 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Measure Consistency Regularization for Partially Observed Data
Feb 01, 2026The problem of corrupted data, missing features, or missing modalities continues to plague the modern machine learning landscape. To address this issue, a class of regularization methods that enforce consistency between imputed and fully observed data has emerged as a promising approach for improving model generalization, particularly in partially observed settings. We refer to this class of methods as Measure Consistency Regularization (MCR). Despite its empirical success in various applications, such as image inpainting, data imputation and semi-supervised learning, a fundamental understanding of the theoretical underpinnings of MCR remains limited. This paper bridges this gap by offering theoretical insights into why, when, and how MCR enhances imputation quality under partial observability, viewed through the lens of neural network distance. Our theoretical analysis identifies the term responsible for MCR's generalization advantage and extends to the imperfect training regime, demonstrating that this advantage is not always guaranteed. Guided by these insights, we propose a novel training protocol that monitors the duality gap to determine an early stopping point that preserves the generalization benefit. We then provide detailed empirical evidence to support our theoretical claims and to show the effectiveness and accuracy of our proposed stopping condition. We further provide a set of real-world data simulations to show the versatility of MCR under different model architectures designed for different data sources.
Self-Supervised Slice-to-Volume Reconstruction with Gaussian Representations for Fetal MRI
Jan 30, 2026Reconstructing 3D fetal MR volumes from motion-corrupted stacks of 2D slices is a crucial and challenging task. Conventional slice-to-volume reconstruction (SVR) methods are time-consuming and require multiple orthogonal stacks for reconstruction. While learning-based SVR approaches have significantly reduced the time required at the inference stage, they heavily rely on ground truth information for training, which is inaccessible in practice. To address these challenges, we propose GaussianSVR, a self-supervised framework for slice-to-volume reconstruction. GaussianSVR represents the target volume using 3D Gaussian representations to achieve high-fidelity reconstruction. It leverages a simulated forward slice acquisition model to enable self-supervised training, alleviating the need for ground-truth volumes. Furthermore, to enhance both accuracy and efficiency, we introduce a multi-resolution training strategy that jointly optimizes Gaussian parameters and spatial transformations across different resolution levels. Experiments show that GaussianSVR outperforms the baseline methods on fetal MR volumetric reconstruction. Code will be available upon acceptance.
Adaptive Conditional Contrast-Agnostic Deformable Image Registration with Uncertainty Estimation
Jan 09, 2026Deformable multi-contrast image registration is a challenging yet crucial task due to the complex, non-linear intensity relationships across different imaging contrasts. Conventional registration methods typically rely on iterative optimization of the deformation field, which is time-consuming. Although recent learning-based approaches enable fast and accurate registration during inference, their generalizability remains limited to the specific contrasts observed during training. In this work, we propose an adaptive conditional contrast-agnostic deformable image registration framework (AC-CAR) based on a random convolution-based contrast augmentation scheme. AC-CAR can generalize to arbitrary imaging contrasts without observing them during training. To encourage contrast-invariant feature learning, we propose an adaptive conditional feature modulator (ACFM) that adaptively modulates the features and the contrast-invariant latent regularization to enforce the consistency of the learned feature across different imaging contrasts. Additionally, we enable our framework to provide contrast-agnostic registration uncertainty by integrating a variance network that leverages the contrast-agnostic registration encoder to improve the trustworthiness and reliability of AC-CAR. Experimental results demonstrate that AC-CAR outperforms baseline methods in registration accuracy and exhibits superior generalization to unseen imaging contrasts. Code is available at https://github.com/Yinsong0510/AC-CAR.
Mutual Information Surprise: Rethinking Unexpectedness in Autonomous Systems
Aug 24, 2025Recent breakthroughs in autonomous experimentation have demonstrated remarkable physical capabilities, yet their cognitive control remains limited--often relying on static heuristics or classical optimization. A core limitation is the absence of a principled mechanism to detect and adapt to the unexpectedness. While traditional surprise measures--such as Shannon or Bayesian Surprise--offer momentary detection of deviation, they fail to capture whether a system is truly learning and adapting. In this work, we introduce Mutual Information Surprise (MIS), a new framework that redefines surprise not as anomaly detection, but as a signal of epistemic growth. MIS quantifies the impact of new observations on mutual information, enabling autonomous systems to reflect on their learning progression. We develop a statistical test sequence to detect meaningful shifts in estimated mutual information and propose a mutual information surprise reaction policy (MISRP) that dynamically governs system behavior through sampling adjustment and process forking. Empirical evaluations--on both synthetic domains and a dynamic pollution map estimation task--show that MISRP-governed strategies significantly outperform classical surprise-based approaches in stability, responsiveness, and predictive accuracy. By shifting surprise from reactive to reflective, MIS offers a path toward more self-aware and adaptive autonomous systems.
