 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardioMorphNet: Cardiac Motion Prediction Using a Shape-Guided Bayesian Recurrent Deep Network
Aug 28, 2025Accurate cardiac motion estimation from cine cardiac magnetic resonance (CMR) images is vital for assessing cardiac function and detecting its abnormalities. Existing methods often struggle to capture heart motion accurately because they rely on intensity-based image registration similarity losses that may overlook cardiac anatomical regions. To address this, we propose CardioMorphNet, a recurrent Bayesian deep learning framework for 3D cardiac shape-guided deformable registration using short-axis (SAX) CMR images. It employs a recurrent variational autoencoder to model spatio-temporal dependencies over the cardiac cycle and two posterior models for bi-ventricular segmentation and motion estimation. The derived loss function from the Bayesian formulation guides the framework to focus on anatomical regions by recursively registering segmentation maps without using intensity-based image registration similarity loss, while leveraging sequential SAX volumes and spatio-temporal features. The Bayesian modelling also enables computation of uncertainty maps for the estimated motion fields. Validated on the UK Biobank dataset by comparing warped mask shapes with ground truth masks, CardioMorphNet demonstrates superior performance in cardiac motion estimation, outperforming state-of-the-art methods. Uncertainty assessment shows that it also yields lower uncertainty values for estimated motion fields in the cardiac region compared with other probabilistic-based cardiac registration methods, indicating higher confidence in its predictions.
From Pixels to Polygons: A Survey of Deep Learning Approaches for Medical Image-to-Mesh Reconstruction
May 06, 2025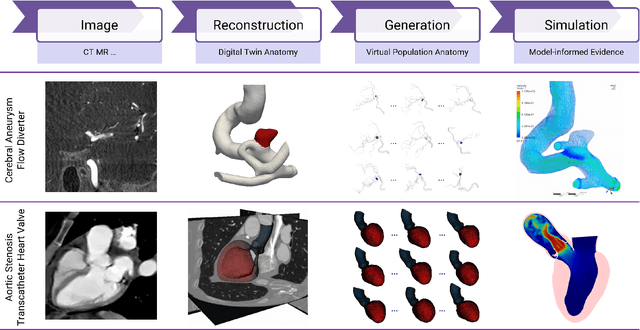
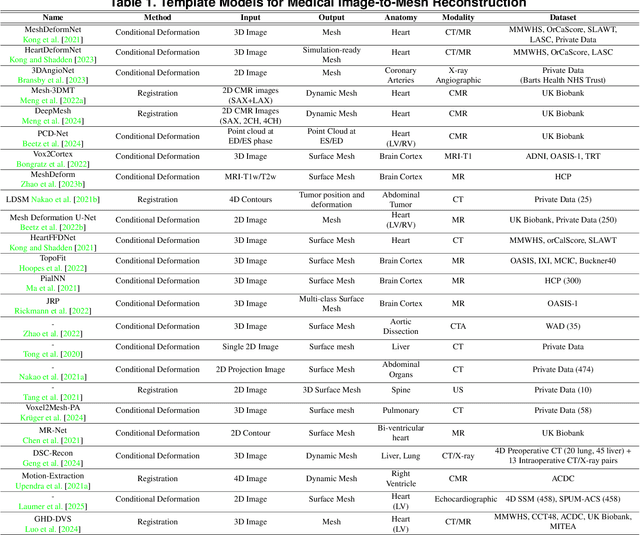
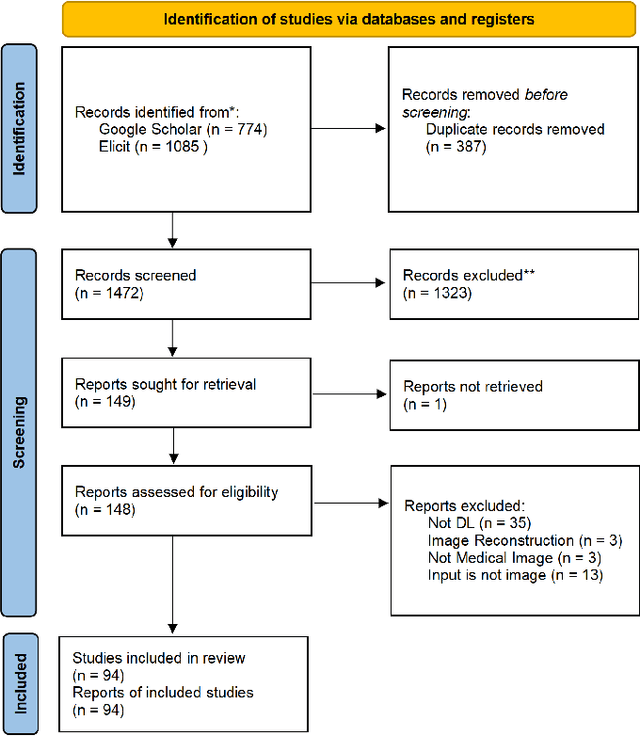
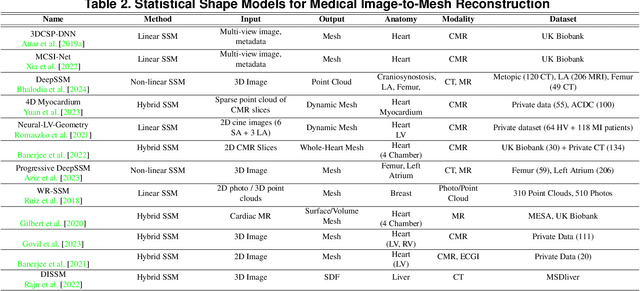
Deep learning-based medical image-to-mesh reconstruction has rapidly evolved, enabling the transformation of medical imaging data into three-dimensional mesh models that are critical in computational medicine and in silico trials for advancing our understanding of disease mechanisms, and diagnostic and therapeutic techniques in modern medicine. This survey systematically categorizes existing approaches into four main categories: template models, statistical models, generative models, and implicit models. Each category is analysed in detail, examining their methodological foundations, strengths, limitations, and applicability to different anatomical structures and imaging modalities. We provide an extensive evaluation of these methods across various anatomical applications, from cardiac imaging to neurological studies, supported by quantitative comparisons using standard metrics. Additionally, we compile and analyze major public datasets available for medical mesh reconstruction tasks and discuss commonly used evaluation metrics and loss functions. The survey identifies current challenges in the field, including requirements for topological correctness, geometric accuracy, and multi-modality integration. Finally, we present promising future research directions in this domain. This systematic review aims to serve as a comprehensive reference for researchers and practitioners in medical image analysis and computational medicine.
Integrating Deep Learning with Fundus and Optical Coherence Tomography for Cardiovascular Disease Prediction
