 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Channel Knowledge Map-Driven Two-Stage Coordinated User Scheduling in Multi-Cell Massive MIMO Systems
Mar 21, 2026This paper investigates narrowband coordinated user scheduling in multi-cell massive multiple-input multiple-output (MIMO) systems. We formulate the problem under a spectral-efficiency maximization criterion, revealing inherent challenges in computational complexity and signaling overhead. To address these, we develop a user-scheduling-oriented CKM (US-CKM) and a US-CKM-driven two-stage coordinated scheduling framework. By exploiting the mapping between location information and statistical channel state information (SCSI), the system enables rapid SCSI retrieval and persistent reuse, substantially reducing CSI acquisition overhead. Embedding statistical channel correlation into the CKM further characterizes interuser interference patterns. The framework designs an intra-cell active-user selection scheme for the first stage and an inter-cell coordinated scheduling scheme for the second, both based on US-CKM entries. The first stage identifies users with favorable channel gains and low intra-cell interference, reducing the candidate set with marginal sum-rate loss. The second stage suppresses inter-cell interference (ICI) by exploiting cross-cell channel correlations. To enhance robustness against imperfect SCSI in dynamic scattering environments, we augment the framework with a reliability-guided mechanism. Instead of uniform treatment, we evaluate entry stability using a grid reliability metric quantifying channel measurement variance at sampling locations. Low-reliability grids are identified, and their instantaneous CSI is acquired in real time to integrate with existing SCSI. This process refines channel gain and spatial correlation characteristics, ensuring robust performance under imperfect conditions.
DMRS-Based Uplink Channel Estimation for MU-MIMO Systems with Location-Specific SCSI Acquisition
Jun 13, 2025With the growing number of users in multi-user multiple-input multiple-output (MU-MIMO) systems, demodulation reference signals (DMRSs) are efficiently multiplexed in the code domain via orthogonal cover codes (OCC) to ensure orthogonality and minimize pilot interference. In this paper, we investigate uplink DMRS-based channel estimation for MU-MIMO systems with Type II OCC pattern standardized in 3GPP Release 18, leveraging location-specific statistical channel state information (SCSI) to enhance performance. Specifically, we propose a SCSI-assisted Bayesian channel estimator (SA-BCE) based on the minimum mean square error criterion to suppress the pilot interference and noise, albeit at the cost of cubic computational complexity due to matrix inversions. To reduce this complexity while maintaining performance, we extend the scheme to a windowed version (SA-WBCE), which incorporates antenna-frequency domain windowing and beam-delay domain processing to exploit asymptotic sparsity and mitigate energy leakage in practical systems. To avoid the frequent real-time SCSI acquisition, we construct a grid-based location-specific SCSI database based on the principle of spatial consistency, and subsequently leverage the uplink received signals within each grid to extract the SCSI. Facilitated by the multilinear structure of wireless channels, we formulate the SCSI acquisition problem within each grid as a tensor decomposition problem, where the factor matrices are parameterized by the multi-path powers, delays, and angles. The computational complexity of SCSI acquisition can be significantly reduced by exploiting the Vandermonde structure of the factor matrices. Simulation results demonstrate that the proposed location-specific SCSI database construction method achieves high accuracy, while the SA-BCE and SA-WBCE significantly outperform state-of-the-art benchmarks in MU-MIMO systems.
PRESERVE: Prefetching Model Weights and KV-Cache in Distributed LLM Serving
Jan 14, 2025



Large language models (LLMs) are widely used across various applications, but their substantial computational requirements pose significant challenges, particularly in terms of HBM bandwidth bottlenecks and inter-device communication overhead. In this paper, we present PRESERVE, a novel prefetching framework designed to optimize LLM inference by overlapping memory reads for model weights and KV-cache with collective communication operations. Through extensive experiments conducted on commercial AI accelerators, we demonstrate up to 1.6x end-to-end speedup on state-of-the-art, open-source LLMs. Additionally, we perform a design space exploration that identifies the optimal hardware configuration for the proposed method, showing a further 1.25x improvement in performance per cost by selecting the optimal L2 cache size. Our results show that PRESERVE has the potential to mitigate the memory bottlenecks and communication overheads, offering a solution to improve the performance and scalability of the LLM inference systems.
SSSD: Simply-Scalable Speculative Decoding
Nov 08, 2024



