 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlasticine: A Traceable Diffusion Model for Medical Image Translation
Dec 20, 2025Domain gaps arising from variations in imaging devices and population distributions pose significant challenges for machine learning in medical image analysis. Existing image-to-image translation methods primarily aim to learn mappings between domains, often generating diverse synthetic data with variations in anatomical scale and shape, but they usually overlook spatial correspondence during the translation process. For clinical applications, traceability, defined as the ability to provide pixel-level correspondences between original and translated images, is equally important. This property enhances clinical interpretability but has been largely overlooked in previous approaches. To address this gap, we propose Plasticine, which is, to the best of our knowledge, the first end-to-end image-to-image translation framework explicitly designed with traceability as a core objective. Our method combines intensity translation and spatial transformation within a denoising diffusion framework. This design enables the generation of synthetic images with interpretable intensity transitions and spatially coherent deformations, supporting pixel-wise traceability throughout the translation process.
MCM: Mamba-based Cardiac Motion Tracking using Sequential Images in MRI
Jul 23, 2025Myocardial motion tracking is important for assessing cardiac function and diagnosing cardiovascular diseases, for which cine cardiac magnetic resonance (CMR) has been established as the gold standard imaging modality. Many existing methods learn motion from single image pairs consisting of a reference frame and a randomly selected target frame from the cardiac cycle. However, these methods overlook the continuous nature of cardiac motion and often yield inconsistent and non-smooth motion estimations. In this work, we propose a novel Mamba-based cardiac motion tracking network (MCM) that explicitly incorporates target image sequence from the cardiac cycle to achieve smooth and temporally consistent motion tracking. By developing a bi-directional Mamba block equipped with a bi-directional scanning mechanism, our method facilitates the estimation of plausible deformation fields. With our proposed motion decoder that integrates motion information from frames adjacent to the target frame, our method further enhances temporal coherence. Moreover, by taking advantage of Mamba's structured state-space formulation, the proposed method learns the continuous dynamics of the myocardium from sequential images without increasing computational complexity. We evaluate the proposed method on two public datasets. The experimental results demonstrate that the proposed method quantitatively and qualitatively outperforms both conventional and state-of-the-art learning-based cardiac motion tracking methods. The code is available at https://github.com/yjh-0104/MCM.
From Pixels to Polygons: A Survey of Deep Learning Approaches for Medical Image-to-Mesh Reconstruction
May 06, 2025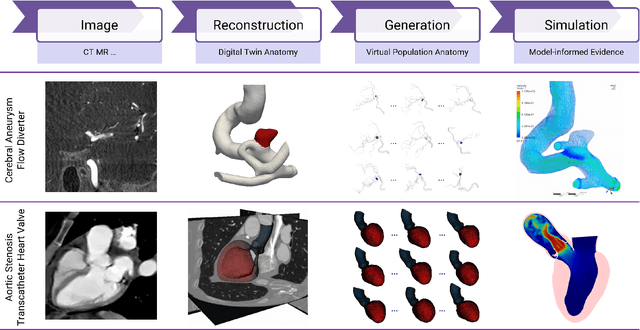
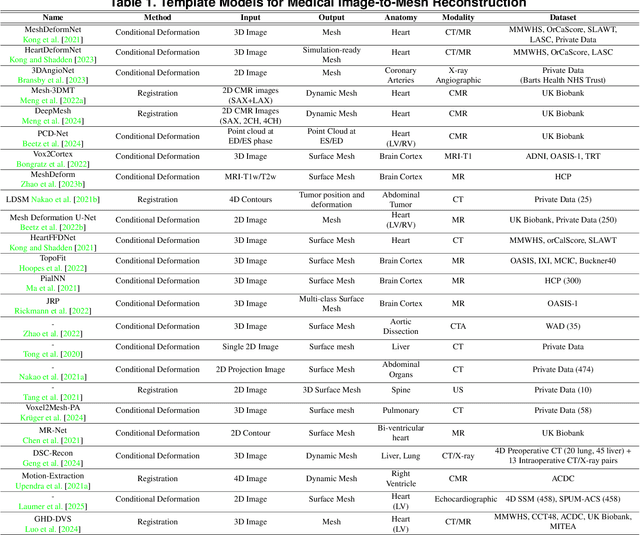
