 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Dynamic Modality Selection for Incomplete Multimodal Classification
Jan 30, 2026Multimodal deep learning (MDL) has achieved remarkable success across various domains, yet its practical deployment is often hindered by incomplete multimodal data. Existing incomplete MDL methods either discard missing modalities, risking the loss of valuable task-relevant information, or recover them, potentially introducing irrelevant noise, leading to the discarding-imputation dilemma. To address this dilemma, in this paper, we propose DyMo, a new inference-time dynamic modality selection framework that adaptively identifies and integrates reliable recovered modalities, fully exploring task-relevant information beyond the conventional discard-or-impute paradigm. Central to DyMo is a novel selection algorithm that maximizes multimodal task-relevant information for each test sample. Since direct estimation of such information at test time is intractable due to the unknown data distribution, we theoretically establish a connection between information and the task loss, which we compute at inference time as a tractable proxy. Building on this, a novel principled reward function is proposed to guide modality selection. In addition, we design a flexible multimodal network architecture compatible with arbitrary modality combinations, alongside a tailored training strategy for robust representation learning. Extensive experiments on diverse natural and medical image datasets show that DyMo significantly outperforms state-of-the-art incomplete/dynamic MDL methods across various missing-data scenarios. Our code is available at https://github.com//siyi-wind/DyMo.
Self-Supervised Slice-to-Volume Reconstruction with Gaussian Representations for Fetal MRI
Jan 30, 2026Reconstructing 3D fetal MR volumes from motion-corrupted stacks of 2D slices is a crucial and challenging task. Conventional slice-to-volume reconstruction (SVR) methods are time-consuming and require multiple orthogonal stacks for reconstruction. While learning-based SVR approaches have significantly reduced the time required at the inference stage, they heavily rely on ground truth information for training, which is inaccessible in practice. To address these challenges, we propose GaussianSVR, a self-supervised framework for slice-to-volume reconstruction. GaussianSVR represents the target volume using 3D Gaussian representations to achieve high-fidelity reconstruction. It leverages a simulated forward slice acquisition model to enable self-supervised training, alleviating the need for ground-truth volumes. Furthermore, to enhance both accuracy and efficiency, we introduce a multi-resolution training strategy that jointly optimizes Gaussian parameters and spatial transformations across different resolution levels. Experiments show that GaussianSVR outperforms the baseline methods on fetal MR volumetric reconstruction. Code will be available upon acceptance.
Adaptive Conditional Contrast-Agnostic Deformable Image Registration with Uncertainty Estimation
Jan 09, 2026Deformable multi-contrast image registration is a challenging yet crucial task due to the complex, non-linear intensity relationships across different imaging contrasts. Conventional registration methods typically rely on iterative optimization of the deformation field, which is time-consuming. Although recent learning-based approaches enable fast and accurate registration during inference, their generalizability remains limited to the specific contrasts observed during training. In this work, we propose an adaptive conditional contrast-agnostic deformable image registration framework (AC-CAR) based on a random convolution-based contrast augmentation scheme. AC-CAR can generalize to arbitrary imaging contrasts without observing them during training. To encourage contrast-invariant feature learning, we propose an adaptive conditional feature modulator (ACFM) that adaptively modulates the features and the contrast-invariant latent regularization to enforce the consistency of the learned feature across different imaging contrasts. Additionally, we enable our framework to provide contrast-agnostic registration uncertainty by integrating a variance network that leverages the contrast-agnostic registration encoder to improve the trustworthiness and reliability of AC-CAR. Experimental results demonstrate that AC-CAR outperforms baseline methods in registration accuracy and exhibits superior generalization to unseen imaging contrasts. Code is available at https://github.com/Yinsong0510/AC-CAR.
