 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasify: Self-Distillation for Unsupervised Bias Mitigation
Nov 01, 2024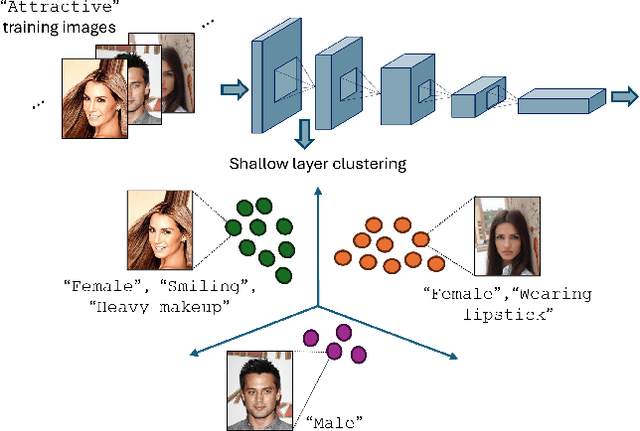
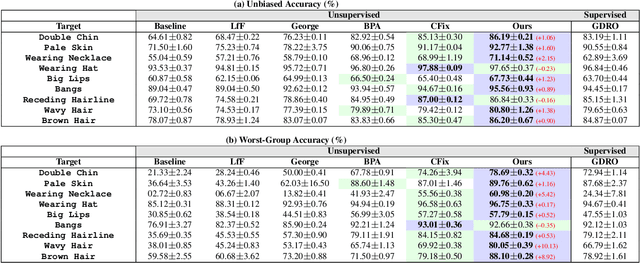
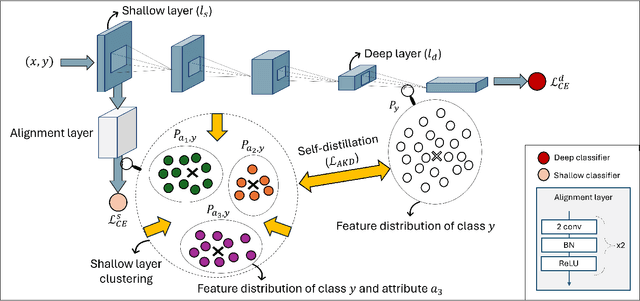

Simplicity bias poses a significant challenge in neural networks, often leading models to favor simpler solutions and inadvertently learn decision rules influenced by spurious correlations. This results in biased models with diminished generalizability. While many current approaches depend on human supervision, obtaining annotations for various bias attributes is often impractical. To address this, we introduce Debiasify, a novel self-distillation approach that requires no prior knowledge about the nature of biases. Our method leverages a new distillation loss to transfer knowledge within the network, from deeper layers containing complex, highly-predictive features to shallower layers with simpler, attribute-conditioned features in an unsupervised manner. This enables Debiasify to learn robust, debiased representations that generalize effectively across diverse biases and datasets, improving both worst-group performance and overall accuracy. Extensive experiments on computer vision and medical imaging benchmarks demonstrate the effectiveness of our approach, significantly outperforming previous unsupervised debiasing methods (e.g., a 10.13% improvement in worst-group accuracy for Wavy Hair classification in CelebA) and achieving comparable or superior performance to supervised approaches. Our code is publicly available at the following link: Debiasify.
BiasPruner: Debiased Continual Learning for Medical Image Classification
Jul 11, 2024Continual Learning (CL) is crucial for enabling networks to dynamically adapt as they learn new tasks sequentially, accommodating new data and classes without catastrophic forgetting. Diverging from conventional perspectives on CL, our paper introduces a new perspective wherein forgetting could actually benefit the sequential learning paradigm. Specifically, we present BiasPruner, a CL framework that intentionally forgets spurious correlations in the training data that could lead to shortcut learning. Utilizing a new bias score that measures the contribution of each unit in the network to learning spurious features, BiasPruner prunes those units with the highest bias scores to form a debiased subnetwork preserved for a given task. As BiasPruner learns a new task, it constructs a new debiased subnetwork, potentially incorporating units from previous subnetworks, which improves adaptation and performance on the new task. During inference, BiasPruner employs a simple task-agnostic approach to select the best debiased subnetwork for predictions. We conduct experiments on three medical datasets for skin lesion classification and chest X-Ray classification and demonstrate that BiasPruner consistently outperforms SOTA CL methods in terms of classification performance and fairness. Our code is available here.
