 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Concept-Driven Logical Rules for Interpretable and Generalizable Medical Image Classification
May 20, 2025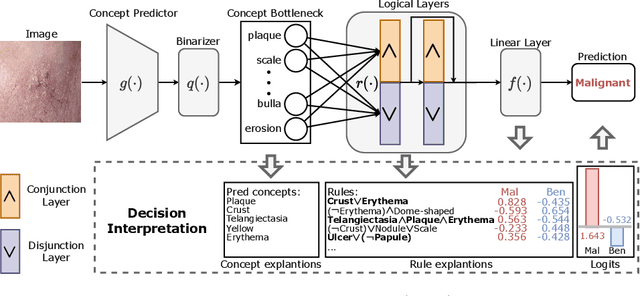
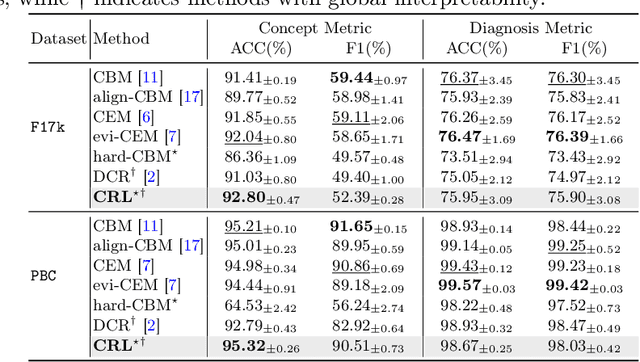
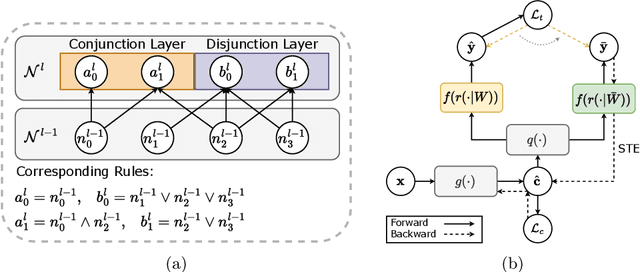
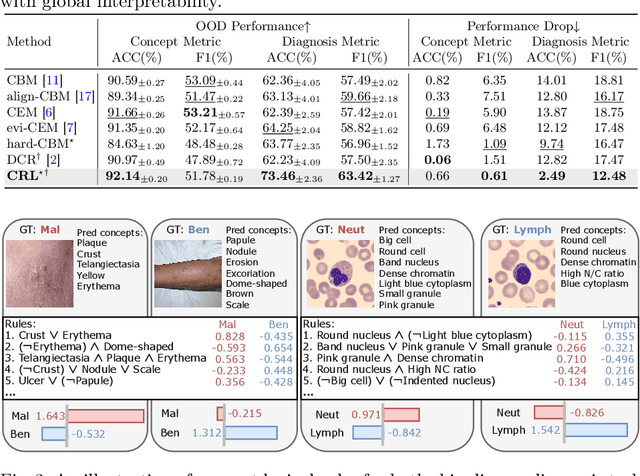
The pursuit of decision safety in clinical applications highlights the potential of concept-based methods in medical imaging. While these models offer active interpretability, they often suffer from concept leakages, where unintended information within soft concept representations undermines both interpretability and generalizability. Moreover, most concept-based models focus solely on local explanations (instance-level), neglecting the global decision logic (dataset-level). To address these limitations, we propose Concept Rule Learner (CRL), a novel framework to learn Boolean logical rules from binarized visual concepts. CRL employs logical layers to capture concept correlations and extract clinically meaningful rules, thereby providing both local and global interpretability. Experiments on two medical image classification tasks show that CRL achieves competitive performance with existing methods while significantly improving generalizability to out-of-distribution data. The code of our work is available at https://github.com/obiyoag/crl.
Evidential Concept Embedding Models: Towards Reliable Concept Explanations for Skin Disease Diagnosis
Jun 27, 2024Due to the high stakes in medical decision-making, there is a compelling demand for interpretable deep learning methods in medical image analysis. Concept Bottleneck Models (CBM) have emerged as an active interpretable framework incorporating human-interpretable concepts into decision-making. However, their concept predictions may lack reliability when applied to clinical diagnosis, impeding concept explanations' quality. To address this, we propose an evidential Concept Embedding Model (evi-CEM), which employs evidential learning to model the concept uncertainty. Additionally, we offer to leverage the concept uncertainty to rectify concept misalignments that arise when training CBMs using vision-language models without complete concept supervision. With the proposed methods, we can enhance concept explanations' reliability for both supervised and label-efficient settings. Furthermore, we introduce concept uncertainty for effective test-time intervention. Our evaluation demonstrates that evi-CEM achieves superior performance in terms of concept prediction, and the proposed concept rectification effectively mitigates concept misalignments for label-efficient training. Our code is available at https://github.com/obiyoag/evi-CEM.