UPMRI: Unsupervised Parallel MRI Reconstruction via Projected Conditional Flow Matching
Dec 19, 2025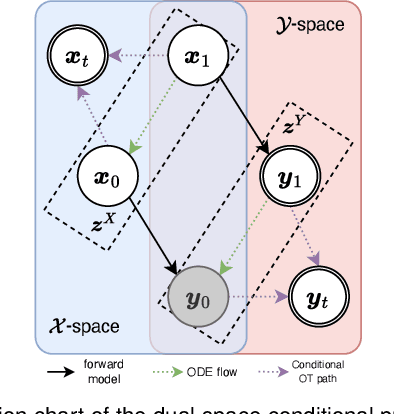
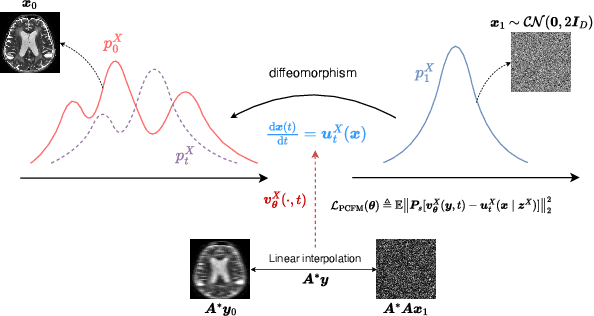
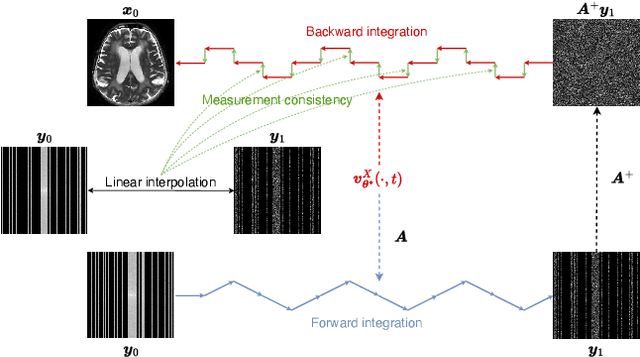
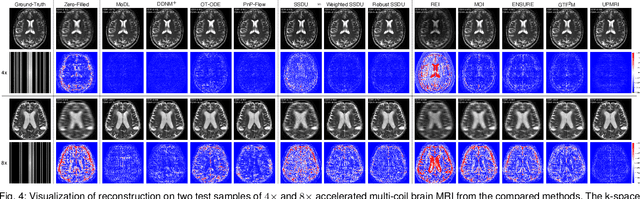
Reconstructing high-quality images from substantially undersampled k-space data for accelerated MRI presents a challenging ill-posed inverse problem. While supervised deep learning has revolutionized this field, it relies heavily on large datasets of fully sampled ground-truth images, which are often impractical or impossible to acquire in clinical settings due to long scan times. Despite advances in self-supervised/unsupervised MRI reconstruction, their performance remains inadequate at high acceleration rates. To bridge this gap, we introduce UPMRI, an unsupervised reconstruction framework based on Projected Conditional Flow Matching (PCFM) and its unsupervised transformation. Unlike standard generative models, PCFM learns the prior distribution of fully sampled parallel MRI data by utilizing only undersampled k-space measurements. To reconstruct the image, we establish a novel theoretical link between the marginal vector field in the measurement space, governed by the continuity equation, and the optimal solution to the PCFM objective. This connection results in a cyclic dual-space sampling algorithm for high-quality reconstruction. Extensive evaluations on the fastMRI brain and CMRxRecon cardiac datasets demonstrate that UPMRI significantly outperforms state-of-the-art self-supervised and unsupervised baselines. Notably, it also achieves reconstruction fidelity comparable to or better than leading supervised methods at high acceleration factors, while requiring no fully sampled training data.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
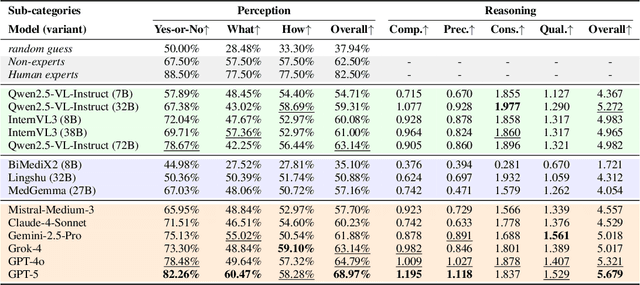

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
STiL: Semi-supervised Tabular-Image Learning for Comprehensive Task-Relevant Information Exploration in Multimodal Classification
Mar 08, 2025Multimodal image-tabular learning is gaining attention, yet it faces challenges due to limited labeled data. While earlier work has applied self-supervised learning (SSL) to unlabeled data, its task-agnostic nature often results in learning suboptimal features for downstream tasks. Semi-supervised learning (SemiSL), which combines labeled and unlabeled data, offers a promising solution. However, existing multimodal