 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMAC-Talk: A Natural Language Extension of the StarCraft Multi-Agent Challenge for Large Language Models
Jun 02, 2026As LLMs become more widely deployed, they are increasingly expected to work alongside other AI agents rather than operating in isolation. Effective coordination in these settings requires agents to communicate, share information and make decisions under uncertainty. We introduce SMAC-Talk, a natural language extension of the StarCraft Multi-Agent Challenge for evaluating LLM-based agents in cooperative multi-agent environments. The environment has several key features such as decentralized control, partial observability and long-horizon decision making. SMAC-Talk includes a natural language communication channel which is used to probe agent coordination and trust. We use this communication channel to construct different evaluation scenarios, including settings with an embedded deceptive communicator that tries to disrupt and deceive allies through communication alone. We provide three agents for benchmarking using 4 models from the Qwen3.5 family and study how reasoning structure, memory and model scale affect coordination between agents. We release SMAC-Talk as an open benchmark to support the research community in developing and evaluating LLM agents in cooperative multi-agent settings.
A Hybrid Intelligent Framework for Uncertainty-Aware Condition Monitoring of Industrial Systems
Apr 10, 2026Hybrid approaches that combine data-driven learning with physics-based insight have shown promise for improving the reliability of industrial condition monitoring. This work develops a hybrid condition monitoring framework that integrates primary sensor measurements, lagged temporal features, and physics-informed residuals derived from nominal surrogate models. Two hybrid integration strategies are examined. The first is a feature-level fusion approach that augments the input space with residual and temporal information. The second is a model-level ensemble approach in which machine learning classifiers trained on different feature types are combined at the decision level. Both hybrid approaches of the condition monitoring framework are evaluated on a continuous stirred-tank reactor (CSTR) benchmark using several machine learning models and ensemble configurations. Both feature-level and model-level hybridization improve diagnostic accuracy relative to single-source baselines, with the best model-level ensemble achieving a 2.9\% improvement over the best baseline ensemble. To assess predictive reliability, conformal prediction is applied to quantify coverage, prediction-set size, and abstention behavior. The results show that hybrid integration enhances uncertainty management, producing smaller and well-calibrated prediction sets at matched coverage levels. These findings demonstrate that lightweight physics-informed residuals, temporal augmentation, and ensemble learning can be combined effectively to improve both accuracy and decision reliability in nonlinear industrial systems.
Sub-Region-Aware Modality Fusion and Adaptive Prompting for Multi-Modal Brain Tumor Segmentation
Jan 22, 2026The successful adaptation of foundation models to multi-modal medical imaging is a critical yet unresolved challenge. Existing models often struggle to effectively fuse information from multiple sources and adapt to the heterogeneous nature of pathological tissues. To address this, we introduce a novel framework for adapting foundation models to multi-modal medical imaging, featuring two key technical innovations: sub-region-aware modality attention and adaptive prompt engineering. The attention mechanism enables the model to learn the optimal combination of modalities for each tumor sub-region, while the adaptive prompting strategy leverages the inherent capabilities of foundation models to refine segmentation accuracy. We validate our framework on the BraTS 2020 brain tumor segmentation dataset, demonstrating that our approach significantly outperforms baseline methods, particularly in the challenging necrotic core sub-region. Our work provides a principled and effective approach to multi-modal fusion and prompting, paving the way for more accurate and robust foundation model-based solutions in medical imaging.
Context Representation via Action-Free Transformer encoder-decoder for Meta Reinforcement Learning
Dec 17, 2025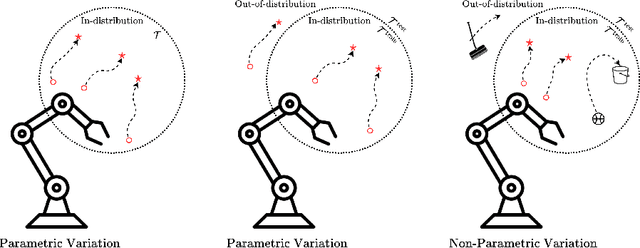



Reinforcement learning (RL) enables robots to operate in uncertain environments, but standard approaches often struggle with poor generalization to unseen tasks. Context-adaptive meta reinforcement learning addresses these limitations by conditioning on the task representation, yet they mostly rely on complete action information in the experience making task inference tightly coupled to a specific policy. This paper introduces Context Representation via Action Free Transformer encoder decoder (CRAFT), a belief model that infers task representations solely from sequences of states and rewards. By removing the dependence on actions, CRAFT decouples task inference from policy optimization, supports modular training, and leverages amortized variational inference for scalable belief updates. Built on a transformer encoder decoder with rotary positional embeddings, the model captures long range temporal dependencies and robustly encodes both parametric and non-parametric task variations. Experiments on the MetaWorld ML-10 robotic manipulation benchmark show that CRAFT achieves faster adaptation, improved generalization, and more effective exploration compared to context adaptive meta--RL baselines. These findings highlight the potential of action-free inference as a foundation for scalable RL in robotic control.
