 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal-in-the-Loop for Learning with Imbalanced Noisy Data
Nov 04, 2024Class imbalance and label noise are pervasive in large-scale datasets, yet much of machine learning research assumes well-labeled, balanced data, which rarely reflects real world conditions. Existing approaches typically address either label noise or class imbalance in isolation, leading to suboptimal results when both issues coexist. In this work, we propose Conformal-in-the-Loop (CitL), a novel training framework that addresses both challenges with a conformal prediction-based approach. CitL evaluates sample uncertainty to adjust weights and prune unreliable examples, enhancing model resilience and accuracy with minimal computational cost. Our extensive experiments include a detailed analysis showing how CitL effectively emphasizes impactful data in noisy, imbalanced datasets. Our results show that CitL consistently boosts model performance, achieving up to a 6.1% increase in classification accuracy and a 5.0 mIoU improvement in segmentation. Our code is publicly available: CitL.
Debiasify: Self-Distillation for Unsupervised Bias Mitigation
Nov 01, 2024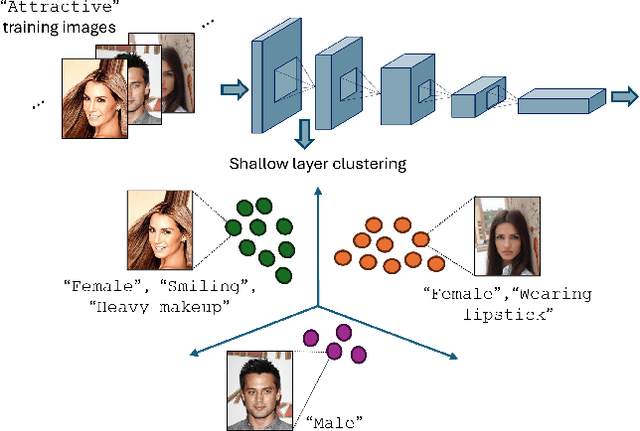
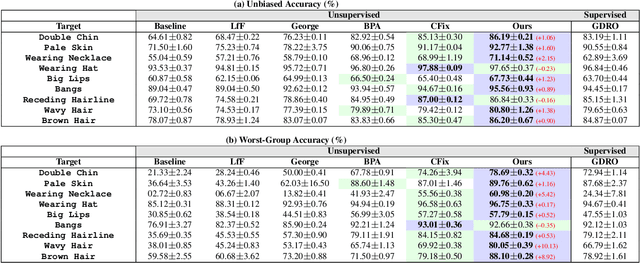
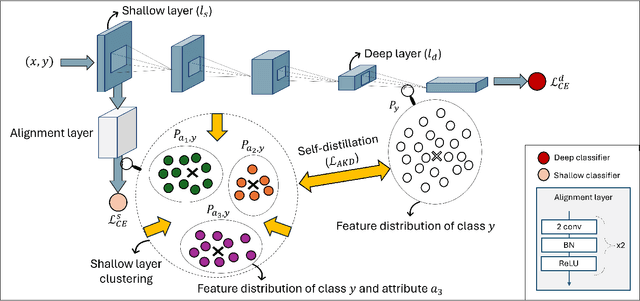

Simplicity bias poses a significant challenge in neural networks, often leading models to favor simpler solutions and inadvertently learn decision rules influenced by spurious correlations. This results in biased models with diminished generalizability. While many current approaches depend on human supervision, obtaining annotations for various bias attributes is often impractical. To address this, we introduce Debiasify, a novel self-distillation approach that requires no prior knowledge about the nature of biases. Our method leverages a new distillation loss to transfer knowledge within the network, from deeper layers containing complex, highly-predictive features to shallower layers with simpler, attribute-conditioned features in an unsupervised manner. This enables Debiasify to learn robust, debiased representations that generalize effectively across diverse biases and datasets, improving both worst-group performance and overall accuracy. Extensive experiments on computer vision and medical imaging benchmarks demonstrate the effectiveness of our approach, significantly outperforming previous unsupervised debiasing methods (e.g., a 10.13% improvement in worst-group accuracy for Wavy Hair classification in CelebA) and achieving comparable or superior performance to supervised approaches. Our code is publicly available at the following link: Debiasify.
Sim-to-Real Domain Adaptation for Deformation Classification
Jul 13, 2024Deformation detection is vital for enabling accurate assessment and prediction of structural changes in materials, ensuring timely and effective interventions to maintain safety and integrity. Automating deformation detection through computer vision is crucial for efficient monitoring, but it faces significant challenges in creating a comprehensive dataset of both deformed and non-deformed objects, which can be difficult to obtain in many scenarios. In this paper, we introduce a novel framework for generating controlled synthetic data that simulates deformed objects. This approach allows for the realistic modeling of object deformations under various conditions. Our framework integrates an intelligent adapter network that facilitates sim-to-real domain adaptation, enhancing classification results without requiring real data from deformed objects. We conduct experiments on domain adaptation and classification tasks and demonstrate that our framework improves sim-to-real classification results compared to simulation baseline.
