 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Dynamic Modality Selection for Incomplete Multimodal Classification
Jan 30, 2026Multimodal deep learning (MDL) has achieved remarkable success across various domains, yet its practical deployment is often hindered by incomplete multimodal data. Existing incomplete MDL methods either discard missing modalities, risking the loss of valuable task-relevant information, or recover them, potentially introducing irrelevant noise, leading to the discarding-imputation dilemma. To address this dilemma, in this paper, we propose DyMo, a new inference-time dynamic modality selection framework that adaptively identifies and integrates reliable recovered modalities, fully exploring task-relevant information beyond the conventional discard-or-impute paradigm. Central to DyMo is a novel selection algorithm that maximizes multimodal task-relevant information for each test sample. Since direct estimation of such information at test time is intractable due to the unknown data distribution, we theoretically establish a connection between information and the task loss, which we compute at inference time as a tractable proxy. Building on this, a novel principled reward function is proposed to guide modality selection. In addition, we design a flexible multimodal network architecture compatible with arbitrary modality combinations, alongside a tailored training strategy for robust representation learning. Extensive experiments on diverse natural and medical image datasets show that DyMo significantly outperforms state-of-the-art incomplete/dynamic MDL methods across various missing-data scenarios. Our code is available at https://github.com//siyi-wind/DyMo.
Adaptive Conditional Contrast-Agnostic Deformable Image Registration with Uncertainty Estimation
Jan 09, 2026Deformable multi-contrast image registration is a challenging yet crucial task due to the complex, non-linear intensity relationships across different imaging contrasts. Conventional registration methods typically rely on iterative optimization of the deformation field, which is time-consuming. Although recent learning-based approaches enable fast and accurate registration during inference, their generalizability remains limited to the specific contrasts observed during training. In this work, we propose an adaptive conditional contrast-agnostic deformable image registration framework (AC-CAR) based on a random convolution-based contrast augmentation scheme. AC-CAR can generalize to arbitrary imaging contrasts without observing them during training. To encourage contrast-invariant feature learning, we propose an adaptive conditional feature modulator (ACFM) that adaptively modulates the features and the contrast-invariant latent regularization to enforce the consistency of the learned feature across different imaging contrasts. Additionally, we enable our framework to provide contrast-agnostic registration uncertainty by integrating a variance network that leverages the contrast-agnostic registration encoder to improve the trustworthiness and reliability of AC-CAR. Experimental results demonstrate that AC-CAR outperforms baseline methods in registration accuracy and exhibits superior generalization to unseen imaging contrasts. Code is available at https://github.com/Yinsong0510/AC-CAR.
L2Calib: $SE(3)$-Manifold Reinforcement Learning for Robust Extrinsic Calibration with Degenerate Motion Resilience
Aug 08, 2025Extrinsic calibration is essential for multi-sensor fusion, existing methods rely on structured targets or fully-excited data, limiting real-world applicability. Online calibration further suffers from weak excitation, leading to unreliable estimates. To address these limitations, we propose a reinforcement learning (RL)-based extrinsic calibration framework that formulates extrinsic calibration as a decision-making problem, directly optimizes $SE(3)$ extrinsics to enhance odometry accuracy. Our approach leverages a probabilistic Bingham distribution to model 3D rotations, ensuring stable optimization while inherently retaining quaternion symmetry. A trajectory alignment reward mechanism enables robust calibration without structured targets by quantitatively evaluating estimated tightly-coupled trajectory against a reference trajectory. Additionally, an automated data selection module filters uninformative samples, significantly improving efficiency and scalability for large-scale datasets. Extensive experiments on UAVs, UGVs, and handheld platforms demonstrate that our method outperforms traditional optimization-based approaches, achieving high-precision calibration even under weak excitation conditions. Our framework simplifies deployment on diverse robotic platforms by eliminating the need for high-quality initial extrinsics and enabling calibration from routine operating data. The code is available at https://github.com/APRIL-ZJU/learn-to-calibrate.
