback, and phase-level synchronization (JCAFPS) framework for MSCT. Specifically, to enable reliable, overhead-efficient CSI acquisition, we design a beam-domain adjustable phase-shift tracking reference signal (TRS) transmission scheme, along with criteria for the TRS and CSI-feedback periods. Then, exploiting deterministic orbital motion and dominant LoS propagation, we establish a polynomial model for the temporal evolution of delay and Doppler shift, and derive an OFDM-based multi-satellite signal model under non-ideal synchronization. The analysis reveals that, unlike the single-satellite case, the composite multi-satellite channel exhibits nonlinear time-frequency-varying phase behavior, necessitating symbol- and subcarrier-wise phase precompensation for coherent transmission. Based on these results, we develop a practical closed-loop realization integrating single-TRS-based channel parameter estimation, multi-TRS-based channel prediction, predictive CSI feedback, and user-specific TFP precompensation. Numerical results demonstrate that the proposed framework achieves accurate CSI acquisition and precise TFP-Sync, enabling DP-based dual-satellite cooperative transmission to approach the theoretical 6 dB power gain over single-satellite transmission, while remaining robust under extended prediction durations and enlarged TRS periods.
Deep Learning-Based Multi-Satellite Massive MIMO Transmission: Centralized or Decentralized?
Mar 21, 2026This paper investigates new efficient transmission architectures for multi-satellite massive multiple-input multiple-output (MIMO). We study the weighted sum-rate maximization problem in a multi-satellite system where multiple satellites transmit independent data streams to multi-antenna user terminals, thereby achieving higher throughput. We first adopt a multi-satellite weighted minimum mean square error (WMMSE) formulation under statistical channel state information (CSI), which yields closed-form updates for the precoding and receive vectors. To overcome the high complexity of optimization, we propose a learning-based WMMSE design that integrates tensor equivariance with closed-form recovery, enabling inference with near-optimal performance without iterative updates. Moreover, to reduce inter-satellite signaling overhead incurred by exchanging CSI and precoding vectors in centralized coordination, we develop a decentralized multi-satellite transmission scheme in which each satellite locally infers its precoders rather than receiving from the central satellite. The proposed decentralized scheme leverages periodically available satellite state information, such as orbital positions and satellite attitude, which is inherently accessible in satellite networks, and employs a dual-branch tensor-equivariant network to predict the precoders at each satellite locally. Numerical results demonstrate that the proposed multi-satellite transmission significantly outperforms single-satellite systems in sum rate; the decentralized scheme achieves sum-rate performance close to the centralized schemes while substantially reducing computational complexity and inter-satellite overhead; and the learning-based schemes exhibit strong robustness and scalability across different scenarios.
A Channel Knowledge Map-Driven Two-Stage Coordinated User Scheduling in Multi-Cell Massive MIMO Systems
Mar 21, 2026This paper investigates narrowband coordinated user scheduling in multi-cell massive multiple-input multiple-output (MIMO) systems. We formulate the problem under a spectral-efficiency maximization criterion, revealing inherent challenges in computational complexity and signaling overhead. To address these, we develop a user-scheduling-oriented CKM (US-CKM) and a US-CKM-driven two-stage coordinated scheduling framework. By exploiting the mapping between location information and statistical channel state information (SCSI), the system enables rapid SCSI retrieval and persistent reuse, substantially reducing CSI acquisition overhead. Embedding statistical channel correlation into the CKM further characterizes interuser interference patterns. The framework designs an intra-cell active-user selection scheme for the first stage and an inter-cell coordinated scheduling scheme for the second, both based on US-CKM entries. The first stage identifies users with favorable channel gains and low intra-cell interference, reducing the candidate set with marginal sum-rate loss. The second stage suppresses inter-cell interference (ICI) by exploiting cross-cell channel correlations. To enhance robustness against imperfect SCSI in dynamic scattering environments, we augment the framework with a reliability-guided mechanism. Instead of uniform treatment, we evaluate entry stability using a grid reliability metric quantifying channel measurement variance at sampling locations. Low-reliability grids are identified, and their instantaneous CSI is acquired in real time to integrate with existing SCSI. This process refines channel gain and spatial correlation characteristics, ensuring robust performance under imperfect conditions.