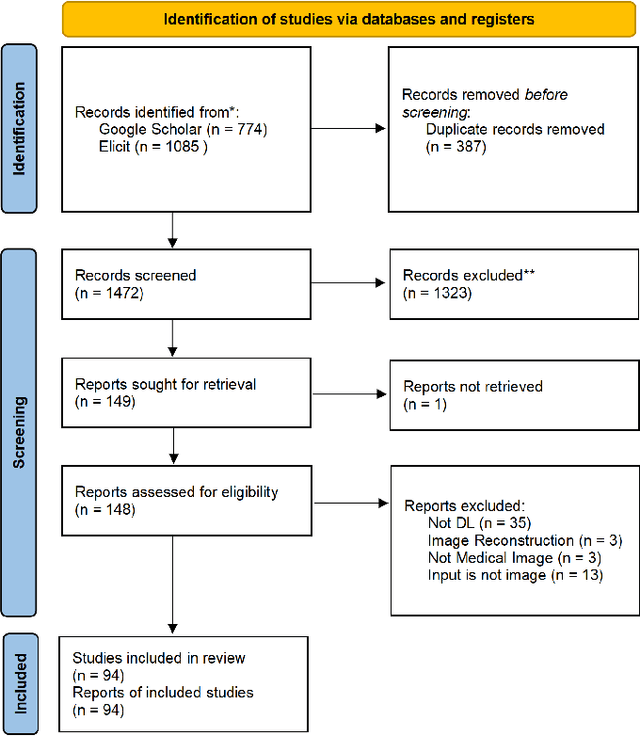
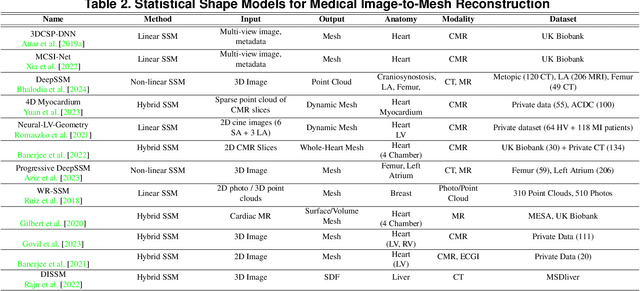
Deep learning-based medical image-to-mesh reconstruction has rapidly evolved, enabling the transformation of medical imaging data into three-dimensional mesh models that are critical in computational medicine and in silico trials for advancing our understanding of disease mechanisms, and diagnostic and therapeutic techniques in modern medicine. This survey systematically categorizes existing approaches into four main categories: template models, statistical models, generative models, and implicit models. Each category is analysed in detail, examining their methodological foundations, strengths, limitations, and applicability to different anatomical structures and imaging modalities. We provide an extensive evaluation of these methods across various anatomical applications, from cardiac imaging to neurological studies, supported by quantitative comparisons using standard metrics. Additionally, we compile and analyze major public datasets available for medical mesh reconstruction tasks and discuss commonly used evaluation metrics and loss functions. The survey identifies current challenges in the field, including requirements for topological correctness, geometric accuracy, and multi-modality integration. Finally, we present promising future research directions in this domain. This systematic review aims to serve as a comprehensive reference for researchers and practitioners in medical image analysis and computational medicine.
OncoReg: Medical Image Registration for Oncological Challenges
Apr 01, 2025In modern cancer research, the vast volume of medical data generated is often underutilised due to challenges related to patient privacy. The OncoReg Challenge addresses this issue by enabling researchers to develop and validate image registration methods through a two-phase framework that ensures patient privacy while fostering the development of more generalisable AI models. Phase one involves working with a publicly available dataset, while phase two focuses on training models on a private dataset within secure hospital networks. OncoReg builds upon the foundation established by the Learn2Reg Challenge by incorporating the registration of interventional cone-beam computed tomography (CBCT) with standard planning fan-beam CT (FBCT) images in radiotherapy. Accurate image registration is crucial in oncology, particularly for dynamic treatment adjustments in image-guided radiotherapy, where precise alignment is necessary to minimise radiation exposure to healthy tissues while effectively targeting tumours. This work details the methodology and data behind the OncoReg Challenge and provides a comprehensive analysis of the competition entries and results. Findings reveal that feature extraction plays a pivotal role in this registration task. A new method emerging from this challenge demonstrated its versatility, while established approaches continue to perform comparably to newer techniques. Both deep learning and classical approaches still play significant roles in image registration, with the combination of methods - particularly in feature extraction - proving most effective.