SemiSL methods typically focus on unimodal or modality-shared features, ignoring valuable task-relevant modality-specific information, leading to a Modality Information Gap. In this paper, we propose STiL, a novel SemiSL tabular-image framework that addresses this gap by comprehensively exploring task-relevant information. STiL features a new disentangled contrastive consistency module to learn cross-modal invariant representations of shared information while retaining modality-specific information via disentanglement. We also propose a novel consensus-guided pseudo-labeling strategy to generate reliable pseudo-labels based on classifier consensus, along with a new prototype-guided label smoothing technique to refine pseudo-label quality with prototype embeddings, thereby enhancing task-relevant information learning in unlabeled data. Experiments on natural and medical image datasets show that STiL outperforms the state-of-the-art supervised/SSL/SemiSL image/multimodal approaches. Our code is publicly available.
Unsupervised Accelerated MRI Reconstruction via Ground-Truth-Free Flow Matching
Feb 24, 2025Accelerated magnetic resonance imaging involves reconstructing fully sampled images from undersampled k-space measurements. Current state-of-the-art approaches have mainly focused on either end-to-end supervised training inspired by compressed sensing formulations, or posterior sampling methods built on modern generative models. However, their efficacy heavily relies on large datasets of fully sampled images, which may not always be available in practice. To address this issue, we propose an unsupervised MRI reconstruction method based on ground-truth-free flow matching (GTF$^2$M). Particularly, the GTF$^2$M learns a prior denoising process of fully sampled ground-truth images using only undersampled data. Based on that, an efficient cyclic reconstruction algorithm is further proposed to perform forward and backward integration in the dual space of image-space signal and k-space measurement. We compared our method with state-of-the-art learning-based baselines on the fastMRI database of both single-coil knee and multi-coil brain MRIs. The results show that our proposed unsupervised method can significantly outperform existing unsupervised approaches, and achieve performance comparable to most supervised end-to-end and prior learning baselines trained on fully sampled MRI, while offering greater efficiency than the compared generative model-based approaches.