AViT: Adapting Vision Transformers for Small Skin Lesion Segmentation Datasets
Jul 26, 2023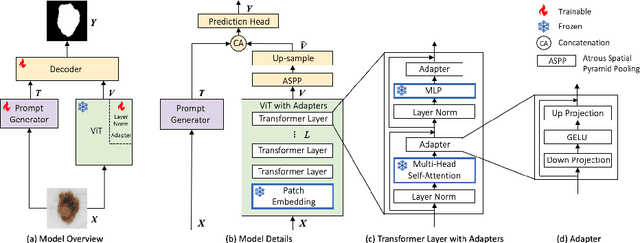
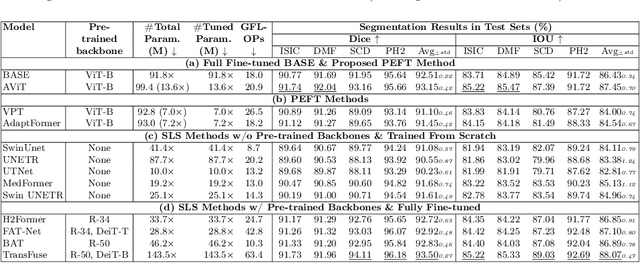
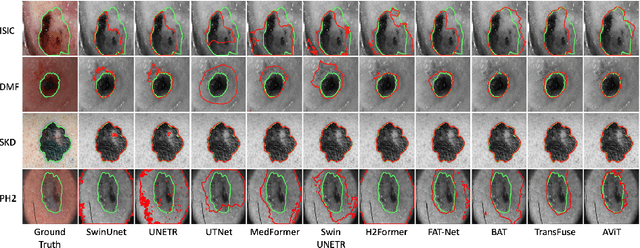
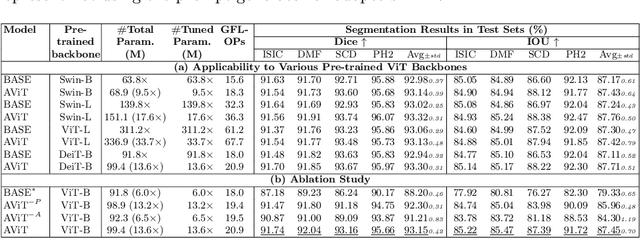
Skin lesion segmentation (SLS) plays an important role in skin lesion analysis. Vision transformers (ViTs) are considered an auspicious solution for SLS, but they require more training data compared to convolutional neural networks (CNNs) due to their inherent parameter-heavy structure and lack of some inductive biases. To alleviate this issue, current approaches fine-tune pre-trained ViT backbones on SLS datasets, aiming to leverage the knowledge learned from a larger set of natural images to lower the amount of skin training data needed. However, fully fine-tuning all parameters of large backbones is computationally expensive and memory intensive. In this paper, we propose AViT, a novel efficient strategy to mitigate ViTs' data-hunger by transferring any pre-trained ViTs to the SLS task. Specifically, we integrate lightweight modules (adapters) within the transformer layers, which modulate the feature representation of a ViT without updating its pre-trained weights. In addition, we employ a shallow CNN as a prompt generator to create a prompt embedding from the input image, which grasps fine-grained information and CNN's inductive biases to guide the segmentation task on small datasets. Our quantitative experiments on 4 skin lesion datasets demonstrate that AViT achieves competitive, and at times superior, performance to SOTA but with significantly fewer trainable parameters. Our code is available at https://github.com/siyi-wind/AViT.
MDViT: Multi-domain Vision Transformer for Small Medical Image Segmentation Datasets
Jul 26, 2023
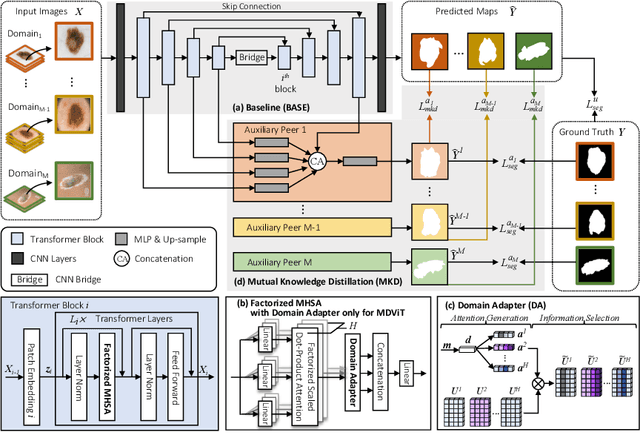
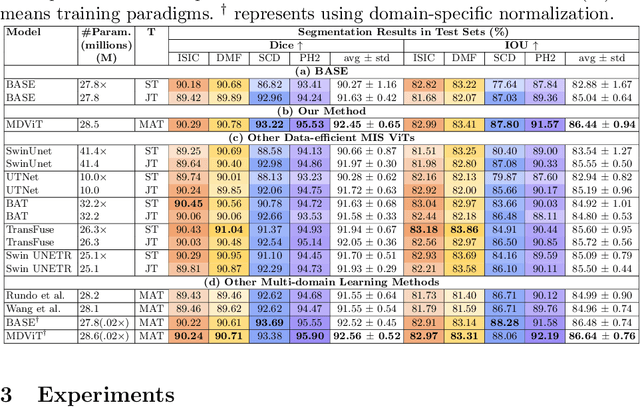
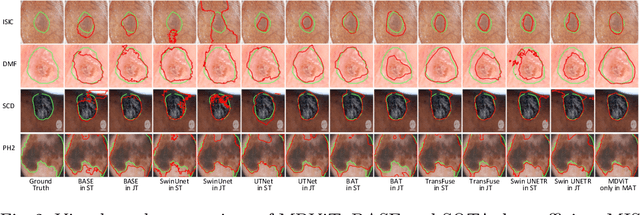
Despite its clinical utility, medical image segmentation (MIS) remains a daunting task due to images' inherent complexity and variability. Vision transformers (ViTs) have recently emerged as a promising solution to improve MIS; however, they require larger training datasets than convolutional neural networks. To overcome this obstacle, data-efficient ViTs were proposed, but they are typically trained using a single source of data, which