 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoar: Design and Deployment of A Smart Roadside Infrastructure System for Autonomous Driving
Apr 21, 2024
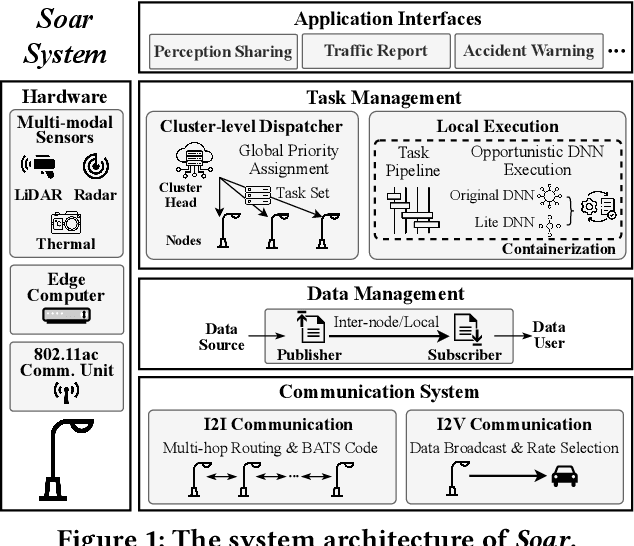
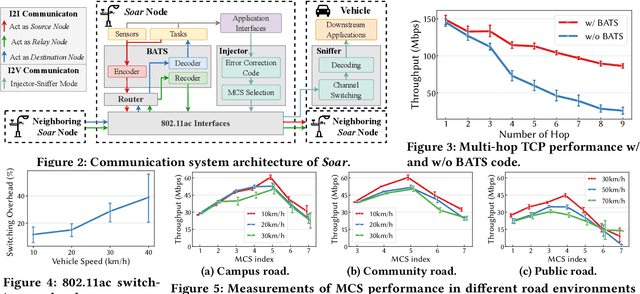
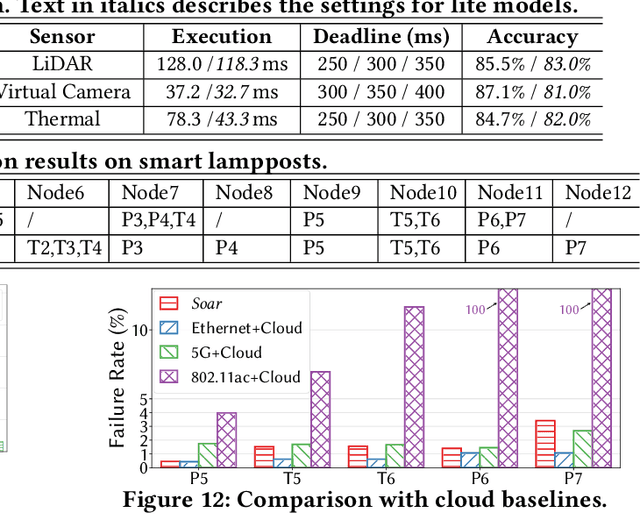
Recently,smart roadside infrastructure (SRI) has demonstrated the potential of achieving fully autonomous driving systems. To explore the potential of infrastructure-assisted autonomous driving, this paper presents the design and deployment of Soar, the first end-to-end SRI system specifically designed to support autonomous driving systems. Soar consists of both software and hardware components carefully designed to overcome various system and physical challenges. Soar can leverage the existing operational infrastructure like street lampposts for a lower barrier of adoption. Soar adopts a new communication architecture that comprises a bi-directional multi-hop I2I network and a downlink I2V broadcast service, which are designed based on off-the-shelf 802.11ac interfaces in an integrated manner. Soar also features a hierarchical DL task management framework to achieve desirable load balancing among nodes and enable them to collaborate efficiently to run multiple data-intensive autonomous driving applications. We deployed a total of 18 Soar nodes on existing lampposts on campus, which have been operational for over two years. Our real-world evaluation shows that Soar can support a diverse set of autonomous driving applications and achieve desirable real-time performance and high communication reliability. Our findings and experiences in this work offer key insights into the development and deployment of next-generation smart roadside infrastructure and autonomous driving systems.
