 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformers for Preoperative CT-Based Prediction of Histopathologic Chemotherapy Response Score in High-Grade Serous Ovarian Carcinoma
Apr 10, 2026Purpose. High-grade serous ovarian carcinoma (HGSOC) is characterized by pronounced biological and spatial heterogeneity and is frequently diagnosed at an advanced stage. Neoadjuvant chemotherapy (NACT) followed by delayed primary surgery is commonly employed in patients unsuitable for primary cytoreduction. The Chemotherapy Response Score (CRS) is a validated histopathological biomarker of response to NACT, but it is only available postoperatively. In this study, we investigate whether pre-treatment computed tomography (CT) imaging and clinical data can be used to predict CRS as an investigational decision-support adjunct to inform multidisciplinary team (MDT) discussions regarding expected treatment response. Methods. We proposed a 2.5D multimodal deep learning framework that processes lesion-dense omental slices using a pre-trained Vision Transformer encoder and integrates the resulting visual representations with clinical variables through an intermediate fusion module to predict CRS. Results. Our multimodal model, integrating imaging and clinical data, achieved a ROC-AUC of 0.95 alongside 95% accuracy and 80% precision on the internal test cohort (IEO, n=41 patients). On the external test set (OV04, n=70 patients), it achieved a ROC-AUC of 0.68, alongside 67% accuracy and 75% precision. Conclusion. These preliminary results demonstrate the feasibility of transformer-based deep learning for preoperative prediction of CRS in HGSOC using routine clinical data and CT imaging. As an investigational, pre-treatment decision-support tool, this approach may assist MDT discussions by providing early, non-invasive estimates of treatment response.
Open World MRI Reconstruction with Bias-Calibrated Adaptation
Mar 13, 2026Real-world MRI reconstruction systems face the open-world challenge: test data from unseen imaging centers, anatomical structures, or acquisition protocols can differ drastically from training data, causing severe performance degradation. Existing methods struggle with this challenge. To address this, we propose BiasRecon, a bias-calibrated adaptation framework grounded in the minimal intervention principle: preserve what transfers, calibrate what does not. Concretely, BiasRecon formulates open-world adaptation as an alternating optimization framework that jointly optimizes three components: (1) frequency-guided prior calibration that introduces layer-wise calibration variables to selectively modulate frequency-specific features of the pre-trained score network via self-supervised k-space signals, (2) score-based denoising that leverages the calibrated generative prior for high-fidelity image reconstruction, and (3) adaptive regularization that employs Stein's Unbiased Risk Estimator to dynamically balance the prior-measurement trade-off, matching test-time noise characteristics without requiring ground truth. By intervening minimally and precisely through this alternating scheme, BiasRecon achieves robust adaptation with fewer than 100 tunable parameters. Extensive experiments across four datasets demonstrate state-of-the-art performance on open-world reconstruction tasks.
R$^{2}$Seg: Training-Free OOD Medical Tumor Segmentation via Anatomical Reasoning and Statistical Rejection
Nov 16, 2025Foundation models for medical image segmentation struggle under out-of-distribution (OOD) shifts, often producing fragmented false positives on OOD tumors. We introduce R$^{2}$Seg, a training-free framework for robust OOD tumor segmentation that operates via a two-stage Reason-and-Reject process. First, the Reason step employs an LLM-guided anatomical reasoning planner to localize organ anchors and generate multi-scale ROIs. Second, the Reject step applies two-sample statistical testing to candidates generated by a frozen foundation model (BiomedParse) within these ROIs. This statistical rejection filter retains only candidates significantly different from normal tissue, effectively suppressing false positives. Our framework requires no parameter updates, making it compatible with zero-update test-time augmentation and avoiding catastrophic forgetting. On multi-center and multi-modal tumor segmentation benchmarks, R$^{2}$Seg substantially improves Dice, specificity, and sensitivity over strong baselines and the original foundation models. Code are available at https://github.com/Eurekashen/R2Seg.
