 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing in 3D: Free-Viewpoint Fusion Rendering with a 3D Infrared-Visible Scene Representation
Jan 19, 2026Infrared-visible image fusion aims to integrate infrared and visible information into a single fused image. Existing 2D fusion methods focus on fusing images from fixed camera viewpoints, neglecting a comprehensive understanding of complex scenarios, which results in the loss of critical information about the scene. To address this limitation, we propose a novel Infrared-Visible Gaussian Fusion (IVGF) framework, which reconstructs scene geometry from multimodal 2D inputs and enables direct rendering of fused images. Specifically, we propose a cross-modal adjustment (CMA) module that modulates the opacity of Gaussians to solve the problem of cross-modal conflicts. Moreover, to preserve the distinctive features from both modalities, we introduce a fusion loss that guides the optimization of CMA, thus ensuring that the fused image retains the critical characteristics of each modality. Comprehensive qualitative and quantitative experiments demonstrate the effectiveness of the proposed method.
Modality-Decoupled RGB-Thermal Object Detector via Query Fusion
Jan 13, 2026The advantage of RGB-Thermal (RGB-T) detection lies in its ability to perform modality fusion and integrate cross-modality complementary information, enabling robust detection under diverse illumination and weather conditions. However, under extreme conditions where one modality exhibits poor quality and disturbs detection, modality separation is necessary to mitigate the impact of noise. To address this problem, we propose a Modality-Decoupled RGB-T detection framework with Query Fusion (MDQF) to balance modality complementation and separation. In this framework, DETR-like detectors are employed as separate branches for the RGB and TIR images, with query fusion interspersed between the two branches in each refinement stage. Herein, query fusion is performed by feeding the high-quality queries from one branch to the other one after query selection and adaptation. This design effectively excludes the degraded modality and corrects the predictions using high-quality queries. Moreover, the decoupled framework allows us to optimize each individual branch with unpaired RGB or TIR images, eliminating the need for paired RGB-T data. Extensive experiments demonstrate that our approach delivers superior performance to existing RGB-T detectors and achieves better modality independence.
FusionFM: All-in-One Multi-Modal Image Fusion with Flow Matching
Nov 17, 2025Current multi-modal image fusion methods typically rely on task-specific models, leading to high training costs and limited scalability. While generative methods provide a unified modeling perspective, they often suffer from slow inference due to the complex sampling trajectories from noise to image. To address this, we formulate image fusion as a direct probabilistic transport from source modalities to the fused image distribution, leveraging the flow matching paradigm to improve sampling efficiency and structural consistency. To mitigate the lack of high-quality fused images for supervision, we collect fusion results from multiple state-of-the-art models as priors, and employ a task-aware selection function to select the most reliable pseudo-labels for each task. We further introduce a Fusion Refiner module that employs a divide-and-conquer strategy to systematically identify, decompose, and enhance degraded components in selected pseudo-labels. For multi-task scenarios, we integrate elastic weight consolidation and experience replay mechanisms to preserve cross-task performance and enhance continual learning ability from both parameter stability and memory retention perspectives. Our approach achieves competitive performance across diverse fusion tasks, while significantly improving sampling efficiency and maintaining a lightweight model design. The code will be available at: https://github.com/Ist-Zhy/FusionFM.
Learning A Robust RGB-Thermal Detector for Extreme Modality Imbalance
May 28, 2025RGB-Thermal (RGB-T) object detection utilizes thermal infrared (TIR) images to complement RGB data, improving robustness in challenging conditions. Traditional RGB-T detectors assume balanced training data, where both modalities contribute equally. However, in real-world scenarios, modality degradation-due to environmental factors or technical issues-can lead to extreme modality imbalance, causing out-of-distribution (OOD) issues during testing and disrupting model convergence during training. This paper addresses these challenges by proposing a novel base-and-auxiliary detector architecture. We introduce a modality interaction module to adaptively weigh modalities based on their quality and handle imbalanced samples effectively. Additionally, we leverage modality pseudo-degradation to simulate real-world imbalances in training data. The base detector, trained on high-quality pairs, provides a consistency constraint for the auxiliary detector, which receives degraded samples. This framework enhances model robustness, ensuring reliable performance even under severe modality degradation. Experimental results demonstrate the effectiveness of our method in handling extreme modality imbalances~(decreasing the Missing Rate by 55%) and improving performance across various baseline detectors.
Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning
Feb 12, 2025



Chain-of-Thought (CoT) prompting has emerged as a powerful technique for enhancing language model's reasoning capabilities. However, generating long and correct CoT trajectories is challenging. Recent studies have demonstrated that Looped Transformers possess remarkable length generalization capabilities, but their limited generality and adaptability prevent them from serving as an alternative to auto-regressive solutions. To better leverage the strengths of Looped Transformers, we propose RELAY (REasoning through Loop Alignment iterativelY). Specifically, we align the steps of Chain-of-Thought (CoT) reasoning with loop iterations and apply intermediate supervision during the training of Looped Transformers. This additional iteration-wise supervision not only preserves the Looped Transformer's ability for length generalization but also enables it to predict CoT reasoning steps for unseen data. Therefore, we leverage this Looped Transformer to generate accurate reasoning chains for complex problems that exceed the training length, which will then be used to fine-tune an auto-regressive model. We conduct extensive experiments, and the results demonstrate the effectiveness of our approach, with significant improvements in the performance of the auto-regressive model. Code will be released at https://github.com/qifanyu/RELAY.
ZeroBP: Learning Position-Aware Correspondence for Zero-shot 6D Pose Estimation in Bin-Picking
Feb 03, 2025Bin-picking is a practical and challenging robotic manipulation task, where accurate 6D pose estimation plays a pivotal role. The workpieces in bin-picking are typically textureless and randomly stacked in a bin, which poses a significant challenge to 6D pose estimation. Existing solutions are typically learning-based methods, which require object-specific training. Their efficiency of practical deployment for novel workpieces is highly limited by data collection and model retraining. Zero-shot 6D pose estimation is a potential approach to address the issue of deployment efficiency. Nevertheless, existing zero-shot 6D pose estimation methods are designed to leverage feature matching to establish point-to-point correspondences for pose estimation, which is less effective for workpieces with textureless appearances and ambiguous local regions. In this paper, we propose ZeroBP, a zero-shot pose estimation framework designed specifically for the bin-picking task. ZeroBP learns Position-Aware Correspondence (PAC) between the scene instance and its CAD model, leveraging both local features and global positions to resolve the mismatch issue caused by ambiguous regions with similar shapes and appearances. Extensive experiments on the ROBI dataset demonstrate that ZeroBP outperforms state-of-the-art zero-shot pose estimation methods, achieving an improvement of 9.1% in average recall of correct poses.
PRSI: Privacy-Preserving Recommendation Model Based on Vector Splitting and Interactive Protocols
Nov 27, 2024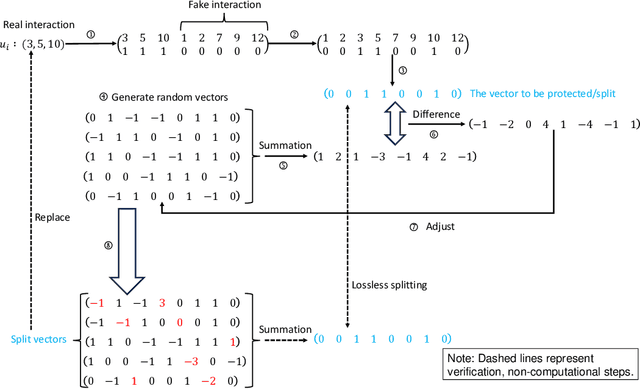

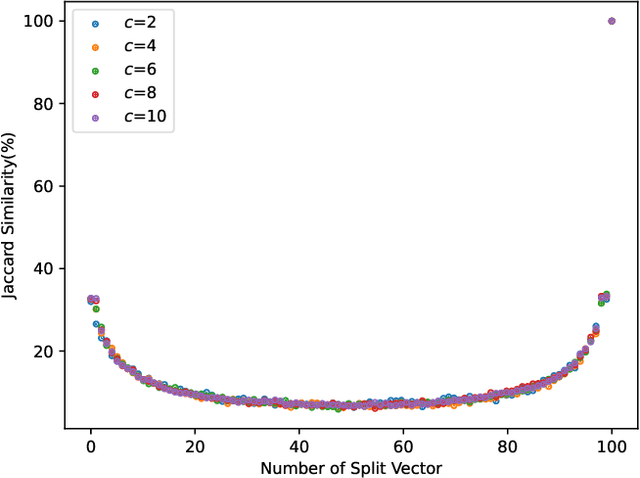
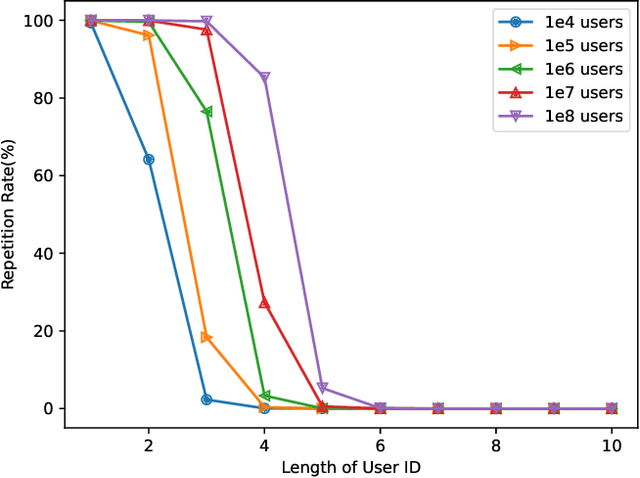
With the development of the internet, recommending interesting products to users has become a highly valuable research topic for businesses. Recommendation systems play a crucial role in addressing this issue. To prevent the leakage of each user's (client's) private data, Federated Recommendation Systems (FedRec) have been proposed and widely used. However, extensive research has shown that FedRec suffers from security issues such as data privacy leakage, and it is challenging to train effective models with FedRec when each client only holds interaction information for a single user. To