overlooks the valuable knowledge that could be leveraged from other available datasets. Naivly combining datasets from different domains can result in negative knowledge transfer (NKT), i.e., a decrease in model performance on some domains with non-negligible inter-domain heterogeneity. In this paper, we propose MDViT, the first multi-domain ViT that includes domain adapters to mitigate data-hunger and combat NKT by adaptively exploiting knowledge in multiple small data resources (domains). Further, to enhance representation learning across domains, we integrate a mutual knowledge distillation paradigm that transfers knowledge between a universal network (spanning all the domains) and auxiliary domain-specific branches. Experiments on 4 skin lesion segmentation datasets show that MDViT outperforms state-of-the-art algorithms, with superior segmentation performance and a fixed model size, at inference time, even as more domains are added. Our code is available at https://github.com/siyi-wind/MDViT.
FairDisCo: Fairer AI in Dermatology via Disentanglement Contrastive Learning
Aug 22, 2022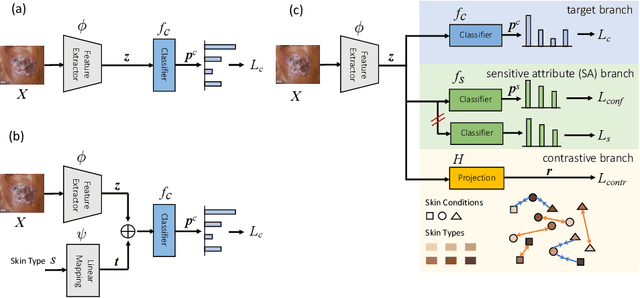
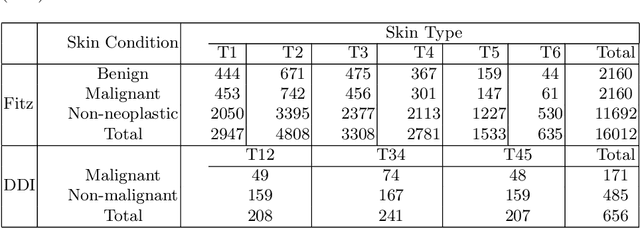
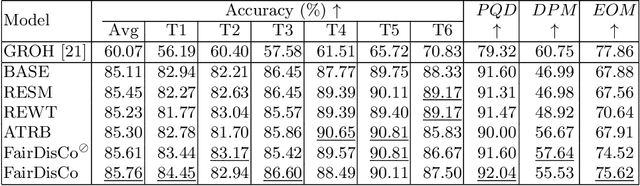
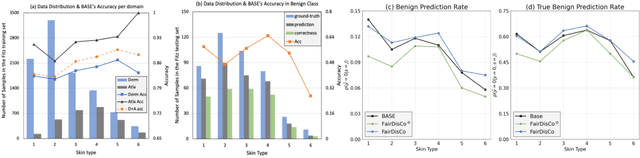
Deep learning models have achieved great success in automating skin lesion diagnosis. However, the ethnic disparity in these models' predictions, where lesions on darker skin types are usually underrepresented and have lower diagnosis accuracy, receives little attention. In this paper, we propose FairDisCo, a disentanglement deep learning framework with contrastive learning that utilizes an additional network branch to remove sensitive attributes, i.e. skin-type information from representations for fairness and another contrastive branch to enhance feature extraction. We compare FairDisCo to three fairness methods, namely, resampling, reweighting, and attribute-aware, on two newly released skin lesion datasets with different skin types: Fitzpatrick17k and Diverse Dermatology Images (DDI). We adapt two fairness-based metrics DPM and EOM for our multiple classes and sensitive attributes task, highlighting the skin-type bias in skin lesion classification. Extensive experimental evaluation demonstrates the effectiveness of FairDisCo, with fairer and superior performance on skin lesion classification tasks.