Integrating Pathology and CT Imaging for Personalized Recurrence Risk Prediction in Renal Cancer
Aug 29, 2025Recurrence risk estimation in clear cell renal cell carcinoma (ccRCC) is essential for guiding postoperative surveillance and treatment. The Leibovich score remains widely used for stratifying distant recurrence risk but offers limited patient-level resolution and excludes imaging information. This study evaluates multimodal recurrence prediction by integrating preoperative computed tomography (CT) and postoperative histopathology whole-slide images (WSIs). A modular deep learning framework with pretrained encoders and Cox-based survival modeling was tested across unimodal, late fusion, and intermediate fusion setups. In a real-world ccRCC cohort, WSI-based models consistently outperformed CT-only models, underscoring the prognostic strength of pathology. Intermediate fusion further improved performance, with the best model (TITAN-CONCH with ResNet-18) approaching the adjusted Leibovich score. Random tie-breaking narrowed the gap between the clinical baseline and learned models, suggesting discretization may overstate individualized performance. Using simple embedding concatenation, radiology added value primarily through fusion. These findings demonstrate the feasibility of foundation model-based multimodal integration for personalized ccRCC risk prediction. Future work should explore more expressive fusion strategies, larger multimodal datasets, and general-purpose CT encoders to better match pathology modeling capacity.
Learning Concept-Driven Logical Rules for Interpretable and Generalizable Medical Image Classification
May 20, 2025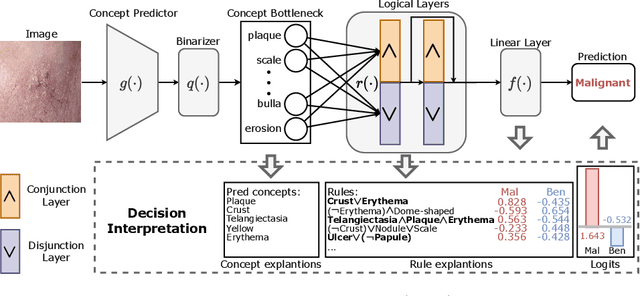
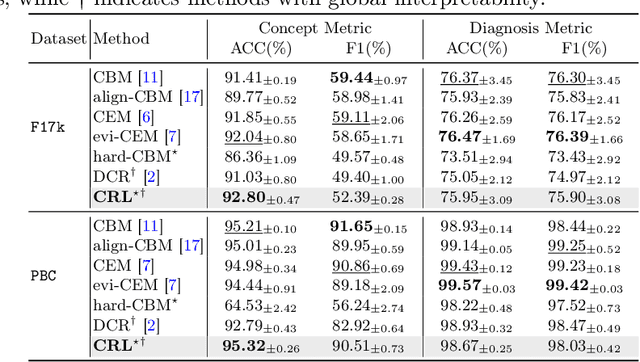
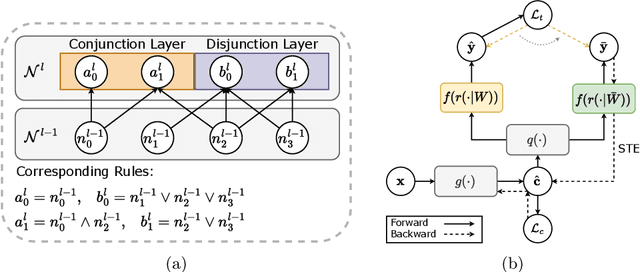
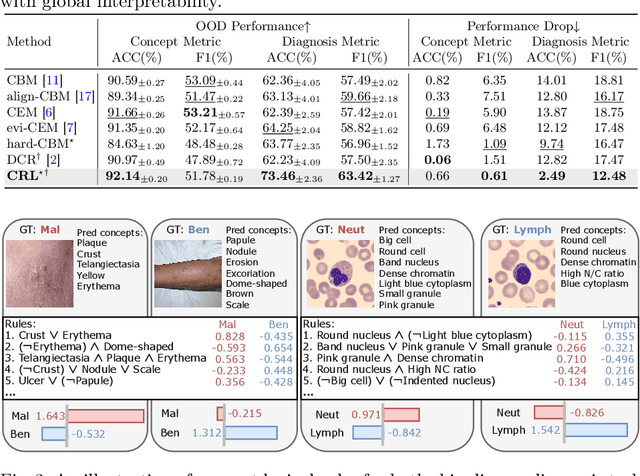
The pursuit of decision safety in clinical applications highlights the potential of concept-based methods in medical imaging. While these models offer active interpretability, they often suffer from concept leakages, where unintended information within soft concept representations undermines both interpretability and generalizability. Moreover, most concept-based models focus solely on local explanations (instance-level), neglecting the global decision logic (dataset-level). To address these limitations, we propose Concept Rule Learner (CRL), a novel framework to learn Boolean logical rules from binarized visual concepts. CRL employs logical layers to capture concept correlations and extract clinically meaningful rules, thereby providing both local and global interpretability. Experiments on two medical image classification tasks show that CRL achieves competitive performance with existing methods while significantly improving generalizability to out-of-distribution data. The code of our work is available at https://github.com/obiyoag/crl.