MERIT: Multi-view Evidential learning for Reliable and Interpretable liver fibrosis sTaging
May 05, 2024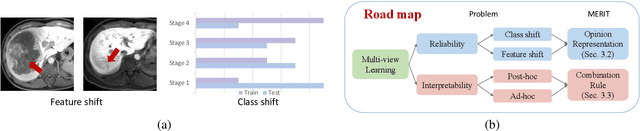

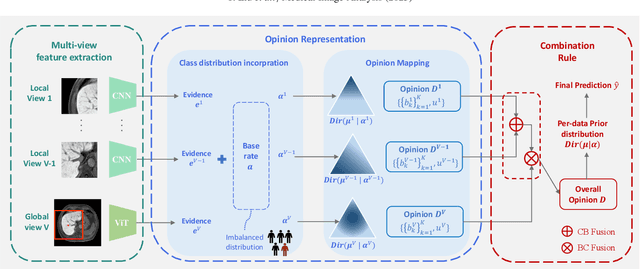
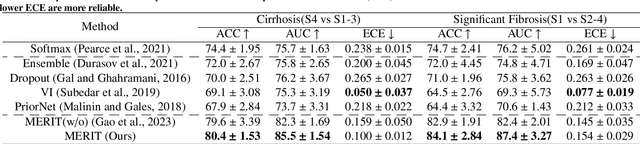
Accurate staging of liver fibrosis from magnetic resonance imaging (MRI) is crucial in clinical practice. While conventional methods often focus on a specific sub-region, multi-view learning captures more information by analyzing multiple patches simultaneously. However, previous multi-view approaches could not typically calculate uncertainty by nature, and they generally integrate features from different views in a black-box fashion, hence compromising reliability as well as interpretability of the resulting models. In this work, we propose a new multi-view method based on evidential learning, referred to as MERIT, which tackles the two challenges in a unified framework. MERIT enables uncertainty quantification of the predictions to enhance reliability, and employs a logic-based combination rule to improve interpretability. Specifically, MERIT models the prediction from each sub-view as an opinion with quantified uncertainty under the guidance of the subjective logic theory. Furthermore, a distribution-aware base rate is introduced to enhance performance, particularly in scenarios involving class distribution shifts. Finally, MERIT adopts a feature-specific combination rule to explicitly fuse multi-view predictions, thereby enhancing interpretability. Results have showcased the effectiveness of the proposed MERIT, highlighting the reliability and offering both ad-hoc and post-hoc interpretability. They also illustrate that MERIT can elucidate the significance of each view in the decision-making process for liver fibrosis staging.
A Reliable and Interpretable Framework of Multi-view Learning for Liver Fibrosis Staging
Jun 21, 2023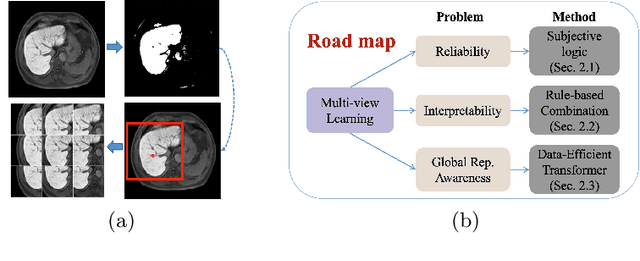
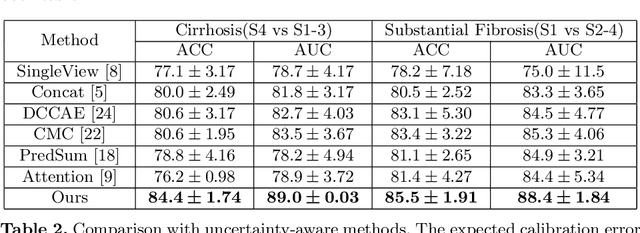
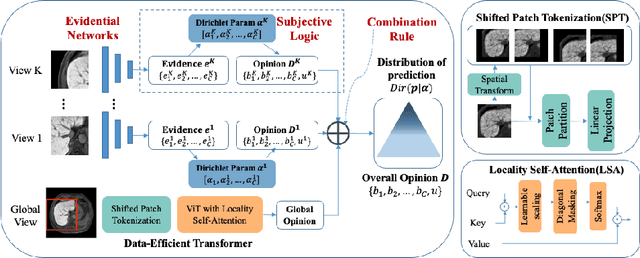
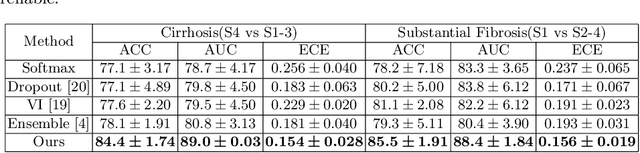
Staging of liver fibrosis is important in the diagnosis and treatment planning of patients suffering from liver diseases. Current deep learning-based methods using abdominal magnetic resonance imaging (MRI) usually take a sub-region of the liver as an input, which nevertheless could miss critical information. To explore richer representations, we formulate this task as a multi-view learning problem and employ multiple sub-regions of the liver. Previously, features or predictions are usually combined in an implicit manner, and uncertainty-aware methods have been proposed. However, these methods could be challenged to capture cross-view representations, which can be important in the accurate prediction of staging. Therefore, we propose a reliable multi-view learning method with interpretable combination rules, which can model global representations to improve the accuracy of predictions. Specifically, the proposed method estimates uncertainties based on subjective logic to improve reliability, and an explicit combination rule is applied based on Dempster-Shafer's evidence theory with good power of interpretability. Moreover, a data-efficient transformer is introduced to capture representations in the global view. Results evaluated on enhanced MRI data show that our method delivers superior performance over existing multi-view learning methods.