address these two problems, this paper proposes a new privacy-preserving recommendation system (PRSI), which includes a preprocessing module and two main phases. The preprocessing module employs split vectors and fake interaction items to protect clients' interaction information and recommendation results. The two main phases are: (1) the collection of interaction information and (2) the sending of recommendation results. In the interaction information collection phase, each client uses the preprocessing module and random communication methods (according to the designed interactive protocol) to protect their ID information and IP addresses. In the recommendation results sending phase, the central server uses the preprocessing module and triplets to distribute recommendation results to each client under secure conditions, following the designed interactive protocol. Finally, we conducted multiple sets of experiments to verify the security, accuracy, and communication cost of the proposed method.
MambaVLT: Time-Evolving Multimodal State Space Model for Vision-Language Tracking
Nov 23, 2024



The vision-language tracking task aims to perform object tracking based on various modality references. Existing Transformer-based vision-language tracking methods have made remarkable progress by leveraging the global modeling ability of self-attention. However, current approaches still face challenges in effectively exploiting the temporal information and dynamically updating reference features during tracking. Recently, the State Space Model (SSM), known as Mamba, has shown astonishing ability in efficient long-sequence modeling. Particularly, its state space evolving process demonstrates promising capabilities in memorizing multimodal temporal information with linear complexity. Witnessing its success, we propose a Mamba-based vision-language tracking model to exploit its state space evolving ability in temporal space for robust multimodal tracking, dubbed MambaVLT. In particular, our approach mainly integrates a time-evolving hybrid state space block and a selective locality enhancement block, to capture contextual information for multimodal modeling and adaptive reference feature update. Besides, we introduce a modality-selection module that dynamically adjusts the weighting between visual and language references, mitigating potential ambiguities from either reference type. Extensive experimental results show that our method performs favorably against state-of-the-art trackers across diverse benchmarks.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
Discriminative Spatial-Semantic VOS Solution: 1st Place Solution for 6th LSVOS
Aug 29, 2024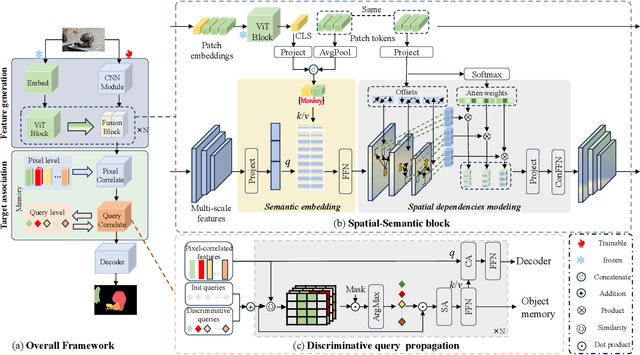
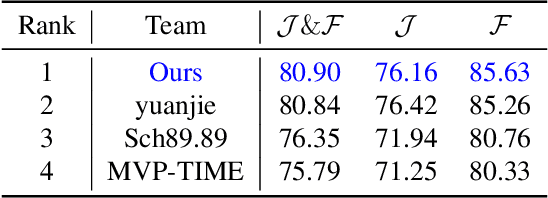

Video object segmentation (VOS) is a crucial task in computer vision, but current VOS methods struggle with complex scenes and prolonged object motions. To address these challenges, the MOSE dataset aims to enhance object recognition and differentiation in complex environments, while the LVOS dataset focuses on segmenting objects exhibiting long-term, intricate movements. This report introduces a discriminative spatial-temporal VOS model that utilizes discriminative object features as query representations. The semantic understanding of spatial-semantic modules enables it to recognize object parts, while salient features highlight more distinctive object characteristics. Our model, trained on extensive VOS datasets, achieved first place (\textbf{80.90\%} $\mathcal{J \& F}$) on the test set of the 6th LSVOS challenge in the VOS Track, demonstrating its effectiveness in tackling the aforementioned challenges. The code will be available at \href{https://github.com/yahooo-m/VOS-Solution}{code}.