Empowering Medical Multi-Agents with Clinical Consultation Flow for Dynamic Diagnosis
Mar 19, 2025



Traditional AI-based healthcare systems often rely on single-modal data, limiting diagnostic accuracy due to incomplete information. However, recent advancements in foundation models show promising potential for enhancing diagnosis combining multi-modal information. While these models excel in static tasks, they struggle with dynamic diagnosis, failing to manage multi-turn interactions and often making premature diagnostic decisions due to insufficient persistence in information collection.To address this, we propose a multi-agent framework inspired by consultation flow and reinforcement learning (RL) to simulate the entire consultation process, integrating multiple clinical information for effective diagnosis. Our approach incorporates a hierarchical action set, structured from clinic consultation flow and medical textbook, to effectively guide the decision-making process. This strategy improves agent interactions, enabling them to adapt and optimize actions based on the dynamic state. We evaluated our framework on a public dynamic diagnosis benchmark. The proposed framework evidentially improves the baseline methods and achieves state-of-the-art performance compared to existing foundation model-based methods.
InDeed: Interpretable image deep decomposition with guaranteed generalizability
Jan 02, 2025



Image decomposition aims to analyze an image into elementary components, which is essential for numerous downstream tasks and also by nature provides certain interpretability to the analysis. Deep learning can be powerful for such tasks, but surprisingly their combination with a focus on interpretability and generalizability is rarely explored. In this work, we introduce a novel framework for interpretable deep image decomposition, combining hierarchical Bayesian modeling and deep learning to create an architecture-modularized and model-generalizable deep neural network (DNN). The proposed framework includes three steps: (1) hierarchical Bayesian modeling of image decomposition, (2) transforming the inference problem into optimization tasks, and (3) deep inference via a modularized Bayesian DNN. We further establish a theoretical connection between the loss function and the generalization error bound, which inspires a new test-time adaptation approach for out-of-distribution scenarios. We instantiated the application using two downstream tasks, \textit{i.e.}, image denoising, and unsupervised anomaly detection, and the results demonstrated improved generalizability as well as interpretability of our methods. The source code will be released upon the acceptance of this paper.
Trustworthy Contrast-enhanced Brain MRI Synthesis
Jul 10, 2024



Contrast-enhanced brain MRI (CE-MRI) is a valuable diagnostic technique but may pose health risks and incur high costs. To create safer alternatives, multi-modality medical image translation aims to synthesize CE-MRI images from other available modalities. Although existing methods can generate promising predictions, they still face two challenges, i.e., exhibiting over-confidence and lacking interpretability on predictions. To address the above challenges, this paper introduces TrustI2I, a novel trustworthy method that reformulates multi-to-one medical image translation problem as a multimodal regression problem, aiming to build an uncertainty-aware and reliable system. Specifically, our method leverages deep evidential regression to estimate prediction uncertainties and employs an explicit intermediate and late fusion strategy based on the Mixture of Normal Inverse Gamma (MoNIG) distribution, enhancing both synthesis quality and interpretability. Additionally, we incorporate uncertainty calibration to improve the reliability of uncertainty. Validation on the BraTS2018 dataset demonstrates that our approach surpasses current methods, producing higher-quality images with rational uncertainty estimation.
