 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlasticine: A Traceable Diffusion Model for Medical Image Translation
Dec 20, 2025Domain gaps arising from variations in imaging devices and population distributions pose significant challenges for machine learning in medical image analysis. Existing image-to-image translation methods primarily aim to learn mappings between domains, often generating diverse synthetic data with variations in anatomical scale and shape, but they usually overlook spatial correspondence during the translation process. For clinical applications, traceability, defined as the ability to provide pixel-level correspondences between original and translated images, is equally important. This property enhances clinical interpretability but has been largely overlooked in previous approaches. To address this gap, we propose Plasticine, which is, to the best of our knowledge, the first end-to-end image-to-image translation framework explicitly designed with traceability as a core objective. Our method combines intensity translation and spatial transformation within a denoising diffusion framework. This design enables the generation of synthetic images with interpretable intensity transitions and spatially coherent deformations, supporting pixel-wise traceability throughout the translation process.
SGSR: Structure-Guided Multi-Contrast MRI Super-Resolution via Spatio-Frequency Co-Query Attention
Aug 06, 2024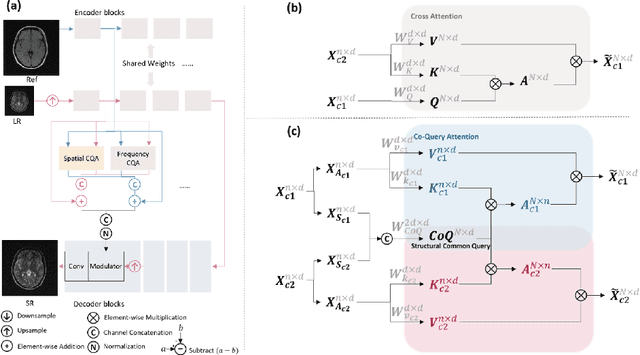
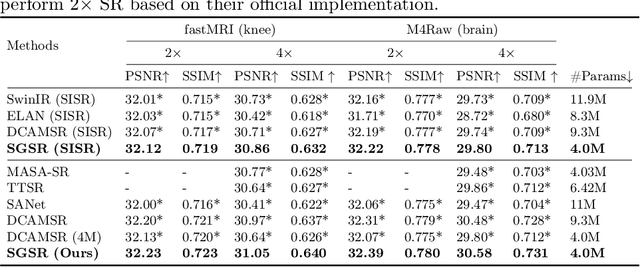
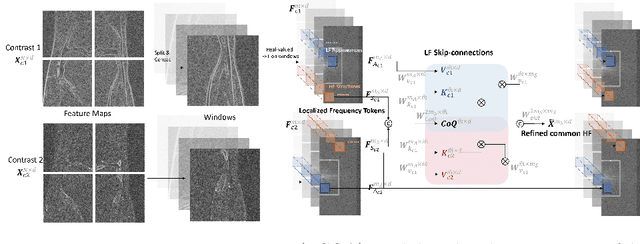
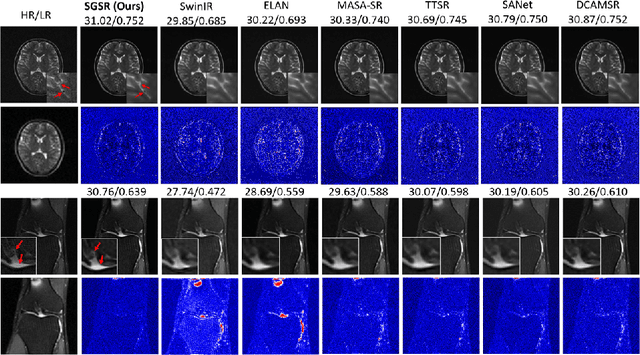
Magnetic Resonance Imaging (MRI) is a leading diagnostic modality for a wide range of exams, where multiple contrast images are often acquired for characterizing different tissues. However, acquiring high-resolution MRI typically extends scan time, which can introduce motion artifacts. Super-resolution of MRI therefore emerges as a promising approach to mitigate these challenges. Earlier studies have investigated the use of multiple contrasts for MRI super-resolution (MCSR), whereas majority of them did not fully exploit the rich contrast-invariant structural information. To fully utilize such crucial prior knowledge of multi-contrast MRI, in this work, we propose a novel structure-guided MCSR (SGSR) framework based on a new spatio-frequency co-query attention (CQA) mechanism. Specifically, CQA performs attention on features of multiple contrasts with a shared structural query, which is particularly designed to extract, fuse, and refine the common structures from different contrasts. We further propose a novel frequency-domain CQA module in addition to the spatial domain, to enable more fine-grained structural refinement. Extensive experiments on fastMRI knee data and low-field brain MRI show that SGSR outperforms state-of-the-art MCSR methods with statistical significance.