Semantic Satellite Communications for Synchronized Audiovisual Reconstruction
Mar 11, 2026Satellite communications face severe bottlenecks in supporting high-fidelity synchronized audiovisual services, as conventional schemes struggle with cross-modal coherence under fluctuating channel conditions, limited bandwidth, and long propagation delays. To address these limitations, this paper proposes an adaptive multimodal semantic transmission system tailored for satellite scenarios, aiming for high-quality synchronized audiovisual reconstruction under bandwidth constraints. Unlike static schemes with fixed modal priorities, our framework features a dual-stream generative architecture that flexibly switches between video-driven audio generation and audio-driven video generation. This allows the system to dynamically decouple semantics, transmitting only the most important modality while employing cross-modal generation to recover the other. To balance reconstruction quality and transmission overhead, a dynamic keyframe update mechanism adaptively maintains the shared knowledge base according to wireless scenarios and user requirements. Furthermore, a large language model based decision module is introduced to enhance system adaptability. By integrating satellite-specific knowledge, this module jointly considers task requirements and channel factors such as weather-induced fading to proactively adjust transmission paths and generation workflows. Simulation results demonstrate that the proposed system significantly reduces bandwidth consumption while achieving high-fidelity audiovisual synchronization, improving transmission efficiency and robustness in challenging satellite scenarios.
Multi-Satellite Multi-Stream Beamspace Massive MIMO Transmission
Dec 26, 2025This paper studies multi-satellite multi-stream (MSMS) beamspace transmission, where multiple satellites cooperate to form a distributed multiple-input multiple-output (MIMO) system and jointly deliver multiple data streams to multi-antenna user terminals (UTs), and beamspace transmission combines earth-moving beamforming with beam-domain precoding. For the first time, we formulate the signal model for MSMS beamspace MIMO transmission. Under synchronization errors, multi-antenna UTs enable the distributed MIMO channel to exhibit higher rank, supporting multiple data streams. Beamspace MIMO retains conventional codebook based beamforming while providing the performance gains of precoding. Based on the signal model, we propose statistical channel state information (sCSI)-based optimization of satellite clustering, beam selection, and transmit precoding, using a sum-rate upper-bound approximation. With given satellite clustering and beam selection, we cast precoder design as an equivalent covariance decomposition-based weighted minimum mean square error (CDWMMSE) problem. To obtain tractable algorithms, we develop a closed-form covariance decomposition required by CDWMMSE and derive an iterative MSMS beam-domain precoder under sCSI. Following this, we further propose several heuristic closed-form precoders to avoid iterative cost. For satellite clustering, we enhance a competition-based algorithm by introducing a mechanism to regulate the number of satellites serving certain UT. Furthermore, we design a two-stage low-complexity beam selection algorithm focused on enhancing the effective channel power. Simulations under practical configurations validate the proposed methods across the number of data streams, receive antennas, serving satellites, and active beams, and show that beamspace transmission approaches conventional MIMO performance at lower complexity.
QoS-Aware Hierarchical Reinforcement Learning for Joint Link Selection and Trajectory Optimization in SAGIN-Supported UAV Mobility Management
Dec 17, 2025Due to the significant variations in unmanned aerial vehicle (UAV) altitude and horizontal mobility, it becomes difficult for any single network to ensure continuous and reliable threedimensional coverage. Towards that end, the space-air-ground integrated network (SAGIN) has emerged as an essential architecture for enabling ubiquitous UAV connectivity. To address the pronounced disparities in coverage and signal characteristics across heterogeneous networks, this paper formulates UAV mobility management in SAGIN as a constrained multi-objective joint optimization problem. The formulation couples discrete link selection with continuous trajectory optimization. Building on this, we propose a two-level multi-agent hierarchical deep reinforcement learning (HDRL) framework that decomposes the problem into two alternately solvable subproblems. To map complex link selection decisions into a compact discrete action space, we conceive a double deep Q-network (DDQN) algorithm in the top-level, which achieves stable and high-quality policy learning through double Q-value estimation. To handle the continuous trajectory action space while satisfying quality of service (QoS) constraints, we integrate the maximum-entropy mechanism of the soft actor-critic (SAC) and employ a Lagrangian-based constrained SAC (CSAC) algorithm in the lower-level that dynamically adjusts the Lagrange multipliers to balance constraint satisfaction and policy optimization. Moreover, the proposed algorithm can be extended to multi-UAV scenarios under the centralized training and decentralized execution (CTDE) paradigm, which enables more generalizable policies. Simulation results demonstrate that the proposed scheme substantially outperforms existing benchmarks in throughput, link switching frequency and QoS satisfaction.