A Cross-Environment and Cross-Embodiment Path Planning Framework via a Conditional Diffusion Model
Oct 21, 2025Path planning for a robotic system in high-dimensional cluttered environments needs to be efficient, safe, and adaptable for different environments and hardware. Conventional methods face high computation time and require extensive parameter tuning, while prior learning-based methods still fail to generalize effectively. The primary goal of this research is to develop a path planning framework capable of generalizing to unseen environments and new robotic manipulators without the need for retraining. We present GADGET (Generalizable and Adaptive Diffusion-Guided Environment-aware Trajectory generation), a diffusion-based planning model that generates joint-space trajectories conditioned on voxelized scene representations as well as start and goal configurations. A key innovation is GADGET's hybrid dual-conditioning mechanism that combines classifier-free guidance via learned scene encoding with classifier-guided Control Barrier Function (CBF) safety shaping, integrating environment awareness with real-time collision avoidance directly in the denoising process. This design supports zero-shot transfer to new environments and robotic embodiments without retraining. Experimental results show that GADGET achieves high success rates with low collision intensity in spherical-obstacle, bin-picking, and shelf environments, with CBF guidance further improving safety. Moreover, comparative evaluations indicate strong performance relative to both sampling-based and learning-based baselines. Furthermore, GADGET provides transferability across Franka Panda, Kinova Gen3 (6/7-DoF), and UR5 robots, and physical execution on a Kinova Gen3 demonstrates its ability to generate safe, collision-free trajectories in real-world settings.
Object Recognition Datasets and Challenges: A Review
Jul 30, 2025Object recognition is among the fundamental tasks in the computer vision applications, paving the path for all other image understanding operations. In every stage of progress in object recognition research, efforts have been made to collect and annotate new datasets to match the capacity of the state-of-the-art algorithms. In recent years, the importance of the size and quality of datasets has been intensified as the utility of the emerging deep network techniques heavily relies on training data. Furthermore, datasets lay a fair benchmarking means for competitions and have proved instrumental to the advancements of object recognition research by providing quantifiable benchmarks for the developed models. Taking a closer look at the characteristics of commonly-used public datasets seems to be an important first step for data-driven and machine learning researchers. In this survey, we provide a detailed analysis of datasets in the highly investigated object recognition areas. More than 160 datasets have been scrutinized through statistics and descriptions. Additionally, we present an overview of the prominent object recognition benchmarks and competitions, along with a description of the metrics widely adopted for evaluation purposes in the computer vision community. All introduced datasets and challenges can be found online at github.com/AbtinDjavadifar/ORDC.
WQLCP: Weighted Adaptive Conformal Prediction for Robust Uncertainty Quantification Under Distribution Shifts
May 26, 2025Conformal prediction (CP) provides a framework for constructing prediction sets with guaranteed coverage, assuming exchangeable data. However, real-world scenarios often involve distribution shifts that violate exchangeability, leading to unreliable coverage and inflated prediction sets. To address this challenge, we first introduce Reconstruction Loss-Scaled Conformal Prediction (RLSCP), which utilizes reconstruction losses derived from a Variational Autoencoder (VAE) as an uncertainty metric to scale score functions. While RLSCP demonstrates performance improvements, mainly resulting in better coverage, it quantifies quantiles based on a fixed calibration dataset without considering the discrepancies between test and train datasets in an unexchangeable setting. In the next step, we propose Weighted Quantile Loss-scaled Conformal Prediction (WQLCP), which refines RLSCP by incorporating a weighted notion of exchangeability, adjusting the calibration quantile threshold based on weights with respect to the ratio of calibration and test loss values. This approach improves the CP-generated prediction set outputs in the presence of distribution shifts. Experiments on large-scale datasets, including ImageNet variants, demonstrate that WQLCP outperforms existing baselines by consistently maintaining coverage while reducing prediction set sizes, providing a robust solution for CP under distribution shifts.