CAR: Contrast-Agnostic Deformable Medical Image Registration with Contrast-Invariant Latent Regularization
Aug 03, 2024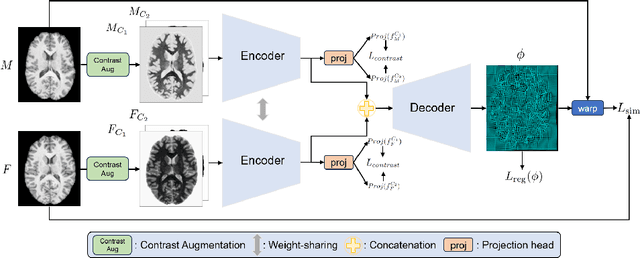

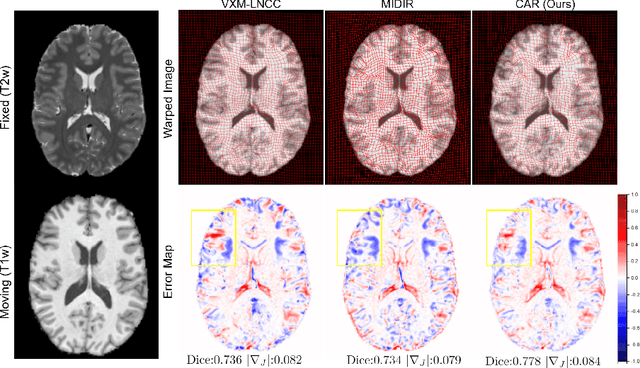

Multi-contrast image registration is a challenging task due to the complex intensity relationships between different imaging contrasts. Conventional image registration methods are typically based on iterative optimizations for each input image pair, which is time-consuming and sensitive to contrast variations. While learning-based approaches are much faster during the inference stage, due to generalizability issues, they typically can only be applied to the fixed contrasts observed during the training stage. In this work, we propose a novel contrast-agnostic deformable image registration framework that can be generalized to arbitrary contrast images, without observing them during training. Particularly, we propose a random convolution-based contrast augmentation scheme, which simulates arbitrary contrasts of images over a single image contrast while preserving their inherent structural information. To ensure that the network can learn contrast-invariant representations for facilitating contrast-agnostic registration, we further introduce contrast-invariant latent regularization (CLR) that regularizes representation in latent space through a contrast invariance loss. Experiments show that CAR outperforms the baseline approaches regarding registration accuracy and also possesses better generalization ability to unseen imaging contrasts. Code is available at \url{https://github.com/Yinsong0510/CAR}.
TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data
Jul 10, 2024



Images and structured tables are essential parts of real-world databases. Though tabular-image representation learning is promising to create new insights, it remains a challenging task, as tabular data is typically heterogeneous and incomplete, presenting significant modality disparities with images. Earlier works have mainly focused on simple modality fusion strategies in complete data scenarios, without considering the missing data issue, and thus are limited in practice. In this paper, we propose TIP, a novel tabular-image pre-training framework for learning multimodal representations robust to incomplete tabular data. Specifically, TIP investigates a novel self-supervised learning (SSL) strategy, including a masked tabular reconstruction task for tackling data missingness, and image-tabular matching and contrastive learning objectives to capture multimodal information. Moreover, TIP proposes a versatile tabular encoder tailored for incomplete, heterogeneous tabular data and a multimodal interaction module for inter-modality representation learning. Experiments are performed on downstream multimodal classification tasks using both natural and medical image datasets. The results show that TIP outperforms state-of-the-art supervised/SSL image/multimodal algorithms in both complete and incomplete data scenarios. Our code is available at https://github.com/siyi-wind/TIP.
Extend Wave Function Collapse to Large-Scale Content Generation
Aug 14, 2023Wave Function Collapse (WFC) is a widely used tile-based algorithm in procedural content generation, including textures, objects, and scenes. However, the current WFC algorithm and related research lack the ability to generate commercialized large-scale or infinite content due to constraint conflict and time complexity costs. This paper proposes a Nested WFC (N-WFC) algorithm framework to reduce time complexity. To avoid conflict and backtracking problems, we offer a complete and sub-complete tileset preparation strategy, which requires only a small number of tiles to generate aperiodic and deterministic infinite content. We also introduce the weight-brush system that combines N-WFC and sub-complete tileset, proving its suitability for game design. Our contribution addresses WFC's challenge in massive content generation and provides a theoretical basis for implementing concrete games.
Structure Unbiased Adversarial Model for Medical Image Segmentation
May 26, 2022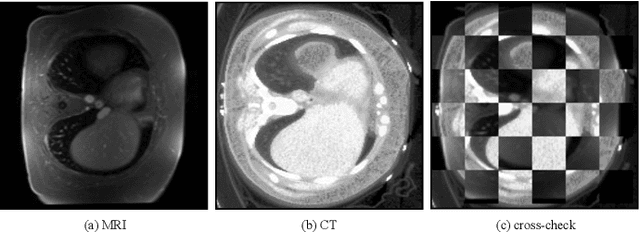
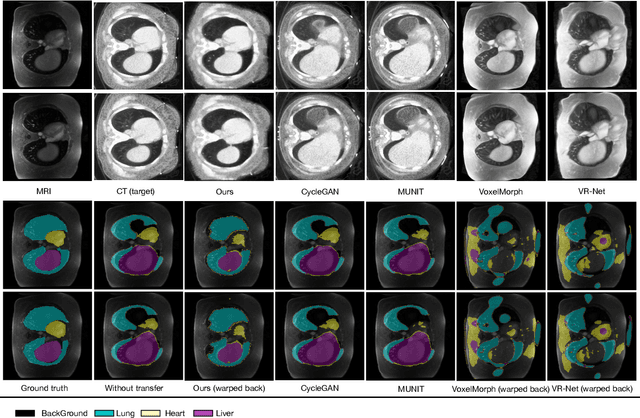
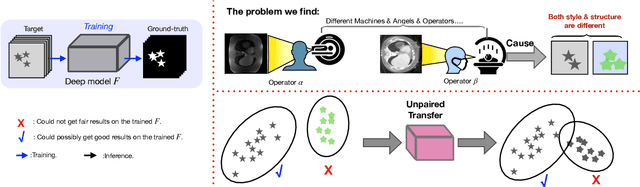
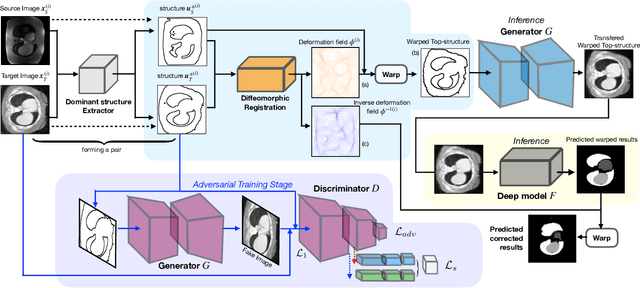