STiL: Semi-supervised Tabular-Image Learning for Comprehensive Task-Relevant Information Exploration in Multimodal Classification
Mar 08, 2025Multimodal image-tabular learning is gaining attention, yet it faces challenges due to limited labeled data. While earlier work has applied self-supervised learning (SSL) to unlabeled data, its task-agnostic nature often results in learning suboptimal features for downstream tasks. Semi-supervised learning (SemiSL), which combines labeled and unlabeled data, offers a promising solution. However, existing multimodal SemiSL methods typically focus on unimodal or modality-shared features, ignoring valuable task-relevant modality-specific information, leading to a Modality Information Gap. In this paper, we propose STiL, a novel SemiSL tabular-image framework that addresses this gap by comprehensively exploring task-relevant information. STiL features a new disentangled contrastive consistency module to learn cross-modal invariant representations of shared information while retaining modality-specific information via disentanglement. We also propose a novel consensus-guided pseudo-labeling strategy to generate reliable pseudo-labels based on classifier consensus, along with a new prototype-guided label smoothing technique to refine pseudo-label quality with prototype embeddings, thereby enhancing task-relevant information learning in unlabeled data. Experiments on natural and medical image datasets show that STiL outperforms the state-of-the-art supervised/SSL/SemiSL image/multimodal approaches. Our code is publicly available.
SGSR: Structure-Guided Multi-Contrast MRI Super-Resolution via Spatio-Frequency Co-Query Attention
Aug 06, 2024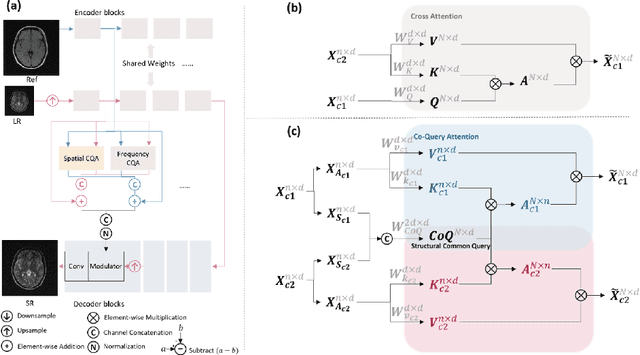
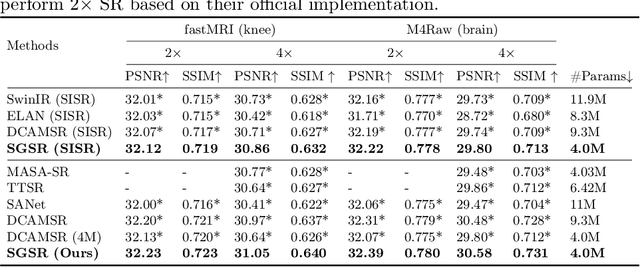
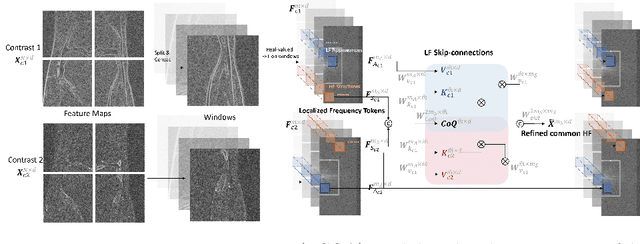
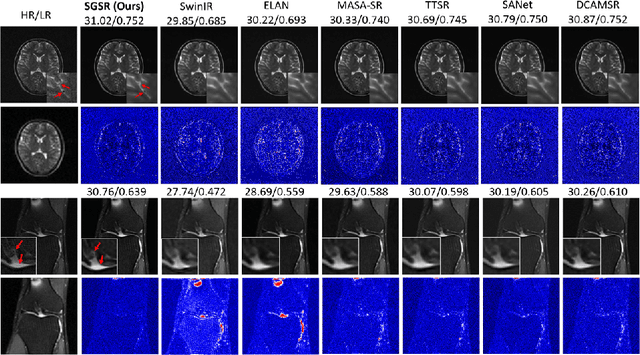
Magnetic Resonance Imaging (MRI) is a leading diagnostic modality for a wide range of exams, where multiple contrast images are often acquired for characterizing different tissues. However, acquiring high-resolution MRI typically extends scan time, which can introduce motion artifacts. Super-resolution of MRI therefore emerges as a promising approach to mitigate these challenges. Earlier studies have investigated the use of multiple contrasts for MRI super-resolution (MCSR), whereas majority of them did not fully exploit the rich contrast-invariant structural information. To fully utilize such crucial prior knowledge of multi-contrast MRI, in this work, we propose a novel structure-guided MCSR (SGSR) framework based on a new spatio-frequency co-query attention (CQA) mechanism. Specifically, CQA performs attention on features of multiple contrasts with a shared structural query, which is particularly designed to extract, fuse, and refine the common structures from different contrasts. We further propose a novel frequency-domain CQA module in addition to the spatial domain, to enable more fine-grained structural refinement. Extensive experiments on fastMRI knee data and low-field brain MRI show that SGSR outperforms state-of-the-art MCSR methods with statistical significance.
