 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textsc{NaVIDA}: Vision-Language Navigation with Inverse Dynamics Augmentation
Jan 26, 2026Vision-and-Language Navigation (VLN) requires agents to interpret natural language instructions and act coherently in visually rich environments. However, most existing methods rely on reactive state-action mappings without explicitly modeling how actions causally transform subsequent visual observations. Lacking such vision-action causality, agents cannot anticipate the visual changes induced by its own actions, leading to unstable behaviors, weak generalization, and cumulative error along trajectory. To address these issues, we introduce \textsc{NaVIDA} (\textbf{Nav}igation with \textbf{I}nverse \textbf{D}ynamics \textbf{A}ugmentation), a unified VLN framework that couples policy learning with action-grounded visual dynamics and adaptive execution. \textsc{NaVIDA} augments training with chunk-based inverse-dynamics supervision to learn causal relationship between visual changes and corresponding actions. To structure this supervision and extend the effective planning range, \textsc{NaVIDA} employs hierarchical probabilistic action chunking (HPAC), which organizes trajectories into multi-step chunks and provides discriminative, longer-range visual-change cues. To further curb error accumulation and stabilize behavior at inference, an entropy-guided mechanism adaptively sets the execution horizon of action chunks. Extensive experiments show that \textsc{NaVIDA} achieves superior navigation performance compared to state-of-the-art methods with fewer parameters (3B vs. 8B). Real-world robot evaluations further validate the practical feasibility and effectiveness of our approach. Code and data will be available upon acceptance.
CVBench: Evaluating Cross-Video Synergies for Complex Multimodal Understanding and Reasoning
Aug 28, 2025While multimodal large language models (MLLMs) exhibit strong performance on single-video tasks (e.g., video question answering), their ability across multiple videos remains critically underexplored. However, this capability is essential for real-world applications, including multi-camera surveillance and cross-video procedural learning. To bridge this gap, we present CVBench, the first comprehensive benchmark designed to assess cross-video relational reasoning rigorously. CVBench comprises 1,000 question-answer pairs spanning three hierarchical tiers: cross-video object association (identifying shared entities), cross-video event association (linking temporal or causal event chains), and cross-video complex reasoning (integrating commonsense and domain knowledge). Built from five domain-diverse video clusters (e.g., sports, life records), the benchmark challenges models to synthesise information across dynamic visual contexts. Extensive evaluation of 10+ leading MLLMs (including GPT-4o, Gemini-2.0-flash, Qwen2.5-VL) under zero-shot or chain-of-thought prompting paradigms. Key findings reveal stark performance gaps: even top models, such as GPT-4o, achieve only 60% accuracy on causal reasoning tasks, compared to the 91% accuracy of human performance. Crucially, our analysis reveals fundamental bottlenecks inherent in current MLLM architectures, notably deficient inter-video context retention and poor disambiguation of overlapping entities. CVBench establishes a rigorous framework for diagnosing and advancing multi-video reasoning, offering architectural insights for next-generation MLLMs. The data and evaluation code are available at https://github.com/Hokhim2/CVBench.
LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos
Nov 29, 2024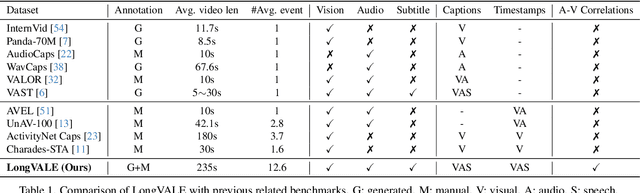
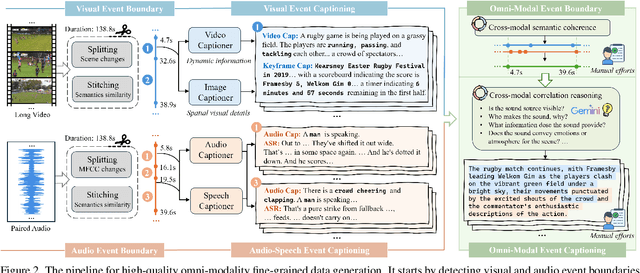
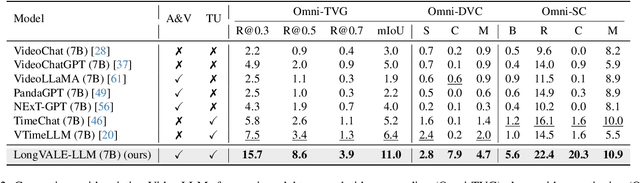
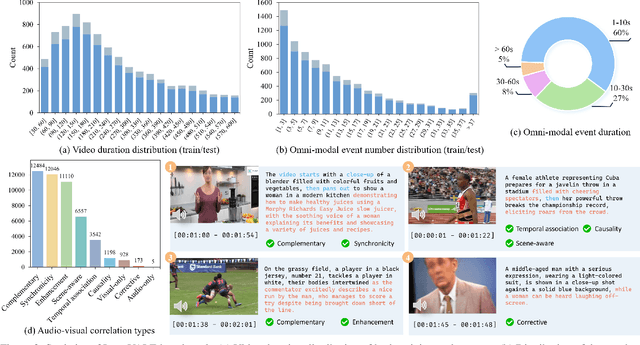
Despite impressive advancements in video understanding, most efforts remain limited to coarse-grained or visual-only video tasks. However, real-world videos encompass omni-modal information (vision, audio, and speech) with a series of events forming a cohesive storyline. The lack of multi-modal video data with fine-grained event annotations and the high cost of manual labeling are major obstacles to comprehensive omni-modality video perception. To address this gap, we propose an automatic pipeline consisting of high-quality multi-modal video filtering, semantically coherent omni-modal event boundary detection, and cross-modal correlation-aware event captioning. In this way, we present LongVALE, the first-ever Vision-Audio-Language Event understanding benchmark comprising 105K omni-modal events with precise temporal boundaries and detailed relation-aware captions within 8.4K high-quality long videos. Further, we build a baseline that leverages LongVALE to enable video large language models (LLMs) for omni-modality fine-grained temporal video understanding for the first time. Extensive experiments demonstrate the effectiveness and great potential of LongVALE in advancing comprehensive multi-modal video understanding.
Sample then Identify: A General Framework for Risk Control and Assessment in Multimodal Large Language Models
Oct 10, 2024



Multimodal Large Language Models (MLLMs) exhibit promising advancements across various tasks, yet they still encounter significant trustworthiness issues. Prior studies apply Split Conformal Prediction (SCP) in language modeling to construct prediction sets with statistical guarantees. However, these methods typically rely on internal model logits or are restricted to multiple-choice settings, which hampers their generalizability and adaptability in dynamic, open-ended environments. In this paper, we introduce TRON, a two-step framework for risk control and assessment, applicable to any MLLM that supports sampling in both open-ended and closed-ended scenarios. TRON comprises two main components: (1) a novel conformal score to sample response sets of minimum size, and (2) a nonconformity score to identify high-quality responses based on self-consistency theory, controlling the error rates by two specific risk levels. Furthermore, we investigate semantic redundancy in prediction sets within open-ended contexts for the first time, leading to a promising evaluation metric for MLLMs based on average set size. Our comprehensive experiments across four Video Question-Answering (VideoQA) datasets utilizing eight MLLMs show that TRON achieves desired error rates bounded by two user-specified risk levels. Additionally, deduplicated prediction sets maintain adaptiveness while being more efficient and stable for risk assessment under different risk levels.
UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Apr 04, 2024



Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
Dense-Localizing Audio-Visual Events in Untrimmed Videos: A Large-Scale Benchmark and Baseline
Mar 24, 2023



Existing audio-visual event localization (AVE) handles manually trimmed videos with only a single instance in each of them. However, this setting is unrealistic as natural videos often contain numerous audio-visual events with different categories. To better adapt to real-life applications, in this paper we focus on the task of dense-localizing audio-visual events, which aims to jointly localize and recognize all audio-visual events occurring in an untrimmed video. The problem is challenging as it requires fine-grained audio-visual scene and context understanding. To tackle this problem, we introduce the first Untrimmed Audio-Visual (UnAV-100) dataset, which contains 10K untrimmed videos with over 30K audio-visual events. Each video has 2.8 audio-visual events on average, and the events are usually related to each other and might co-occur as in real-life scenes. Next, we formulate the task using a new learning-based framework, which is capable of fully integrating audio and visual modalities to localize audio-visual events with various lengths and capture dependencies between them in a single pass. Extensive experiments demonstrate the effectiveness of our method as well as the significance of multi-scale cross-modal perception and dependency modeling for this task.