SGSR: Structure-Guided Multi-Contrast MRI Super-Resolution via Spatio-Frequency Co-Query Attention
Aug 06, 2024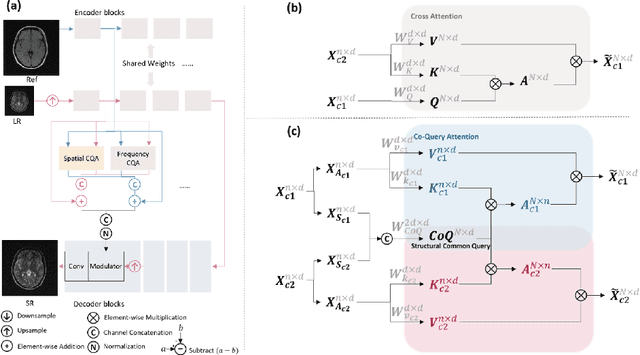
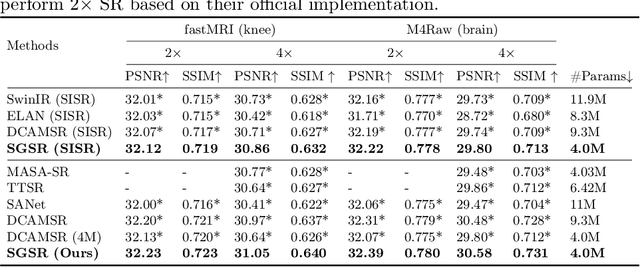
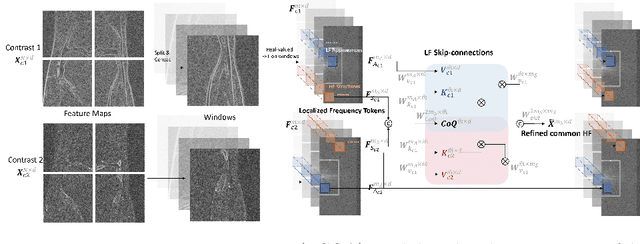
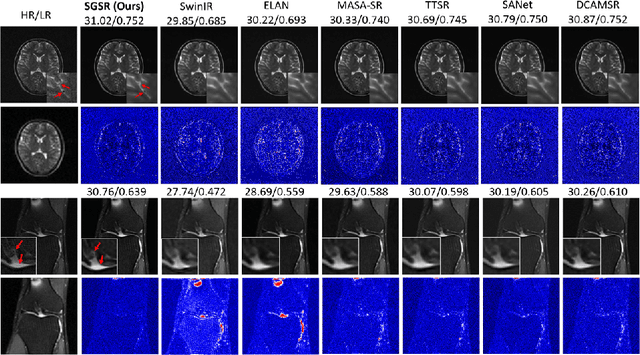
Magnetic Resonance Imaging (MRI) is a leading diagnostic modality for a wide range of exams, where multiple contrast images are often acquired for characterizing different tissues. However, acquiring high-resolution MRI typically extends scan time, which can introduce motion artifacts. Super-resolution of MRI therefore emerges as a promising approach to mitigate these challenges. Earlier studies have investigated the use of multiple contrasts for MRI super-resolution (MCSR), whereas majority of them did not fully exploit the rich contrast-invariant structural information. To fully utilize such crucial prior knowledge of multi-contrast MRI, in this work, we propose a novel structure-guided MCSR (SGSR) framework based on a new spatio-frequency co-query attention (CQA) mechanism. Specifically, CQA performs attention on features of multiple contrasts with a shared structural query, which is particularly designed to extract, fuse, and refine the common structures from different contrasts. We further propose a novel frequency-domain CQA module in addition to the spatial domain, to enable more fine-grained structural refinement. Extensive experiments on fastMRI knee data and low-field brain MRI show that SGSR outperforms state-of-the-art MCSR methods with statistical significance.