CAR: Contrast-Agnostic Deformable Medical Image Registration with Contrast-Invariant Latent Regularization
Aug 03, 2024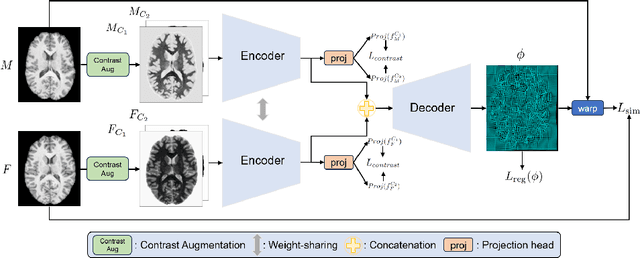

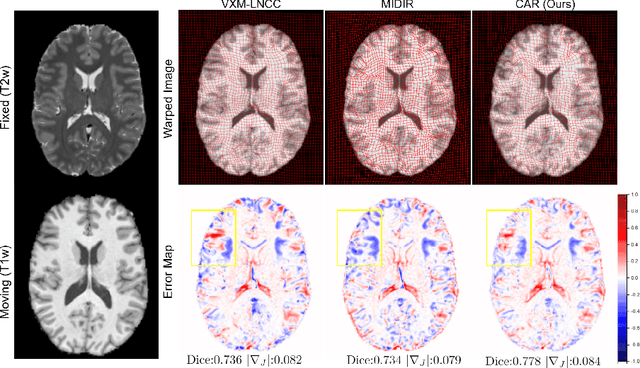

Multi-contrast image registration is a challenging task due to the complex intensity relationships between different imaging contrasts. Conventional image registration methods are typically based on iterative optimizations for each input image pair, which is time-consuming and sensitive to contrast variations. While learning-based approaches are much faster during the inference stage, due to generalizability issues, they typically can only be applied to the fixed contrasts observed during the training stage. In this work, we propose a novel contrast-agnostic deformable image registration framework that can be generalized to arbitrary contrast images, without observing them during training. Particularly, we propose a random convolution-based contrast augmentation scheme, which simulates arbitrary contrasts of images over a single image contrast while preserving their inherent structural information. To ensure that the network can learn contrast-invariant representations for facilitating contrast-agnostic registration, we further introduce contrast-invariant latent regularization (CLR) that regularizes representation in latent space through a contrast invariance loss. Experiments show that CAR outperforms the baseline approaches regarding registration accuracy and also possesses better generalization ability to unseen imaging contrasts. Code is available at \url{https://github.com/Yinsong0510/CAR}.
TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data
Jul 10, 2024



Images and structured tables are essential parts of real-world databases. Though tabular-image representation learning is promising to create new insights, it remains a challenging task, as tabular data is typically heterogeneous and incomplete, presenting significant modality disparities with images. Earlier works have mainly focused on simple modality fusion strategies in complete data scenarios, without considering the missing data issue, and thus are limited in practice. In this paper, we propose TIP, a novel tabular-image pre-training framework for learning multimodal representations robust to incomplete tabular data. Specifically, TIP investigates a novel self-supervised learning (SSL) strategy, including a masked tabular reconstruction task for tackling data missingness, and image-tabular matching and contrastive learning objectives to capture multimodal information. Moreover, TIP proposes a versatile tabular encoder tailored for incomplete, heterogeneous tabular data and a multimodal interaction module for inter-modality representation learning. Experiments are performed on downstream multimodal classification tasks using both natural and medical image datasets. The results show that TIP outperforms state-of-the-art supervised/SSL image/multimodal algorithms in both complete and incomplete data scenarios. Our code is available at https://github.com/siyi-wind/TIP.