CAVL: Learning Contrastive and Adaptive Representations of Vision and Language
Apr 10, 2023



Visual and linguistic pre-training aims to learn vision and language representations together, which can be transferred to visual-linguistic downstream tasks. However, there exists semantic confusion between language and vision during the pre-training stage. Moreover, current pre-trained models tend to take lots of computation resources for fine-tuning when transferred to downstream tasks. In this work, we present a simple but effective approach for learning Contrastive and Adaptive representations of Vision and Language, namely CAVL. Specifically, we introduce a pair-wise contrastive loss to learn alignments between the whole sentence and each image in the same batch during the pre-training process. At the fine-tuning stage, we introduce two lightweight adaptation networks to reduce model parameters and increase training speed for saving computation resources. We evaluate our CAVL on six main downstream tasks, including Visual Question Answering (VQA), Visual Commonsense Reasoning (VCR), Natural Language for Visual Reasoning (NLVR), Region-to-Phrase Grounding (RPG), Text-to-Image Retrieval (TIR), and Zero-shot Text-to-Image Retrieval (ZS-TIR). Compared to baselines, we achieve superior performance and reduce the fine-tuning time by a large margin (in particular, 76.17%). Extensive experiments and ablation studies demonstrate the efficiency of contrastive pre-training and adaptive fine-tuning proposed in our CAVL.
Audio-Visual MLP for Scoring Sport
Mar 22, 2022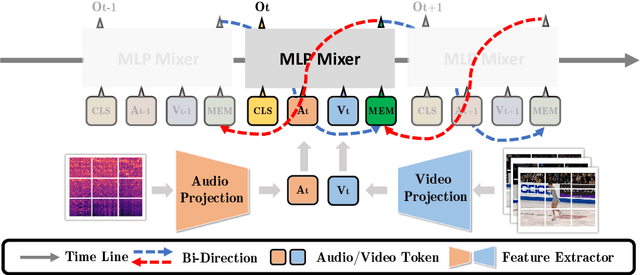
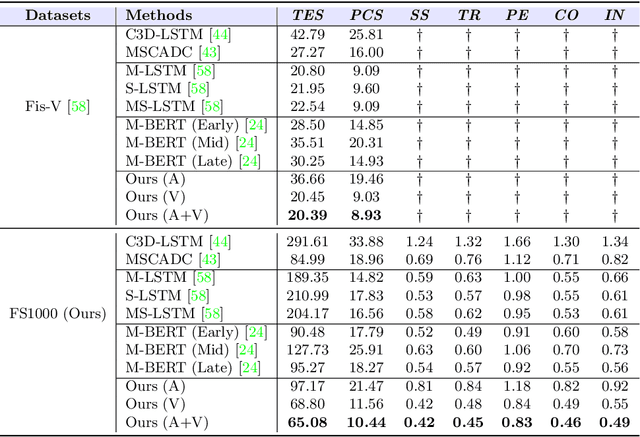
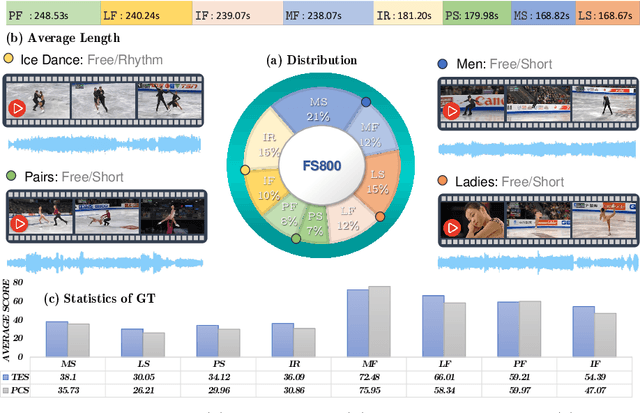
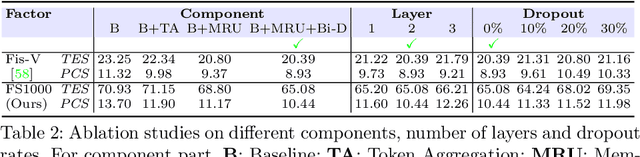
Figure skating scoring is a challenging task because it requires judging players' technical moves as well as coordination with the background music. Prior learning-based work cannot solve it well for two reasons: 1) each move in figure skating changes quickly, hence simply applying traditional frame sampling will lose a lot of valuable information, especially in a 3-5 minutes lasting video, so an extremely long-range representation