CAR: Contrast-Agnostic Deformable Medical Image Registration with Contrast-Invariant Latent Regularization
Aug 03, 2024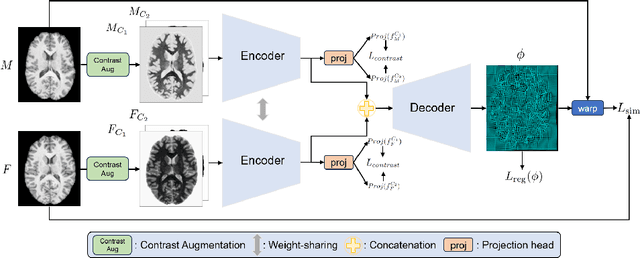

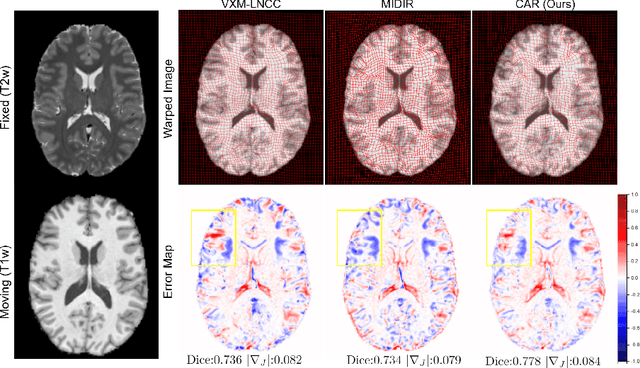

Multi-contrast image registration is a challenging task due to the complex intensity relationships between different imaging contrasts. Conventional image registration methods are typically based on iterative optimizations for each input image pair, which is time-consuming and sensitive to contrast variations. While learning-based approaches are much faster during the inference stage, due to generalizability issues, they typically can only be applied to the fixed contrasts observed during the training stage. In this work, we propose a novel contrast-agnostic deformable image registration framework that can be generalized to arbitrary contrast images, without observing them during training. Particularly, we propose a random convolution-based contrast augmentation scheme, which simulates arbitrary contrasts of images over a single image contrast while preserving their inherent structural information. To ensure that the network can learn contrast-invariant representations for facilitating contrast-agnostic registration, we further introduce contrast-invariant latent regularization (CLR) that regularizes representation in latent space through a contrast invariance loss. Experiments show that CAR outperforms the baseline approaches regarding registration accuracy and also possesses better generalization ability to unseen imaging contrasts. Code is available at \url{https://github.com/Yinsong0510/CAR}.
TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data
Jul 10, 2024



Images and structured tables are essential parts of real-world databases. Though tabular-image representation learning is promising to create new insights, it remains a challenging task, as tabular data is typically heterogeneous and incomplete, presenting significant modality disparities with images. Earlier works have mainly focused on simple modality fusion strategies in complete data scenarios, without considering the missing data issue, and thus are limited in practice. In this paper, we propose TIP, a novel tabular-image pre-training framework for learning multimodal representations robust to incomplete tabular data. Specifically, TIP investigates a novel self-supervised learning (SSL) strategy, including a masked tabular reconstruction task for tackling data missingness, and image-tabular matching and contrastive learning objectives to capture multimodal information. Moreover, TIP proposes a versatile tabular encoder tailored for incomplete, heterogeneous tabular data and a multimodal interaction module for inter-modality representation learning. Experiments are performed on downstream multimodal classification tasks using both natural and medical image datasets. The results show that TIP outperforms state-of-the-art supervised/SSL image/multimodal algorithms in both complete and incomplete data scenarios. Our code is available at https://github.com/siyi-wind/TIP.
Tracking Dynamic Gaussian Density with a Theoretically Optimal Sliding Window Approach
Mar 11, 2024
Dynamic density estimation is ubiquitous in many applications, including computer vision and signal processing. One popular method to tackle this problem is the "sliding window" kernel density estimator. There exist various implementations of this method that use heuristically defined weight sequences for the observed data. The weight sequence, however, is a key aspect of the estimator affecting the tracking performance significantly. In this work, we study the exact mean integrated squared error (MISE) of "sliding window" Gaussian Kernel Density Estimators for evolving Gaussian densities. We provide a principled guide for choosing the optimal weight sequence by theoretically characterizing the exact MISE, which can be formulated as constrained quadratic programming. We present empirical evidence with synthetic datasets to show that our weighting scheme indeed improves the tracking performance compared to heuristic approaches.
