 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual MLP for Scoring Sport
Mar 22, 2022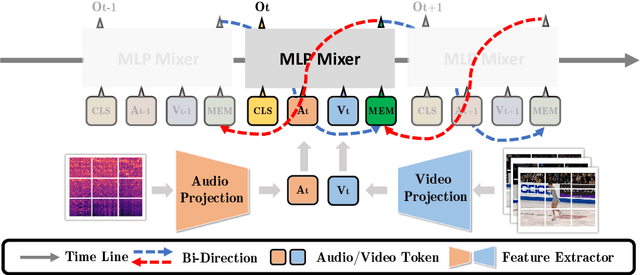
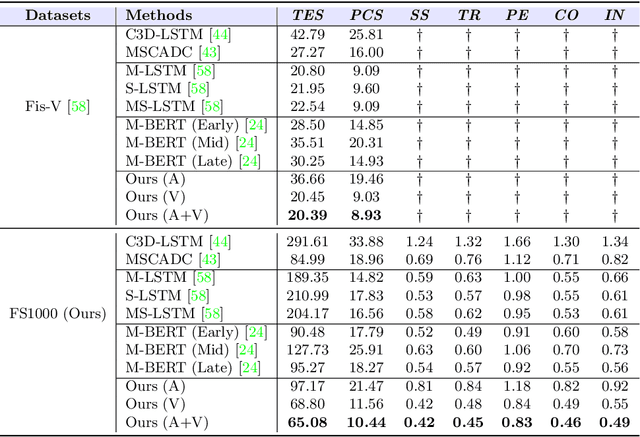
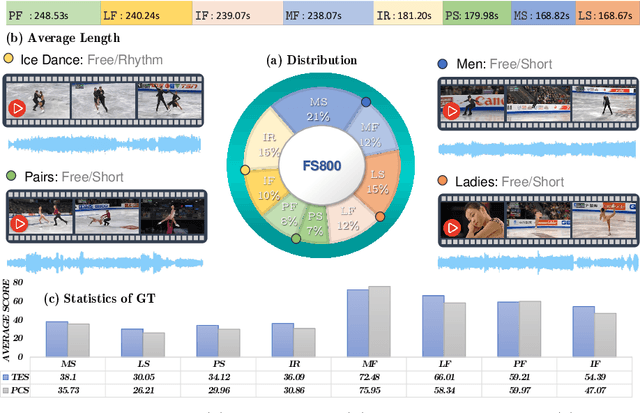
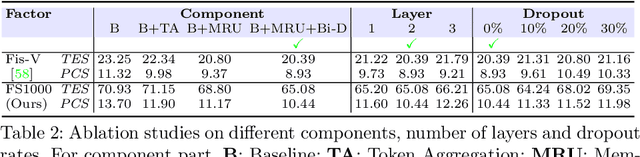
Figure skating scoring is a challenging task because it requires judging players' technical moves as well as coordination with the background music. Prior learning-based work cannot solve it well for two reasons: 1) each move in figure skating changes quickly, hence simply applying traditional frame sampling will lose a lot of valuable information, especially in a 3-5 minutes lasting video, so an extremely long-range representation learning is necessary; 2) prior methods rarely considered the critical audio-visual relationship in their models. Thus, we introduce a multimodal MLP architecture, named Skating-Mixer. It extends the MLP-Mixer-based framework into a multimodal fashion and effectively learns long-term representations through our designed memory recurrent unit (MRU). Aside from the model, we also collected a high-quality audio-visual FS1000 dataset, which contains over 1000 videos on 8 types of programs with 7 different rating metrics, overtaking other datasets in both quantity and diversity. Experiments show the proposed method outperforms SOTAs over all major metrics on the public Fis-V and our FS1000 dataset. In addition, we include an analysis applying our method to recent competitions that occurred in Beijing 2022 Winter Olympic Games, proving our method has strong robustness.