BiasPruner: Debiased Continual Learning for Medical Image Classification
Jul 11, 2024Continual Learning (CL) is crucial for enabling networks to dynamically adapt as they learn new tasks sequentially, accommodating new data and classes without catastrophic forgetting. Diverging from conventional perspectives on CL, our paper introduces a new perspective wherein forgetting could actually benefit the sequential learning paradigm. Specifically, we present BiasPruner, a CL framework that intentionally forgets spurious correlations in the training data that could lead to shortcut learning. Utilizing a new bias score that measures the contribution of each unit in the network to learning spurious features, BiasPruner prunes those units with the highest bias scores to form a debiased subnetwork preserved for a given task. As BiasPruner learns a new task, it constructs a new debiased subnetwork, potentially incorporating units from previous subnetworks, which improves adaptation and performance on the new task. During inference, BiasPruner employs a simple task-agnostic approach to select the best debiased subnetwork for predictions. We conduct experiments on three medical datasets for skin lesion classification and chest X-Ray classification and demonstrate that BiasPruner consistently outperforms SOTA CL methods in terms of classification performance and fairness. Our code is available here.
Vision Transformers in Domain Adaptation and Generalization: A Study of Robustness
Apr 05, 2024Deep learning models are often evaluated in scenarios where the data distribution is different from those used in the training and validation phases. The discrepancy presents a challenge for accurately predicting the performance of models once deployed on the target distribution. Domain adaptation and generalization are widely recognized as effective strategies for addressing such shifts, thereby ensuring reliable performance. The recent promising results in applying vision transformers in computer vision tasks, coupled with advancements in self-attention mechanisms, have demonstrated their significant potential for robustness and generalization in handling distribution shifts. Motivated by the increased interest from the research community, our paper investigates the deployment of vision transformers in domain adaptation and domain generalization scenarios. For domain adaptation methods, we categorize research into feature-level, instance-level, model-level adaptations, and hybrid approaches, along with other categorizations with respect to diverse strategies for enhancing domain adaptation. Similarly, for domain generalization, we categorize research into multi-domain learning, meta-learning, regularization techniques, and data augmentation strategies. We further classify diverse strategies in research, underscoring the various approaches researchers have taken to address distribution shifts by integrating vision transformers. The inclusion of comprehensive tables summarizing these categories is a distinct feature of our work, offering valuable insights for researchers. These findings highlight the versatility of vision transformers in managing distribution shifts, crucial for real-world applications, especially in critical safety and decision-making scenarios.
Empirical Validation of Conformal Prediction for Trustworthy Skin Lesions Classification
Dec 12, 2023Uncertainty quantification is a pivotal field that contributes to the realization of reliable and robust systems. By providing complementary information, it becomes instrumental in fortifying safe decisions, particularly within high-risk applications. Nevertheless, a comprehensive understanding of the advantages and limitations inherent in various methods within the medical imaging field necessitates further research coupled with in-depth analysis. In this paper, we explore Conformal Prediction, an emerging distribution-free uncertainty quantification technique, along with Monte Carlo Dropout and Evidential Deep Learning methods. Our comprehensive experiments provide a comparative performance analysis for skin lesion classification tasks across the three quantification methods. Furthermore, We present insights into the effectiveness of each method in handling Out-of-Distribution samples from domain-shifted datasets. Based on our experimental findings, our conclusion highlights the robustness and consistent performance of conformal prediction across diverse conditions. This positions it as the preferred choice for decision-making in safety-critical applications.
Learning to Team-Based Navigation: A Review of Deep Reinforcement Learning Techniques for Multi-Agent Pathfinding
Aug 11, 2023Multi-agent pathfinding (MAPF) is a critical field in many large-scale robotic applications, often being the fundamental step in multi-agent systems. The increasing complexity of MAPF in complex and crowded environments, however, critically diminishes the effectiveness of existing solutions. In contrast to other studies that have either presented a general overview of the recent advancements in MAPF or extensively reviewed Deep Reinforcement Learning (DRL) within multi-agent system settings independently, our work presented in this review paper focuses on highlighting the integration of DRL-based approaches in MAPF. Moreover, we aim to bridge the current gap in evaluating MAPF solutions by addressing the lack of unified evaluation metrics and providing comprehensive clarification on these metrics. Finally, our paper discusses the potential of model-based DRL as a promising future direction and provides its required foundational understanding to address current challenges in MAPF. Our objective is to assist readers in gaining insight into the current research direction, providing unified metrics for comparing different MAPF algorithms and expanding their knowledge of model-based DRL to address the existing challenges in MAPF.
Model Compression Methods for YOLOv5: A Review
Jul 21, 2023Over the past few years, extensive research has been devoted to enhancing YOLO object detectors. Since its introduction, eight major versions of YOLO have been introduced with the purpose of improving its accuracy and efficiency. While the evident merits of YOLO have yielded to its extensive use in many areas, deploying it on resource-limited devices poses challenges. To address this issue, various neural network compression methods have been developed, which fall under three main categories, namely network pruning, quantization, and knowledge distillation. The fruitful outcomes of utilizing model compression methods, such as lowering memory usage and inference time, make them favorable, if not necessary, for deploying large neural networks on hardware-constrained edge devices. In this review paper, our focus is on pruning and quantization due to their comparative modularity. We categorize them and analyze the practical results of applying those methods to YOLOv5. By doing so, we identify gaps in adapting pruning and quantization for compressing YOLOv5, and provide future directions in this area for further exploration. Among several versions of YOLO, we specifically choose YOLOv5 for its excellent trade-off between recency and popularity in literature. This is the first specific review paper that surveys pruning and quantization methods from an implementation point of view on YOLOv5. Our study is also extendable to newer versions of YOLO as implementing them on resource-limited devices poses the same challenges that persist even today. This paper targets those interested in the practical deployment of model compression methods on YOLOv5, and in exploring different compression techniques that can be used for subsequent versions of YOLO.