Audio-Visual MLP for Scoring Sport
Mar 22, 2022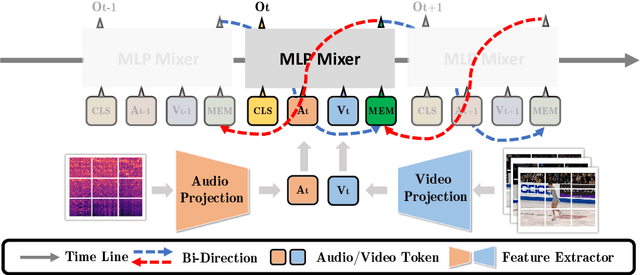
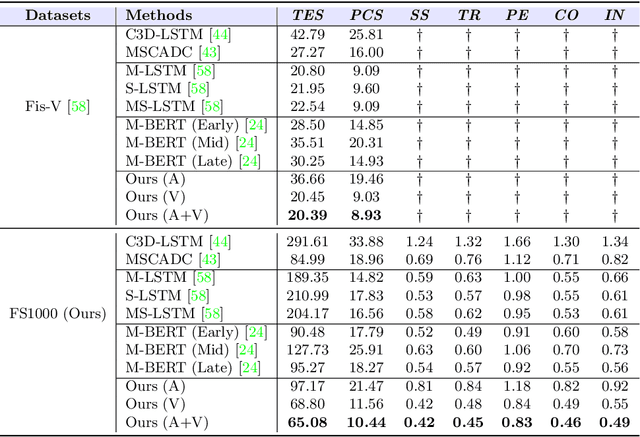
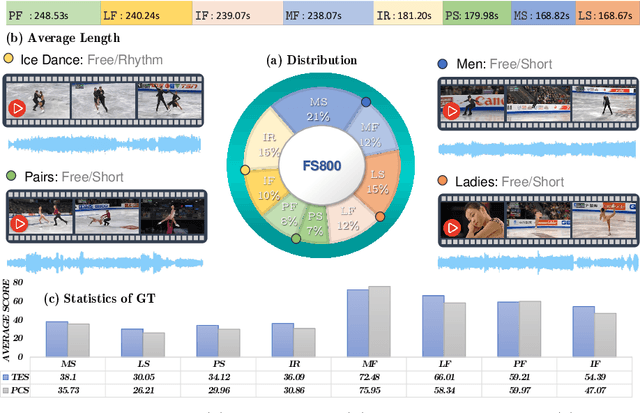
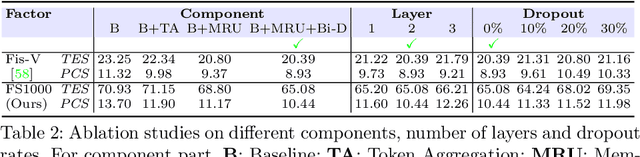
Figure skating scoring is a challenging task because it requires judging players' technical moves as well as coordination with the background music. Prior learning-based work cannot solve it well for two reasons: 1) each move in figure skating changes quickly, hence simply applying traditional frame sampling will lose a lot of valuable information, especially in a 3-5 minutes lasting video, so an extremely long-range representation learning is necessary; 2) prior methods rarely considered the critical audio-visual relationship in their models. Thus, we introduce a multimodal MLP architecture, named Skating-Mixer. It extends the MLP-Mixer-based framework into a multimodal fashion and effectively learns long-term representations through our designed memory recurrent unit (MRU). Aside from the model, we also collected a high-quality audio-visual FS1000 dataset, which contains over 1000 videos on 8 types of programs with 7 different rating metrics, overtaking other datasets in both quantity and diversity. Experiments show the proposed method outperforms SOTAs over all major metrics on the public Fis-V and our FS1000 dataset. In addition, we include an analysis applying our method to recent competitions that occurred in Beijing 2022 Winter Olympic Games, proving our method has strong robustness.