Unlocking Symbol-Level Precoding Efficiency Through Tensor Equivariant Neural Network
Oct 02, 2025Although symbol-level precoding (SLP) based on constructive interference (CI) exploitation offers performance gains, its high complexity remains a bottleneck. This paper addresses this challenge with an end-to-end deep learning (DL) framework with low inference complexity that leverages the structure of the optimal SLP solution in the closed-form and its inherent tensor equivariance (TE), where TE denotes that a permutation of the input induces the corresponding permutation of the output. Building upon the computationally efficient model-based formulations, as well as their known closed-form solutions, we analyze their relationship with linear precoding (LP) and investigate the corresponding optimality condition. We then construct a mapping from the problem formulation to the solution and prove its TE, based on which the designed networks reveal a specific parameter-sharing pattern that delivers low computational complexity and strong generalization. Leveraging these, we propose the backbone of the framework with an attention-based TE module, achieving linear computational complexity. Furthermore, we demonstrate that such a framework is also applicable to imperfect CSI scenarios, where we design a TE-based network to map the CSI, statistics, and symbols to auxiliary variables. Simulation results show that the proposed framework captures substantial performance gains of optimal SLP, while achieving an approximately 80-times speedup over conventional methods and maintaining strong generalization across user numbers and symbol block lengths.
Tensor-Structured Bayesian Channel Prediction for Upper Mid-Band XL-MIMO Systems
Aug 11, 2025The upper mid-band balances coverage and capacity for the future cellular systems and also embraces XL-MIMO systems, offering enhanced spectral and energy efficiency. However, these benefits are significantly degraded under mobility due to channel aging, and further exacerbated by the unique near-field (NF) and spatial non-stationarity (SnS) propagation in such systems. To address this challenge, we propose a novel channel prediction approach that incorporates dedicated channel modeling, probabilistic representations, and Bayesian inference algorithms for this emerging scenario. Specifically, we develop tensor-structured channel models in both the spatial-frequency-temporal (SFT) and beam-delay-Doppler (BDD) domains, which leverage temporal correlations among multiple pilot symbols for channel prediction. The factor matrices of multi-linear transformations are parameterized by BDD domain grids and SnS factors, where beam domain grids are jointly determined by angles and slopes under spatial-chirp based NF representations. To enable tractable inference, we replace environment-dependent BDD domain grids with uniformly sampled ones, and introduce perturbation parameters in each domain to mitigate grid mismatch. We further propose a hybrid beam domain strategy that integrates angle-only sampling with slope hyperparameterization to avoid the computational burden of explicit slope sampling. Based on the probabilistic models, we develop tensor-structured bi-layer inference (TS-BLI) algorithm under the expectation-maximization (EM) framework, which reduces computational complexity via tensor operations by leveraging the bi-layer factor graph for approximate E-step inference and an alternating strategy with closed-form updates in the M-step. Numerical simulations based on the near-practical channel simulator demonstrate the superior channel prediction performance of the proposed algorithm.
DMRS-Based Uplink Channel Estimation for MU-MIMO Systems with Location-Specific SCSI Acquisition
Jun 13, 2025With the growing number of users in multi-user multiple-input multiple-output (MU-MIMO) systems, demodulation reference signals (DMRSs) are efficiently multiplexed in the code domain via orthogonal cover codes (OCC) to ensure orthogonality and minimize pilot interference. In this paper, we investigate uplink DMRS-based channel estimation for MU-MIMO systems with Type II OCC pattern standardized in 3GPP Release 18, leveraging location-specific statistical channel state information (SCSI) to enhance performance. Specifically, we propose a SCSI-assisted Bayesian channel estimator (SA-BCE) based on the minimum mean square error criterion to suppress the pilot interference and noise, albeit at the cost of cubic computational complexity due to matrix inversions. To reduce this complexity while maintaining performance, we extend the scheme to a windowed version (SA-WBCE), which incorporates antenna-frequency domain windowing and beam-delay domain processing to exploit asymptotic sparsity and mitigate energy leakage in practical systems. To avoid the frequent real-time SCSI acquisition, we construct a grid-based location-specific SCSI database based on the principle of spatial consistency, and subsequently leverage the uplink received signals within each grid to extract the SCSI. Facilitated by the multilinear structure of wireless channels, we formulate the SCSI acquisition problem within each grid as a tensor decomposition problem, where the factor matrices are parameterized by the multi-path powers, delays, and angles. The computational complexity of SCSI acquisition can be significantly reduced by exploiting the Vandermonde structure of the factor matrices. Simulation results demonstrate that the proposed location-specific SCSI database construction method achieves high accuracy, while the SA-BCE and SA-WBCE significantly outperform state-of-the-art benchmarks in MU-MIMO systems.