Generative models have been widely proposed in image recognition to generate more images where the distribution is similar to that of the real images. It often introduces a discriminator network to discriminate original real data and generated data. However, such discriminator often considers the distribution of the data and did not pay enough attention to the intrinsic gap due to structure. In this paper, we reformulate a new image to image translation problem to reduce structural gap, in addition to the typical intensity distribution gap. We further propose a simple yet important Structure Unbiased Adversarial Model for Medical Image Segmentation (SUAM) with learnable inverse structural deformation for medical image segmentation. It consists of a structure extractor, an attention diffeomorphic registration and a structure \& intensity distribution rendering module. The structure extractor aims to extract the dominant structure of the input image. The attention diffeomorphic registration is proposed to reduce the structure gap with an inverse deformation field to warp the prediction masks back to their original form. The structure rendering module is to render the deformed structure to an image with targeted intensity distribution. We apply the proposed SUAM on both optical coherence tomography (OCT), magnetic resonance imaging (MRI) and computerized tomography (CT) data. Experimental results show that the proposed method has the capability to transfer both intensity and structure distributions.
A Two-Stream Meticulous Processing Network for Retinal Vessel Segmentation
Jan 15, 2020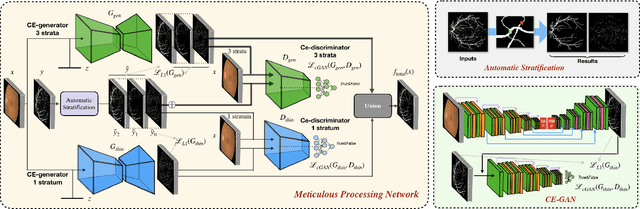
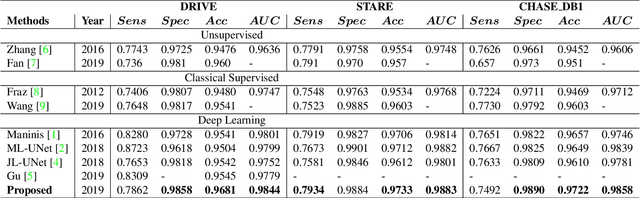
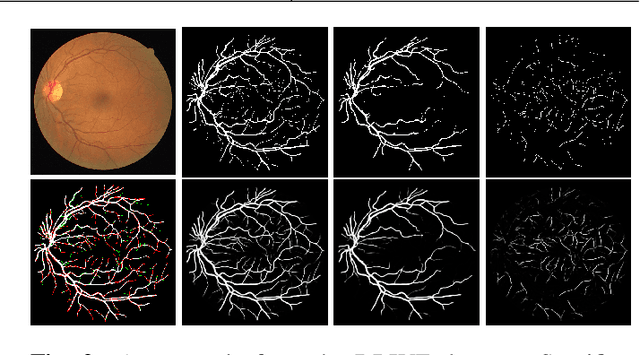

Vessel segmentation in fundus is a key diagnostic capability in ophthalmology, and there are various challenges remained in this essential task. Early approaches indicate that it is often difficult to obtain desirable segmentation performance on thin vessels and boundary areas due to the imbalance of vessel pixels with different thickness levels. In this paper, we propose a novel two-stream Meticulous-Processing Network (MP-Net) for tackling this problem. To pay more attention to the thin vessels and boundary areas, we firstly propose an efficient hierarchical model automatically stratifies the ground-truth masks into different thickness levels. Then a novel two-stream adversarial network is introduced to use the stratification results with a balanced loss function and an integration operation to achieve a better performance, especially in thin vessels and boundary areas detecting. Our model is proved to outperform state-of-the-art methods on DRIVE, STARE, and CHASE_DB1 datasets.