SACB-Net: Spatial-awareness Convolutions for Medical Image Registration
Mar 25, 2025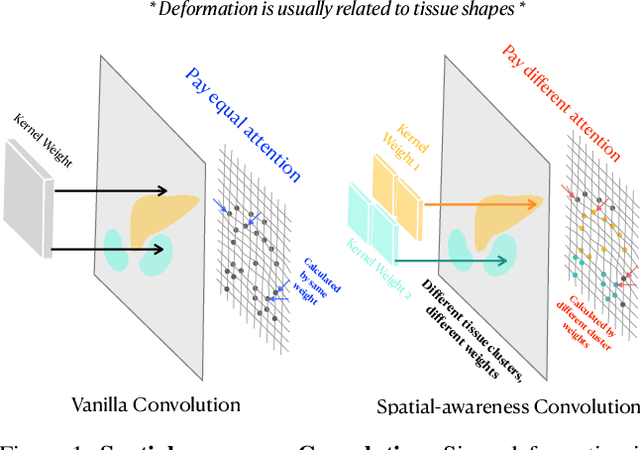
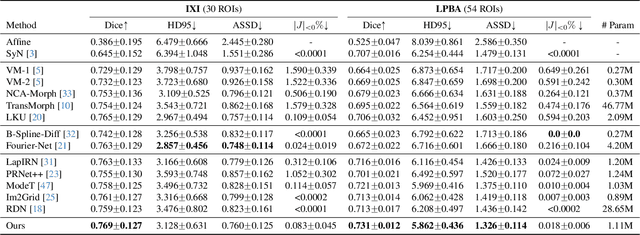
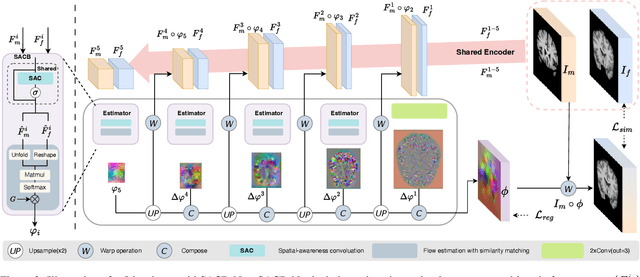
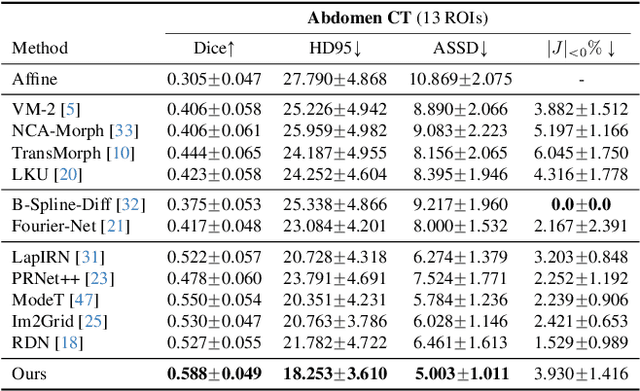
Deep learning-based image registration methods have shown state-of-the-art performance and rapid inference speeds. Despite these advances, many existing approaches fall short in capturing spatially varying information in non-local regions of feature maps due to the reliance on spatially-shared convolution kernels. This limitation leads to suboptimal estimation of deformation fields. In this paper, we propose a 3D Spatial-Awareness Convolution Block (SACB) to enhance the spatial information within feature representations. Our SACB estimates the spatial clusters within feature maps by leveraging feature similarity and subsequently parameterizes the adaptive convolution kernels across diverse regions. This adaptive mechanism generates the convolution kernels (weights and biases) tailored to spatial variations, thereby enabling the network to effectively capture spatially varying information. Building on SACB, we introduce a pyramid flow estimator (named SACB-Net) that integrates SACBs to facilitate multi-scale flow composition, particularly addressing large deformations. Experimental results on the brain IXI and LPBA datasets as well as Abdomen CT datasets demonstrate the effectiveness of SACB and the superiority of SACB-Net over the state-of-the-art learning-based registration methods. The code is available at https://github.com/x-xc/SACB_Net .