From Flight to Insight: Semantic 3D Reconstruction for Aerial Inspection via Gaussian Splatting and Language-Guided Segmentation
May 23, 2025High-fidelity 3D reconstruction is critical for aerial inspection tasks such as infrastructure monitoring, structural assessment, and environmental surveying. While traditional photogrammetry techniques enable geometric modeling, they lack semantic interpretability, limiting their effectiveness for automated inspection workflows. Recent advances in neural rendering and 3D Gaussian Splatting (3DGS) offer efficient, photorealistic reconstructions but similarly lack scene-level understanding. In this work, we present a UAV-based pipeline that extends Feature-3DGS for language-guided 3D segmentation. We leverage LSeg-based feature fields with CLIP embeddings to generate heatmaps in response to language prompts. These are thresholded to produce rough segmentations, and the highest-scoring point is then used as a prompt to SAM or SAM2 for refined 2D segmentation on novel view renderings. Our results highlight the strengths and limitations of various feature field backbones (CLIP-LSeg, SAM, SAM2) in capturing meaningful structure in large-scale outdoor environments. We demonstrate that this hybrid approach enables flexible, language-driven interaction with photorealistic 3D reconstructions, opening new possibilities for semantic aerial inspection and scene understanding.
Domain Adaptive Skin Lesion Classification via Conformal Ensemble of Vision Transformers
May 21, 2025Exploring the trustworthiness of deep learning models is crucial, especially in critical domains such as medical imaging decision support systems. Conformal prediction has emerged as a rigorous means of providing deep learning models with reliable uncertainty estimates and safety guarantees. However, conformal prediction results face challenges due to the backbone model's struggles in domain-shifted scenarios, such as variations in different sources. To aim this challenge, this paper proposes a novel framework termed Conformal Ensemble of Vision Transformers (CE-ViTs) designed to enhance image classification performance by prioritizing domain adaptation and model robustness, while accounting for uncertainty. The proposed method leverages an ensemble of vision transformer models in the backbone, trained on diverse datasets including HAM10000, Dermofit, and Skin Cancer ISIC datasets. This ensemble learning approach, calibrated through the combined mentioned datasets, aims to enhance domain adaptation through conformal learning. Experimental results underscore that the framework achieves a high coverage rate of 90.38\%, representing an improvement of 9.95\% compared to the HAM10000 model. This indicates a strong likelihood that the prediction set includes the true label compared to singular models. Ensemble learning in CE-ViTs significantly improves conformal prediction performance, increasing the average prediction set size for challenging misclassified samples from 1.86 to 3.075.
Multi-Channel Swin Transformer Framework for Bearing Remaining Useful Life Prediction
May 20, 2025Precise estimation of the Remaining Useful Life (RUL) of rolling bearings is an important consideration to avoid unexpected failures, reduce downtime, and promote safety and efficiency in industrial systems. Complications in degradation trends, noise presence, and the necessity to detect faults in advance make estimation of RUL a challenging task. This paper introduces a novel framework that combines wavelet-based denoising method, Wavelet Packet Decomposition (WPD), and a customized multi-channel Swin Transformer model (MCSFormer) to address these problems. With attention mechanisms incorporated for feature fusion, the model is designed to learn global and local degradation patterns utilizing hierarchical representations for enhancing predictive performance. Additionally, a customized loss function is developed as a key distinction of this work to differentiate between early and late predictions, prioritizing accurate early detection and minimizing the high operation risks of late predictions. The proposed model was evaluated with the PRONOSTIA dataset using three experiments. Intra-condition experiments demonstrated that MCSFormer outperformed state-of-the-art models, including the Adaptive Transformer, MDAN, and CNN-SRU, achieving 41%, 64%, and 69% lower MAE on average across different operating conditions, respectively. In terms of cross-condition testing, it achieved superior generalization under varying operating conditions compared to the adapted ViT and Swin Transformer. Lastly, the custom loss function effectively reduced late predictions, as evidenced in a 6.3% improvement in the scoring metric while maintaining competitive overall performance. The model's robust noise resistance, generalization capability, and focus on safety make MCSFormer a trustworthy and effective predictive maintenance tool in industrial applications.