Multi-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024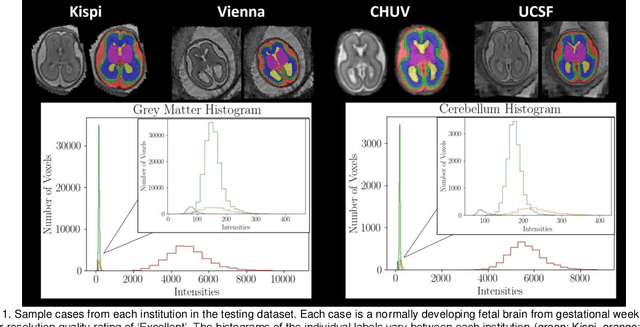
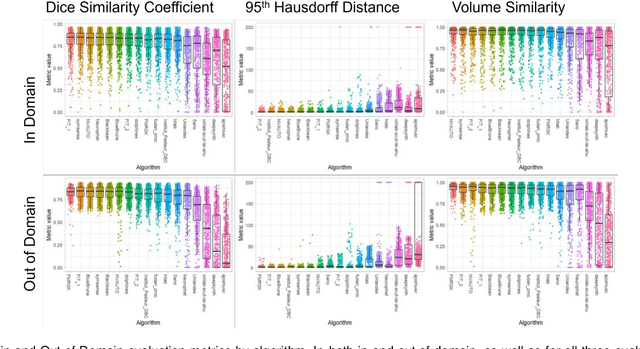
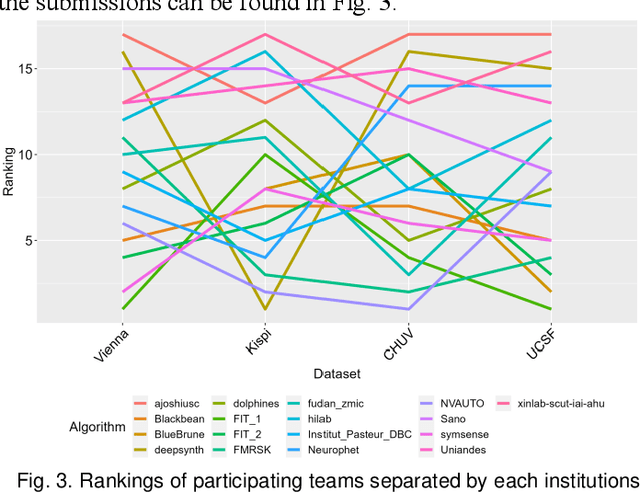
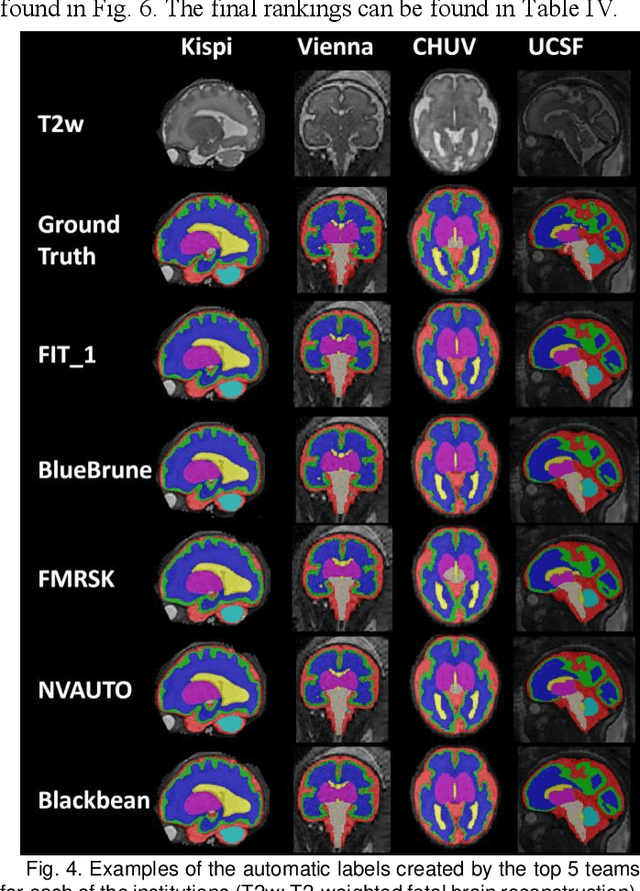
Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
BayeSeg: Bayesian Modeling for Medical Image Segmentation with Interpretable Generalizability
Mar 03, 2023Due to the cross-domain distribution shift aroused from diverse medical imaging systems, many deep learning segmentation methods fail to perform well on unseen data, which limits their real-world applicability. Recent works have shown the benefits of extracting domain-invariant representations on domain generalization. However, the interpretability of domain-invariant features remains a great challenge. To address this problem, we propose an interpretable Bayesian framework (BayeSeg) through Bayesian modeling of image and label statistics to enhance model generalizability for medical image segmentation. Specifically, we first decompose an image into a spatial-correlated variable and a spatial-variant variable, assigning hierarchical Bayesian priors to explicitly force them to model the domain-stable shape and domain-specific appearance information respectively. Then, we model the segmentation as a locally smooth variable only related to the shape. Finally, we develop a variational Bayesian framework to infer the posterior distributions of these explainable variables. The framework is implemented with neural networks, and thus is referred to as deep Bayesian segmentation. Quantitative and qualitative experimental results on prostate segmentation and cardiac segmentation tasks have shown the effectiveness of our proposed method. Moreover, we investigated the interpretability of BayeSeg by explaining the posteriors and analyzed certain factors that affect the generalization ability through further ablation studies. Our code will be released via https://zmiclab.github.io/projects.html, once the manuscript is accepted for publication.