MDViT: Multi-domain Vision Transformer for Small Medical Image Segmentation Datasets
Jul 26, 2023
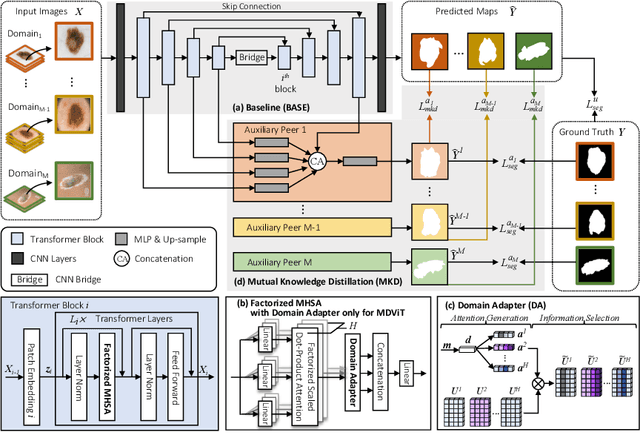
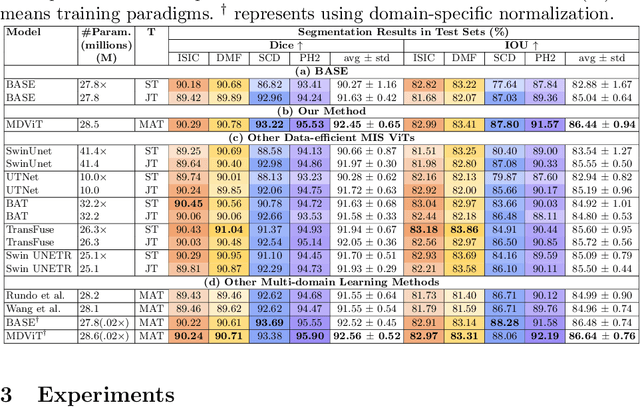
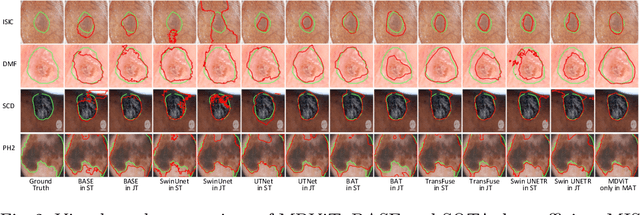
Despite its clinical utility, medical image segmentation (MIS) remains a daunting task due to images' inherent complexity and variability. Vision transformers (ViTs) have recently emerged as a promising solution to improve MIS; however, they require larger training datasets than convolutional neural networks. To overcome this obstacle, data-efficient ViTs were proposed, but they are typically trained using a single source of data, which overlooks the valuable knowledge that could be leveraged from other available datasets. Naivly combining datasets from different domains can result in negative knowledge transfer (NKT), i.e., a decrease in model performance on some domains with non-negligible inter-domain heterogeneity. In this paper, we propose MDViT, the first multi-domain ViT that includes domain adapters to mitigate data-hunger and combat NKT by adaptively exploiting knowledge in multiple small data resources (domains). Further, to enhance representation learning across domains, we integrate a mutual knowledge distillation paradigm that transfers knowledge between a universal network (spanning all the domains) and auxiliary domain-specific branches. Experiments on 4 skin lesion segmentation datasets show that MDViT outperforms state-of-the-art algorithms, with superior segmentation performance and a fixed model size, at inference time, even as more domains are added. Our code is available at https://github.com/siyi-wind/MDViT.
AViT: Adapting Vision Transformers for Small Skin Lesion Segmentation Datasets
Jul 26, 2023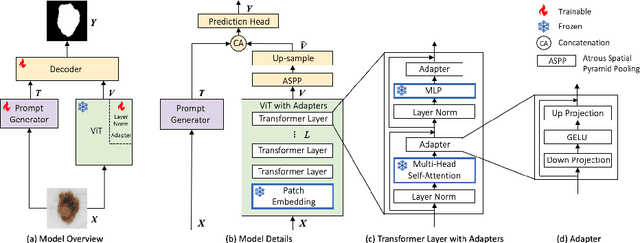
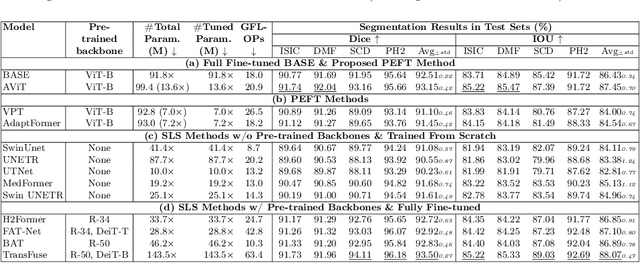
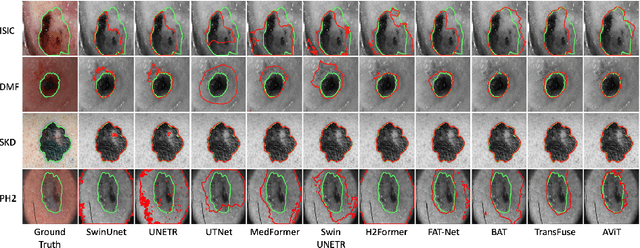
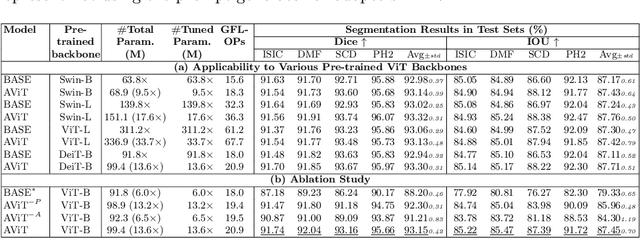
Skin lesion segmentation (SLS) plays an important role in skin lesion analysis. Vision transformers (ViTs) are considered an auspicious solution for SLS, but they require more training data compared to convolutional neural networks (CNNs) due to their inherent parameter-heavy structure and lack of some inductive biases. To alleviate this issue, current approaches fine-tune pre-trained ViT backbones on SLS datasets, aiming to leverage the knowledge