learning is necessary; 2) prior methods rarely considered the critical audio-visual relationship in their models. Thus, we introduce a multimodal MLP architecture, named Skating-Mixer. It extends the MLP-Mixer-based framework into a multimodal fashion and effectively learns long-term representations through our designed memory recurrent unit (MRU). Aside from the model, we also collected a high-quality audio-visual FS1000 dataset, which contains over 1000 videos on 8 types of programs with 7 different rating metrics, overtaking other datasets in both quantity and diversity. Experiments show the proposed method outperforms SOTAs over all major metrics on the public Fis-V and our FS1000 dataset. In addition, we include an analysis applying our method to recent competitions that occurred in Beijing 2022 Winter Olympic Games, proving our method has strong robustness.
Point3D: tracking actions as moving points with 3D CNNs
Mar 20, 2022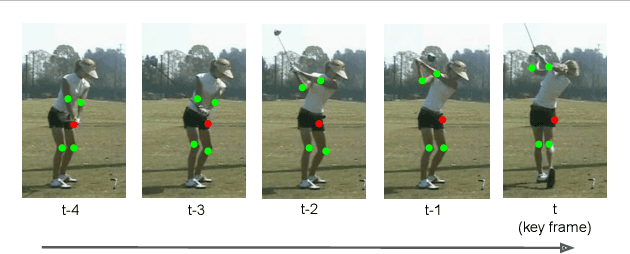
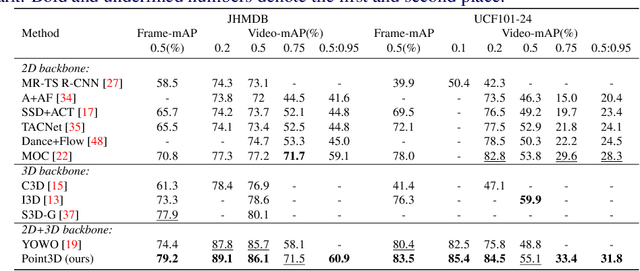
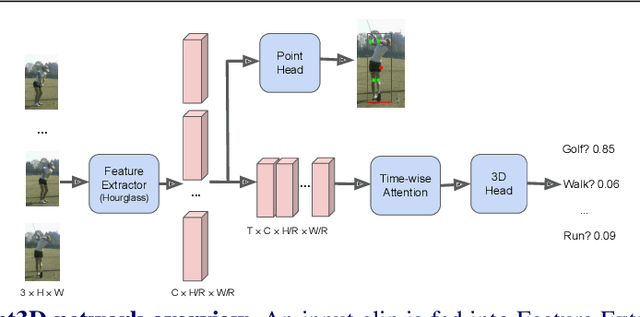

Spatio-temporal action recognition has been a challenging task that involves detecting where and when actions occur. Current state-of-the-art action detectors are mostly anchor-based, requiring sensitive anchor designs and huge computations due to calculating large numbers of anchor boxes. Motivated by nascent anchor-free approaches, we propose Point3D, a flexible and computationally efficient network with high precision for spatio-temporal action recognition. Our Point3D consists of a Point Head for action localization and a 3D Head for action classification. Firstly, Point Head is used to track center points and knot key points of humans to localize the bounding box of an action. These location features are then piped into a time-wise attention to learn long-range dependencies across frames. The 3D Head is later deployed for the final action classification. Our Point3D achieves state-of-the-art performance on the JHMDB, UCF101-24, and AVA benchmarks in terms of frame-mAP and video-mAP. Comprehensive ablation studies also demonstrate the effectiveness of each module proposed in our Point3D.