Oct 18, 2024Early identification of patients at risk of cardiovascular diseases (CVD) is crucial for effective preventive care, reducing healthcare burden, and improving patients' quality of life. This study demonstrates the potential of retinal optical coherence tomography (OCT) imaging combined with fundus photographs for identifying future adverse cardiac events. We used data from 977 patients who experienced CVD within a 5-year interval post-image acquisition, alongside 1,877 control participants without CVD, totaling 2,854 subjects. We propose a novel binary classification network based on a Multi-channel Variational Autoencoder (MCVAE), which learns a latent embedding of patients' fundus and OCT images to classify individuals into two groups: those likely to develop CVD in the future and those who are not. Our model, trained on both imaging modalities, achieved promising results (AUROC 0.78 +/- 0.02, accuracy 0.68 +/- 0.002, precision 0.74 +/- 0.02, sensitivity 0.73 +/- 0.02, and specificity 0.68 +/- 0.01), demonstrating its efficacy in identifying patients at risk of future CVD events based on their retinal images. This study highlights the potential of retinal OCT imaging and fundus photographs as cost-effective, non-invasive alternatives for predicting cardiovascular disease risk. The widespread availability of these imaging techniques in optometry practices and hospitals further enhances their potential for large-scale CVD risk screening. Our findings contribute to the development of standardized, accessible methods for early CVD risk identification, potentially improving preventive care strategies and patient outcomes.
* Part of the book series: Lecture Notes in Computer Science ((LNCS,volume 15155))
Deep-Motion-Net: GNN-based volumetric organ shape reconstruction from single-view 2D projections
Jul 09, 2024



We propose Deep-Motion-Net: an end-to-end graph neural network (GNN) architecture that enables 3D (volumetric) organ shape reconstruction from a single in-treatment kV planar X-ray image acquired at any arbitrary projection angle. Estimating and compensating for true anatomical motion during radiotherapy is essential for improving the delivery of planned radiation dose to target volumes while sparing organs-at-risk, and thereby improving the therapeutic ratio. Achieving this using only limited imaging available during irradiation and without the use of surrogate signals or invasive fiducial markers is attractive. The proposed model learns the mesh regression from a patient-specific template and deep features extracted from kV images at arbitrary projection angles. A 2D-CNN encoder extracts image features, and four feature pooling networks fuse these features to the 3D template organ mesh. A ResNet-based graph attention network then deforms the feature-encoded mesh. The model is trained using synthetically generated organ motion instances and corresponding kV images. The latter is generated by deforming a reference CT volume aligned with the template mesh, creating digitally reconstructed radiographs (DRRs) at required projection angles, and DRR-to-kV style transferring with a conditional CycleGAN model. The overall framework was tested quantitatively on synthetic respiratory motion scenarios and qualitatively on in-treatment images acquired over full scan series for liver cancer patients. Overall mean prediction errors for synthetic motion test datasets were 0.16$\pm$0.13 mm, 0.18$\pm$0.19 mm, 0.22$\pm$0.34 mm, and 0.12$\pm$0.11 mm. Mean peak prediction errors were 1.39 mm, 1.99 mm, 3.29 mm, and 1.16 mm.