Hierarchical Context Transformer for Multi-level Semantic Scene Understanding
Feb 21, 2025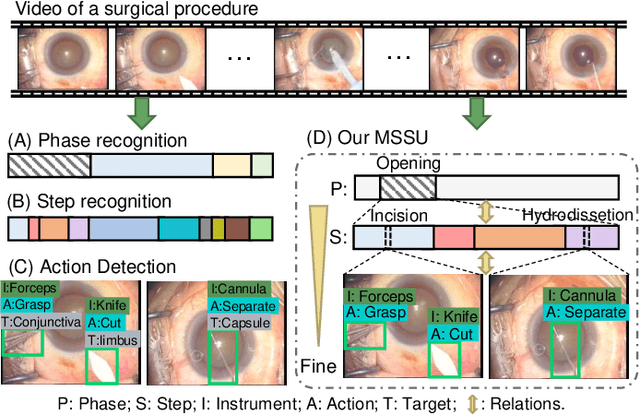

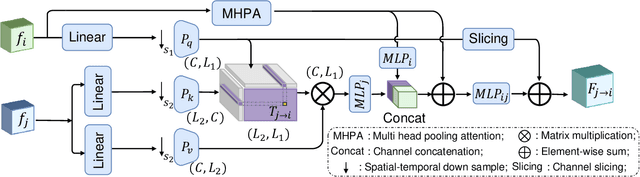

A comprehensive and explicit understanding of surgical scenes plays a vital role in developing context-aware computer-assisted systems in the operating theatre. However, few works provide systematical analysis to enable hierarchical surgical scene understanding. In this work, we propose to represent the tasks set [phase recognition --> step recognition --> action and instrument detection] as multi-level semantic scene understanding (MSSU). For this target, we propose a novel hierarchical context transformer (HCT) network and thoroughly explore the relations across the different level tasks. Specifically, a hierarchical relation aggregation module (HRAM) is designed to concurrently relate entries inside multi-level interaction information and then augment task-specific features. To further boost the representation learning of the different tasks, inter-task contrastive learning (ICL) is presented to guide the model to learn task-wise features via absorbing complementary information from other tasks. Furthermore, considering the computational costs of the transformer, we propose HCT+ to integrate the spatial and temporal adapter to access competitive performance on substantially fewer tunable parameters. Extensive experiments on our cataract dataset and a publicly available endoscopic PSI-AVA dataset demonstrate the outstanding performance of our method, consistently exceeding the state-of-the-art methods by a large margin. The code is available at https://github.com/Aurora-hao/HCT.
LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos
Nov 29, 2024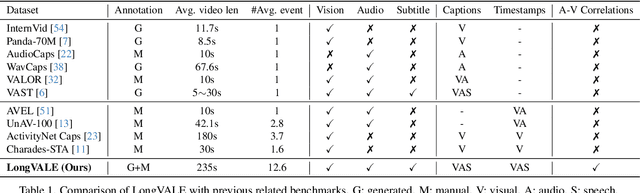
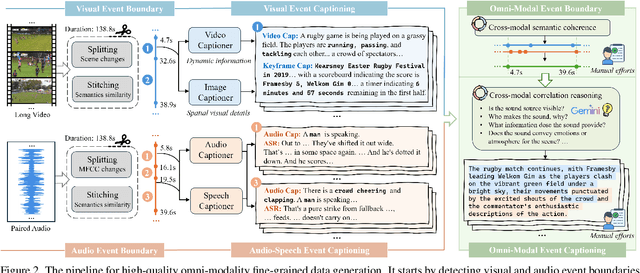
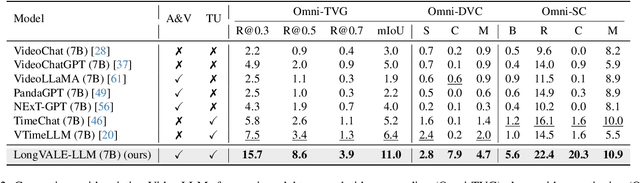
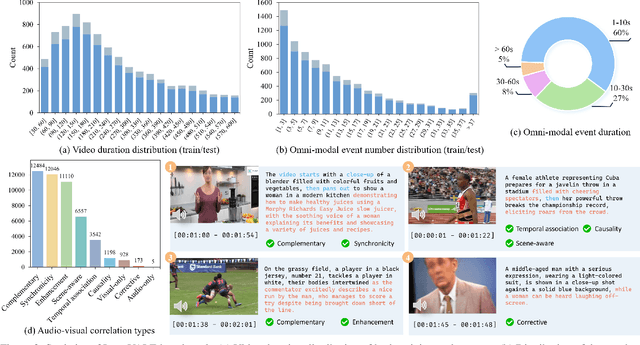
Despite impressive advancements in video understanding, most efforts remain limited to coarse-grained or visual-only video tasks. However, real-world videos encompass omni-modal information (vision, audio, and speech) with a series of events forming a cohesive storyline. The lack of multi-modal video data with fine-grained event annotations and the high cost of manual labeling are major obstacles to comprehensive omni-modality video perception. To address this gap, we propose an automatic pipeline consisting of high-quality multi-modal video filtering, semantically coherent omni-modal event boundary detection, and cross-modal correlation-aware event captioning. In this way, we present LongVALE, the first-ever Vision-Audio-Language Event understanding benchmark comprising 105K omni-modal events with precise temporal boundaries and detailed relation-aware captions within 8.4K high-quality long videos. Further, we build a baseline that leverages LongVALE to enable video large language models (LLMs) for omni-modality fine-grained temporal video understanding for the first time. Extensive experiments demonstrate the effectiveness and great potential of LongVALE in advancing comprehensive multi-modal video understanding.