Towards Improving Spatiotemporal Action Recognition in Videos
Dec 15, 2020
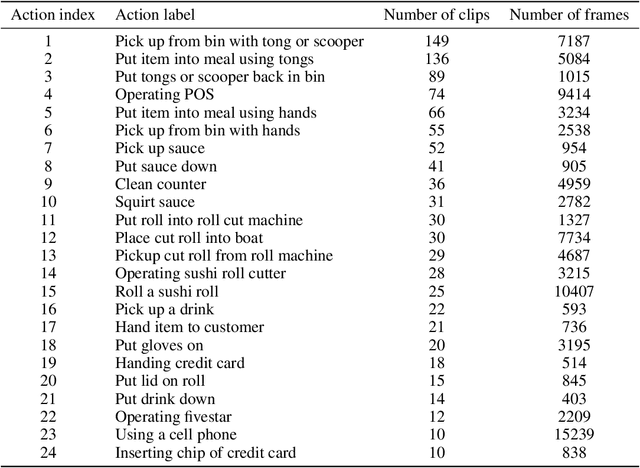
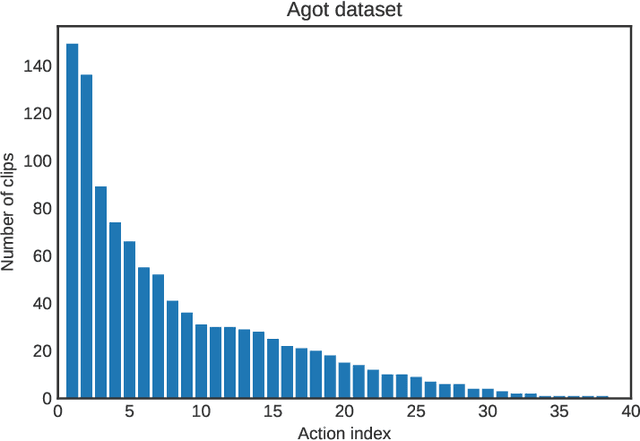
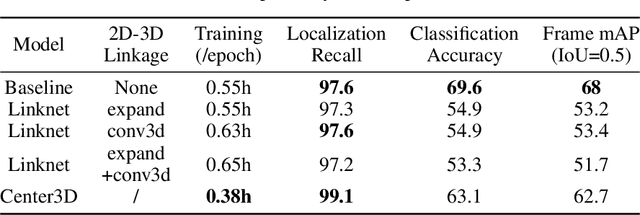
Spatiotemporal action recognition deals with locating and classifying actions in videos. Motivated by the latest state-of-the-art real-time object detector You Only Watch Once (YOWO), we aim to modify its structure to increase action detection precision and reduce computational time. Specifically, we propose four novel approaches in attempts to improve YOWO and address the imbalanced class issue in videos by modifying the loss function. We consider two moderate-sized datasets to apply our modification of YOWO - the popular Joint-annotated Human Motion Data Base (J-HMDB-21) and a private dataset of restaurant video footage provided by a Carnegie Mellon University-based startup, Agot.AI. The latter involves fast-moving actions with small objects as well as unbalanced data classes, making the task of action localization more challenging. We implement our proposed methods in the GitHub repository https://github.com/stoneMo/YOWOv2.