CAR: Contrast-Agnostic Deformable Medical Image Registration with Contrast-Invariant Latent Regularization
Aug 03, 2024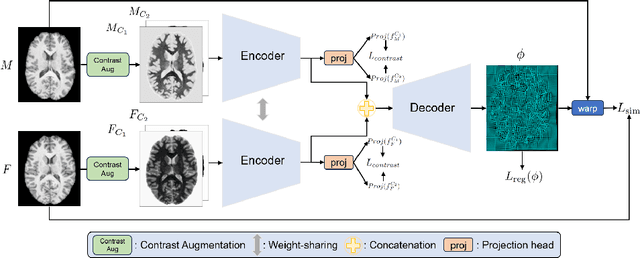

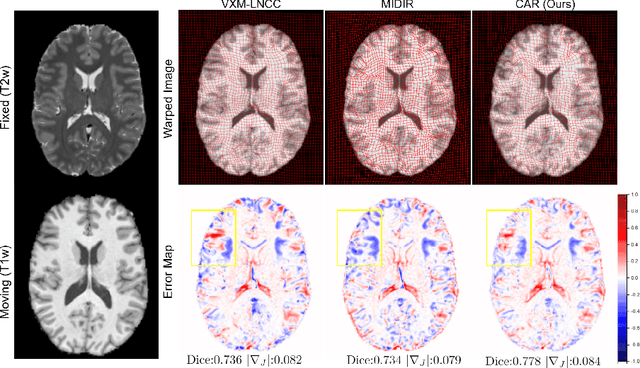

Multi-contrast image registration is a challenging task due to the complex intensity relationships between different imaging contrasts. Conventional image registration methods are typically based on iterative optimizations for each input image pair, which is time-consuming and sensitive to contrast variations. While learning-based approaches are much faster during the inference stage, due to generalizability issues, they typically can only be applied to the fixed contrasts observed during the training stage. In this work, we propose a novel contrast-agnostic deformable image registration framework that can be generalized to arbitrary contrast images, without observing them during training. Particularly, we propose a random convolution-based contrast augmentation scheme, which simulates arbitrary contrasts of images over a single image contrast while preserving their inherent structural information. To ensure that the network can learn contrast-invariant representations for facilitating contrast-agnostic registration, we further introduce contrast-invariant latent regularization (CLR) that regularizes representation in latent space through a contrast invariance loss. Experiments show that CAR outperforms the baseline approaches regarding registration accuracy and also possesses better generalization ability to unseen imaging contrasts. Code is available at \url{https://github.com/Yinsong0510/CAR}.
Toward Universal Medical Image Registration via Sharpness-Aware Meta-Continual Learning
Jun 25, 2024Current deep learning approaches in medical image registration usually face the challenges of distribution shift and data collection, hindering real-world deployment. In contrast, universal medical image registration aims to perform registration on a wide range of clinically relevant tasks simultaneously, thus having tremendous potential for clinical applications. In this paper, we present the first attempt to achieve the goal of universal 3D medical image registration in sequential learning scenarios by proposing a continual learning method. Specifically, we utilize meta-learning with experience replay to mitigating the problem of catastrophic forgetting. To promote the generalizability of meta-continual learning, we further propose sharpness-aware meta-continual learning (SAMCL). We validate the effectiveness of our method on four datasets in a continual learning setup, including brain MR, abdomen CT, lung CT, and abdomen MR-CT image pairs. Results have shown the potential of SAMCL in realizing universal image registration, which performs better than or on par with vanilla sequential or centralized multi-task training strategies.The source code will be available from https://github.com/xzluo97/Continual-Reg.
Bayesian Intrinsic Groupwise Image Registration: Unsupervised Disentanglement of Anatomy and Geometry
Jan 04, 2024



This article presents a general Bayesian learning framework for multi-modal groupwise registration on medical images. The method builds on probabilistic modelling of the image generative process, where the underlying common anatomy and geometric variations of the observed images are explicitly disentangled as latent variables. Thus, groupwise registration is achieved through the solution to Bayesian inference. We propose a novel hierarchical variational auto-encoding architecture to realize the inference procedure of the latent variables, where the registration parameters can be calculated in a mathematically interpretable fashion. Remarkably, this new paradigm can learn groupwise registration in an unsupervised closed-loop self-reconstruction process, sparing the burden of designing complex intensity-based similarity measures. The computationally efficient disentangled architecture is also inherently scalable and flexible, allowing for groupwise registration on large-scale image groups with variable sizes. Furthermore, the inferred structural representations from disentanglement learning are capable of capturing the latent anatomy of the observations with visual semantics. Extensive experiments were conducted to validate the proposed framework, including four datasets from cardiac, brain and abdominal medical images. The results have demonstrated the superiority of our method over conventional similarity-based approaches in terms of accuracy, efficiency, scalability and interpretability.