 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR$^3$D: Regional-guided Residual Radar Diffusion
Jan 10, 2026Millimeter-wave radar enables robust environment perception in autonomous systems under adverse conditions yet suffers from sparse, noisy point clouds with low angular resolution. Existing diffusion-based radar enhancement methods either incur high learning complexity by modeling full LiDAR distributions or fail to prioritize critical structures due to uniform regional processing. To address these issues, we propose R3D, a regional-guided residual radar diffusion framework that integrates residual diffusion modeling-focusing on the concentrated LiDAR-radar residual encoding complementary high-frequency details to reduce learning difficulty-and sigma-adaptive regional guidance-leveraging radar-specific signal properties to generate attention maps and applying lightweight guidance only in low-noise stages to avoid gradient imbalance while refining key regions. Extensive experiments on the ColoRadar dataset demonstrate that R3D outperforms state-of-the-art methods, providing a practical solution for radar perception enhancement. Our anonymous code and pretrained models are released here: https://anonymous.4open.science/r/r3d-F836
MambaVLT: Time-Evolving Multimodal State Space Model for Vision-Language Tracking
Nov 23, 2024



The vision-language tracking task aims to perform object tracking based on various modality references. Existing Transformer-based vision-language tracking methods have made remarkable progress by leveraging the global modeling ability of self-attention. However, current approaches still face challenges in effectively exploiting the temporal information and dynamically updating reference features during tracking. Recently, the State Space Model (SSM), known as Mamba, has shown astonishing ability in efficient long-sequence modeling. Particularly, its state space evolving process demonstrates promising capabilities in memorizing multimodal temporal information with linear complexity. Witnessing its success, we propose a Mamba-based vision-language tracking model to exploit its state space evolving ability in temporal space for robust multimodal tracking, dubbed MambaVLT. In particular, our approach mainly integrates a time-evolving hybrid state space block and a selective locality enhancement block, to capture contextual information for multimodal modeling and adaptive reference feature update. Besides, we introduce a modality-selection module that dynamically adjusts the weighting between visual and language references, mitigating potential ambiguities from either reference type. Extensive experimental results show that our method performs favorably against state-of-the-art trackers across diverse benchmarks.
GraphFM: A Comprehensive Benchmark for Graph Foundation Model
Jun 12, 2024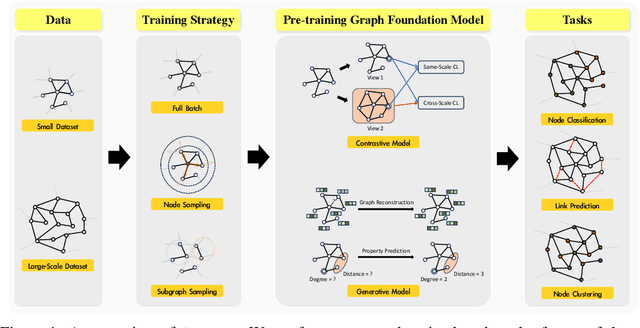
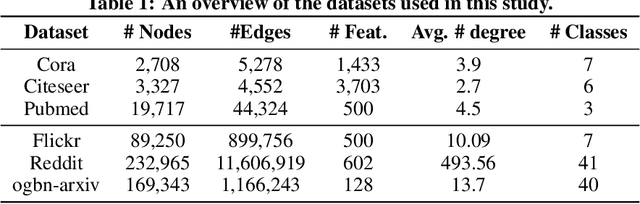
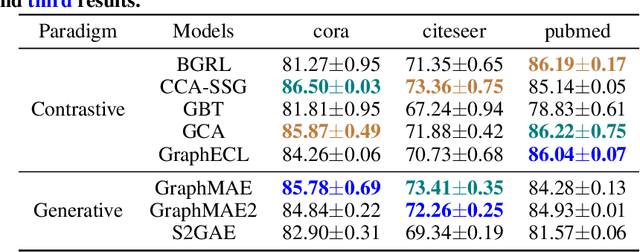
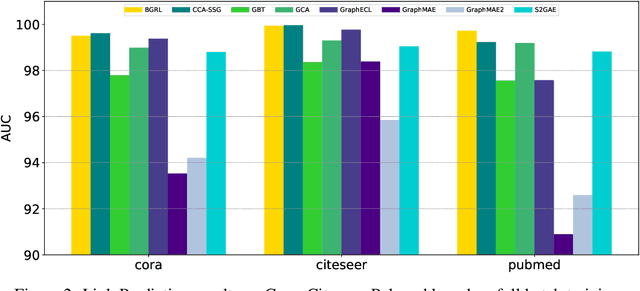