Interference in Spectrum-Sharing Integrated Terrestrial and Satellite Networks: Modeling, Approximation, and Robust Transmit Beamforming
Jun 13, 2025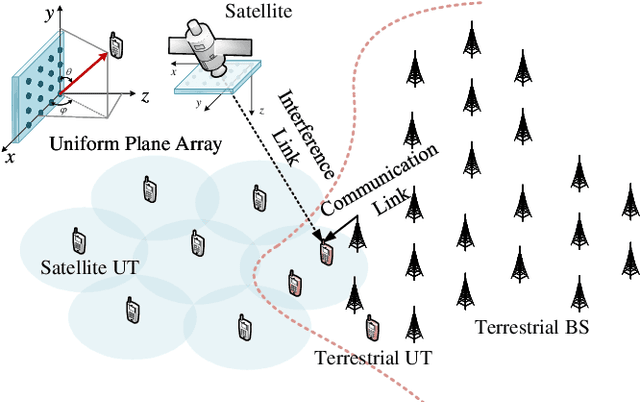
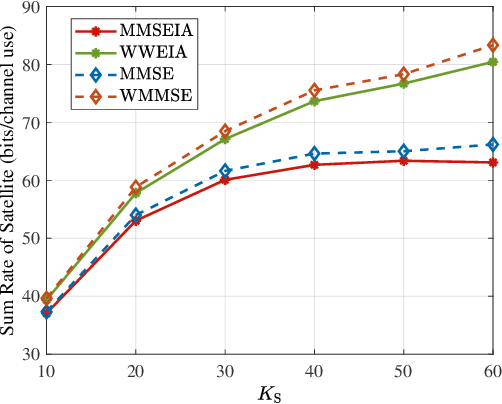
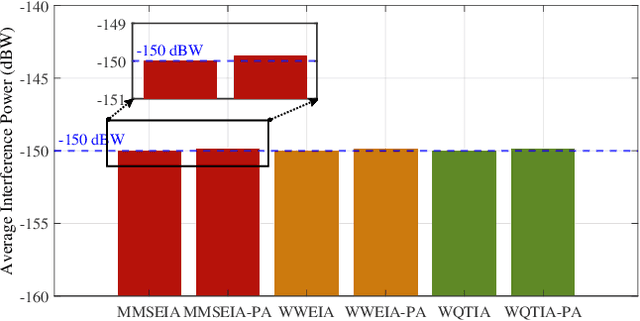
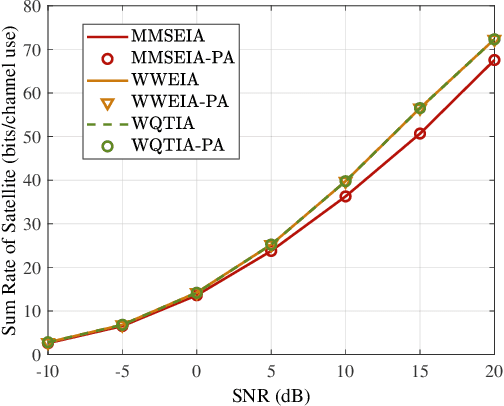
This paper investigates robust transmit (TX) beamforming from the satellite to user terminals (UTs), based on statistical channel state information (CSI). The proposed design specifically targets the mitigation of satellite-to-terrestrial interference in spectrum-sharing integrated terrestrial and satellite networks. By leveraging the distribution information of terrestrial UTs, we first establish an interference model from the satellite to terrestrial systems without shared CSI. Based on this, robust TX beamforming schemes are developed under both the interference threshold and the power budget. Two optimization criteria are considered: satellite weighted sum rate maximization and mean square error minimization. The former achieves a superior achievable rate performance through an iterative optimization framework, whereas the latter enables a low-complexity closed-form solution at the expense of reduced rate, with interference constraints satisfied via a bisection method. To avoid complex integral calculations and the dependence on user distribution information in inter-system interference evaluations, we propose a terrestrial base station position-aided approximation method, and the approximation errors are subsequently analyzed. Numerical simulations validate the effectiveness of our proposed schemes.