learned from a larger set of natural images to lower the amount of skin training data needed. However, fully fine-tuning all parameters of large backbones is computationally expensive and memory intensive. In this paper, we propose AViT, a novel efficient strategy to mitigate ViTs' data-hunger by transferring any pre-trained ViTs to the SLS task. Specifically, we integrate lightweight modules (adapters) within the transformer layers, which modulate the feature representation of a ViT without updating its pre-trained weights. In addition, we employ a shallow CNN as a prompt generator to create a prompt embedding from the input image, which grasps fine-grained information and CNN's inductive biases to guide the segmentation task on small datasets. Our quantitative experiments on 4 skin lesion datasets demonstrate that AViT achieves competitive, and at times superior, performance to SOTA but with significantly fewer trainable parameters. Our code is available at https://github.com/siyi-wind/AViT.
FairDisCo: Fairer AI in Dermatology via Disentanglement Contrastive Learning
Aug 22, 2022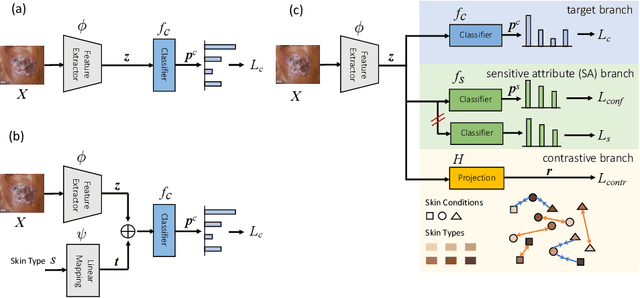
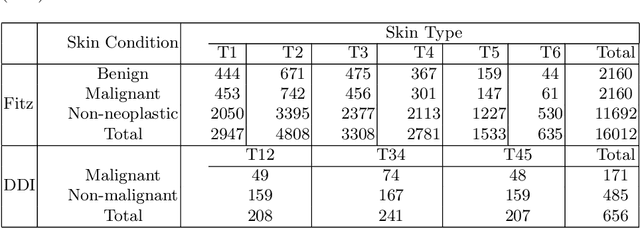
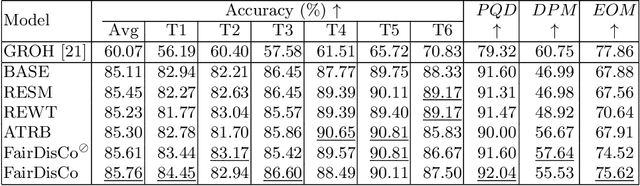
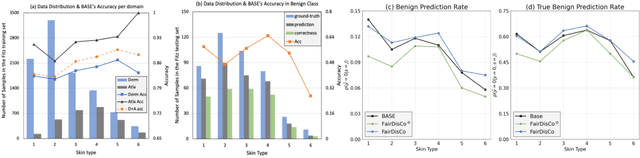
Deep learning models have achieved great success in automating skin lesion diagnosis. However, the ethnic disparity in these models' predictions, where lesions on darker skin types are usually underrepresented and have lower diagnosis accuracy, receives little attention. In this paper, we propose FairDisCo, a disentanglement deep learning framework with contrastive learning that utilizes an additional network branch to remove sensitive attributes, i.e. skin-type information from representations for fairness and another contrastive branch to enhance feature extraction. We compare FairDisCo to three fairness methods, namely, resampling, reweighting, and attribute-aware, on two newly released skin lesion datasets with different skin types: Fitzpatrick17k and Diverse Dermatology Images (DDI). We adapt two fairness-based metrics DPM and EOM for our multiple classes and sensitive attributes task, highlighting the skin-type bias in skin lesion classification. Extensive experimental evaluation demonstrates the effectiveness of FairDisCo, with fairer and superior performance on skin lesion classification tasks.