Conditional Deformable Image Registration with Spatially-Variant and Adaptive Regularization
Mar 19, 2023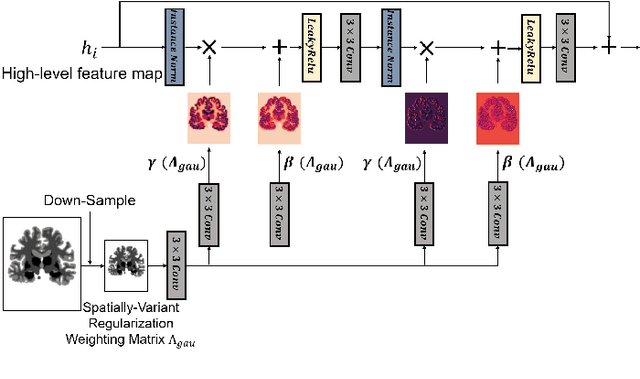

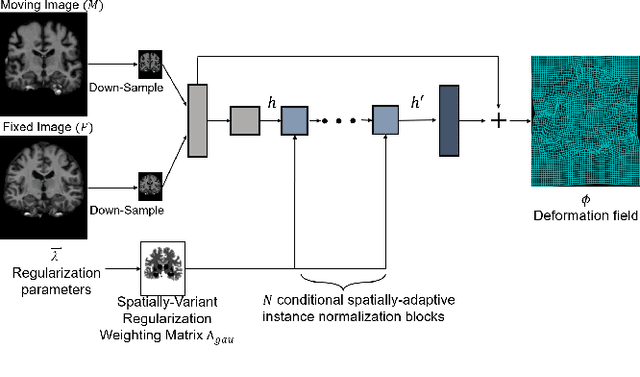
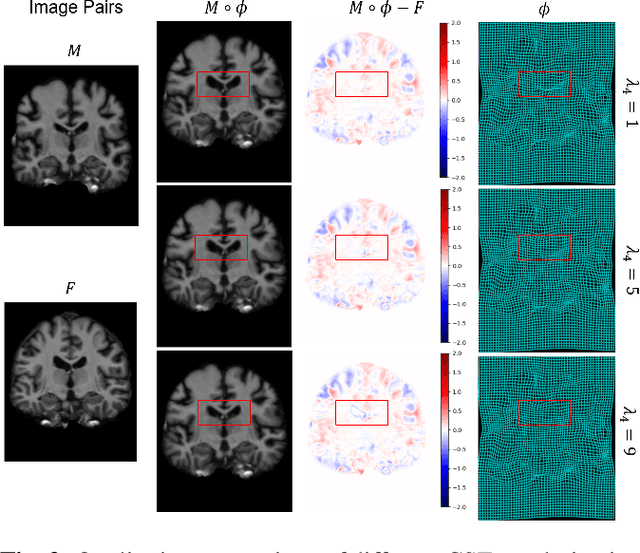
Deep learning-based image registration approaches have shown competitive performance and run-time advantages compared to conventional image registration methods. However, existing learning-based approaches mostly require to train separate models with respect to different regularization hyperparameters for manual hyperparameter searching and often do not allow spatially-variant regularization. In this work, we propose a learning-based registration approach based on a novel conditional spatially adaptive instance normalization (CSAIN) to address these challenges. The proposed method introduces a spatially-variant regularization and learns its effect of achieving spatially-adaptive regularization by conditioning the registration network on the hyperparameter matrix via CSAIN. This allows varying of spatially adaptive regularization at inference to obtain multiple plausible deformations with a single pre-trained model. Additionally, the proposed method enables automatic hyperparameter optimization to avoid manual hyperparameter searching. Experiments show that our proposed method outperforms the baseline approaches while achieving spatially-variant and adaptive regularization.
TAP: The Attention Patch for Cross-Modal Knowledge Transfer from Unlabeled Data
Feb 04, 2023This work investigates the intersection of cross modal learning and semi supervised learning, where we aim to improve the supervised learning performance of the primary modality by borrowing missing information from an unlabeled modality. We investigate this problem from a Nadaraya Watson (NW) kernel regression perspective and show that this formulation implicitly leads to a kernelized cross attention module. To this end, we propose The Attention Patch (TAP), a simple neural network plugin that allows data level knowledge transfer from the unlabeled modality. We provide numerical simulations on three real world datasets to examine each aspect of TAP and show that a TAP integration in a neural network can improve generalization performance using the unlabeled modality.