Unsupervised Cardiac Segmentation Utilizing Synthesized Images from Anatomical Labels
Jan 15, 2023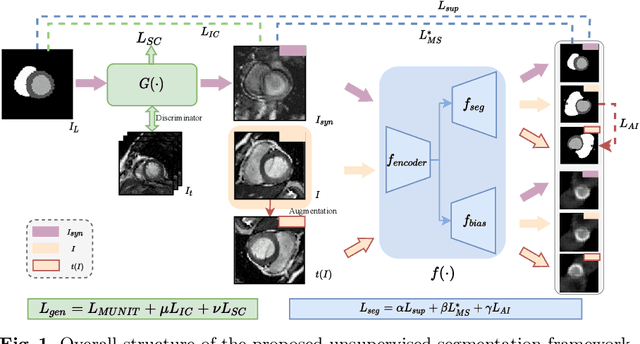
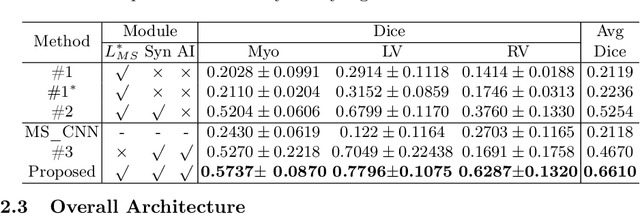


Cardiac segmentation is in great demand for clinical practice. Due to the enormous labor of manual delineation, unsupervised segmentation is desired. The ill-posed optimization problem of this task is inherently challenging, requiring well-designed constraints. In this work, we propose an unsupervised framework for multi-class segmentation with both intensity and shape constraints. Firstly, we extend a conventional non-convex energy function as an intensity constraint and implement it with U-Net. For shape constraint, synthetic images are generated from anatomical labels via image-to-image translation, as shape supervision for the segmentation network. Moreover, augmentation invariance is applied to facilitate the segmentation network to learn the latent features in terms of shape. We evaluated the proposed framework using the public datasets from MICCAI2019 MSCMR Challenge and achieved promising results on cardiac MRIs with Dice scores of 0.5737, 0.7796, and 0.6287 in Myo, LV, and RV, respectively.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Decoupling Predictions in Distributed Learning for Multi-Center Left Atrial MRI Segmentation
Jun 10, 2022


Distributed learning has shown great potential in medical image analysis. It allows to use multi-center training data with privacy protection. However, data distributions in local centers can vary from each other due to different imaging vendors, and annotation protocols. Such variation degrades the performance of learning-based methods. To mitigate the influence, two groups of methods have been proposed for different aims, i.e., the global methods and the personalized methods. The former are aimed to improve the performance of a single global model for all test data from unseen centers (known as generic data); while the latter target multiple models for each center (denoted as local data). However, little has been researched to achieve both goals simultaneously. In this work, we propose a new framework of distributed learning that bridges the gap between two groups, and improves the performance for both generic and local data. Specifically, our method decouples the predictions for generic data and local data, via distribution-conditioned adaptation matrices. Results on multi-center left atrial (LA) MRI segmentation showed that our method demonstrated superior performance over existing methods on both generic and local data. Our code is available at https://github.com/key1589745/decouple_predict