Over the past year, Speculative Decoding has gained popularity as a technique for accelerating Large Language Model inference. While several methods have been introduced, most struggle to deliver satisfactory performance at batch sizes typical for data centers ($\geq 8$) and often involve significant deployment complexities. In this work, we offer a theoretical explanation of how Speculative Decoding can be effectively utilized with larger batch sizes. We also introduce a method that integrates seamlessly into existing systems without additional training or the complexity of deploying a small LLM. In a continuous batching setting, we achieve a 4x increase in throughput without any latency impact for short context generation, and a 1.7-2x improvement in both latency and throughput for longer contexts.
Joint Channel Estimation and Prediction for Massive MIMO with Frequency Hopping Sounding
Jun 13, 2024



In massive multiple-input multiple-output (MIMO) systems, the downlink transmission performance heavily relies on accurate channel state information (CSI). Constrained by the transmitted power, user equipment always transmits sounding reference signals (SRSs) to the base station through frequency hopping, which will be leveraged to estimate uplink CSI and subsequently predict downlink CSI. This paper aims to investigate joint channel estimation and prediction (JCEP) for massive MIMO with frequency hopping sounding (FHS). Specifically, we present a multiple-subband (MS) delay-angle-Doppler (DAD) domain channel model with off-grid basis to tackle the energy leakage problem. Furthermore, we formulate the JCEP problem with FHS as a multiple measurement vector (MMV) problem, facilitating the sharing of common CSI across different subbands. To solve this problem, we propose an efficient Off-Grid-MS hybrid message passing (HMP) algorithm under the constrained Bethe free energy (BFE) framework. Aiming to address the lack of prior CSI in practical scenarios, the proposed algorithm can adaptively learn the hyper-parameters of the channel by minimizing the corresponding terms in the BFE expression. To alleviate the complexity of channel hyper-parameter learning, we leverage the approximations of the off-grid matrices to simplify the off-grid hyper-parameter estimation. Numerical results illustrate that the proposed algorithm can effectively mitigate the energy leakage issue and exploit the common CSI across different subbands, acquiring more accurate CSI compared to state-of-the-art counterparts.
A Two-Stream Meticulous Processing Network for Retinal Vessel Segmentation
Jan 15, 2020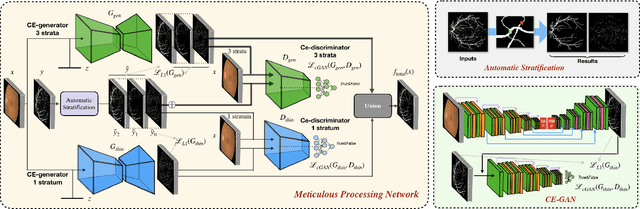
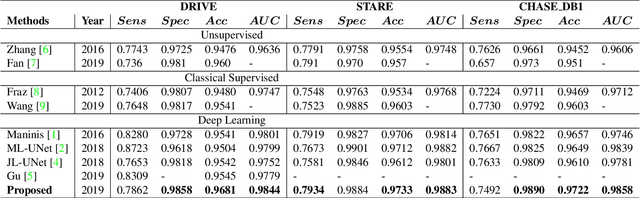
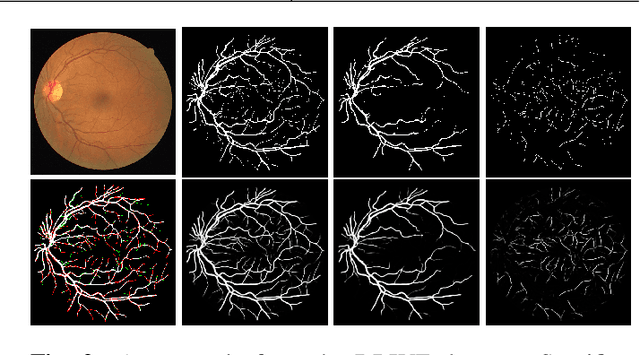

Vessel segmentation in fundus is a key diagnostic capability in ophthalmology, and there are various challenges remained in this essential task. Early approaches indicate that it is often difficult to obtain desirable segmentation performance on thin vessels and boundary areas due to the imbalance of vessel pixels with different thickness levels. In this paper, we propose a novel two-stream Meticulous-Processing Network (MP-Net) for tackling this problem. To pay more attention to the thin vessels and boundary areas, we firstly propose an efficient hierarchical model automatically stratifies the ground-truth masks into different thickness levels. Then a novel two-stream adversarial network is introduced to use the stratification results with a balanced loss function and an integration operation to achieve a better performance, especially in thin vessels and boundary areas detecting. Our model is proved to outperform state-of-the-art methods on DRIVE, STARE, and CHASE_DB1 datasets.