WiNet: Wavelet-based Incremental Learning for Efficient Medical Image Registration
Jul 18, 2024Deep image registration has demonstrated exceptional accuracy and fast inference. Recent advances have adopted either multiple cascades or pyramid architectures to estimate dense deformation fields in a coarse-to-fine manner. However, due to the cascaded nature and repeated composition/warping operations on feature maps, these methods negatively increase memory usage during training and testing. Moreover, such approaches lack explicit constraints on the learning process of small deformations at different scales, thus lacking explainability. In this study, we introduce a model-driven WiNet that incrementally estimates scale-wise wavelet coefficients for the displacement/velocity field across various scales, utilizing the wavelet coefficients derived from the original input image pair. By exploiting the properties of the wavelet transform, these estimated coefficients facilitate the seamless reconstruction of a full-resolution displacement/velocity field via our devised inverse discrete wavelet transform (IDWT) layer. This approach avoids the complexities of cascading networks or composition operations, making our WiNet an explainable and efficient competitor with other coarse-to-fine methods. Extensive experimental results from two 3D datasets show that our WiNet is accurate and GPU efficient. The code is available at https://github.com/x-xc/WiNet .
UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Apr 04, 2024



Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
Low Rank Groupwise Deformations for Motion Tracking in Cardiac Cine MRI
Mar 24, 2024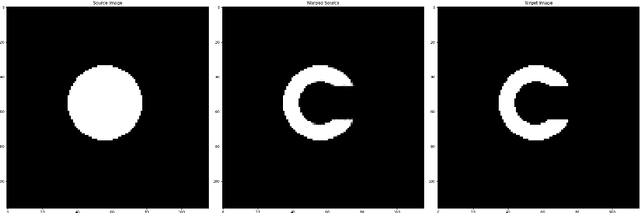



Diffeomorphic image registration is a commonly used method to deform one image to resemble another. While warping a single image to another is useful, it can be advantageous to warp multiple images simultaneously, such as in tracking the motion of the heart across a sequence of images. In this paper, our objective is to propose a novel method capable of registering a group or sequence of images to a target image, resulting in registered images that appear identical and therefore have a low rank. Moreover, we aim for these registered images to closely resemble the target image. Through experimental evidence, we will demonstrate our method's superior efficacy in producing low-rank groupwise deformations compared to other state-of-the-art approaches.