Foundation Models (FMs) serve as a general class for the development of artificial intelligence systems, offering broad potential for generalization across a spectrum of downstream tasks. Despite extensive research into self-supervised learning as the cornerstone of FMs, several outstanding issues persist in Graph Foundation Models that rely on graph self-supervised learning, namely: 1) Homogenization. The extent of generalization capability on downstream tasks remains unclear. 2) Scalability. It is unknown how effectively these models can scale to large datasets. 3) Efficiency. The training time and memory usage of these models require evaluation. 4) Training Stop Criteria. Determining the optimal stopping strategy for pre-training across multiple tasks to maximize performance on downstream tasks. To address these questions, we have constructed a rigorous benchmark that thoroughly analyzes and studies the generalization and scalability of self-supervised Graph Neural Network (GNN) models. Regarding generalization, we have implemented and compared the performance of various self-supervised GNN models, trained to generate node representations, across tasks such as node classification, link prediction, and node clustering. For scalability, we have compared the performance of various models after training using full-batch and mini-batch strategies. Additionally, we have assessed the training efficiency of these models by conducting experiments to test their GPU memory usage and throughput. Through these experiments, we aim to provide insights to motivate future research. The code for this benchmark is publicly available at https://github.com/NYUSHCS/GraphFM.
TexRO: Generating Delicate Textures of 3D Models by Recursive Optimization
Mar 22, 2024This paper presents TexRO, a novel method for generating delicate textures of a known 3D mesh by optimizing its UV texture. The key contributions are two-fold. We propose an optimal viewpoint selection strategy, that finds the most miniature set of viewpoints covering all the faces of a mesh. Our viewpoint selection strategy guarantees the completeness of a generated result. We propose a recursive optimization pipeline that optimizes a UV texture at increasing resolutions, with an adaptive denoising method that re-uses existing textures for new texture generation. Through extensive experimentation, we demonstrate the superior performance of TexRO in terms of texture quality, detail preservation, visual consistency, and, notably runtime speed, outperforming other current methods. The broad applicability of TexRO is further confirmed through its successful use on diverse 3D models.
GEA: Reconstructing Expressive 3D Gaussian Avatar from Monocular Video
Feb 26, 2024



This paper presents GEA, a novel method for creating expressive 3D avatars with high-fidelity reconstructions of body and hands based on 3D Gaussians. The key contributions are twofold. First, we design a two-stage pose estimation method to obtain an accurate SMPL-X pose from input images, providing a correct mapping between the pixels of a training image and the SMPL-X model. It uses an attention-aware network and an optimization scheme to align the normal and silhouette between the estimated SMPL-X body and the real body in the image. Second, we propose an iterative re-initialization strategy to handle unbalanced aggregation and initialization bias faced by Gaussian representation. This strategy iteratively redistributes the avatar's Gaussian points, making it evenly distributed near the human body surface by applying meshing, resampling and re-Gaussian operations. As a result, higher-quality rendering can be achieved. Extensive experimental analyses validate the effectiveness of the proposed model, demonstrating that it achieves state-of-the-art performance in photorealistic novel view synthesis while offering fine-grained control over the human body and hand pose. Project page: https://3d-aigc.github.io/GEA/.