 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQVLA: Not All Channels Are Equal in Vision-Language-Action Model's Quantization
Feb 03, 2026The advent of Vision-Language-Action (VLA) models represents a significant leap for embodied intelligence, yet their immense computational demands critically hinder deployment on resource-constrained robotic platforms. Intuitively, low-bit quantization is a prevalent and preferred technique for large-scale model compression. However, we find that a systematic analysis of VLA model's quantization is fundamentally lacking. We argue that naively applying uniform-bit quantization from Large Language Models (LLMs) to robotics is flawed, as these methods prioritize passive data fidelity while ignoring how minor action deviations compound into catastrophic task failures. To bridge this gap, we introduce QVLA, the first action-centric quantization framework specifically designed for embodied control. In a sharp departure from the rigid, uniform-bit quantization of LLM-based methods, QVLA introduces a highly granular, channel-wise bit allocation strategy. Its core mechanism is to directly measure the final action-space sensitivity when quantizing each individual channel to various bit-widths. This process yields a precise, per-channel importance metric that guides a global optimization, which elegantly unifies quantization and pruning (0-bit) into a single, cohesive framework. Extensive evaluations on different baselines demonstrate the superiority of our approach. In the LIBERO, the quantization version of OpenVLA-OFT with our method requires only 29.2% of the original model's VRAM while maintaining 98.9% of its original performance and achieving a 1.49x speedup. This translates to a 22.6% performance improvement over the LLM-derived method SmoothQuant. Our work establishes a new, principled foundation for compressing VLA models in robotics, paving the way for deploying powerful, large-scale models on real-world hardware. Code will be released.
Simulator and Experience Enhanced Diffusion Model for Comprehensive ECG Generation
Nov 13, 2025Cardiovascular disease (CVD) is a leading cause of mortality worldwide. Electrocardiograms (ECGs) are the most widely used non-invasive tool for cardiac assessment, yet large, well-annotated ECG corpora are scarce due to cost, privacy, and workflow constraints. Generating ECGs can be beneficial for the mechanistic understanding of cardiac electrical activity, enable the construction of large, heterogeneous, and unbiased datasets, and facilitate privacy-preserving data sharing. Generating realistic ECG signals from clinical context is important yet underexplored. Recent work has leveraged diffusion models for text-to-ECG generation, but two challenges remain: (i) existing methods often overlook the physiological simulator knowledge of cardiac activity; and (ii) they ignore broader, experience-based clinical knowledge grounded in real-world practice. To address these gaps, we propose SE-Diff, a novel physiological simulator and experience enhanced diffusion model for comprehensive ECG generation. SE-Diff integrates a lightweight ordinary differential equation (ODE)-based ECG simulator into the diffusion process via a beat decoder and simulator-consistent constraints, injecting mechanistic priors that promote physiologically plausible waveforms. In parallel, we design an LLM-powered experience retrieval-augmented strategy to inject clinical knowledge, providing more guidance for ECG generation. Extensive experiments on real-world ECG datasets demonstrate that SE-Diff improves both signal fidelity and text-ECG semantic alignment over baselines, proving its superiority for text-to-ECG generation. We further show that the simulator-based and experience-based knowledge also benefit downstream ECG classification.
Generalist vs Specialist Time Series Foundation Models: Investigating Potential Emergent Behaviors in Assessing Human Health Using PPG Signals
Oct 16, 2025
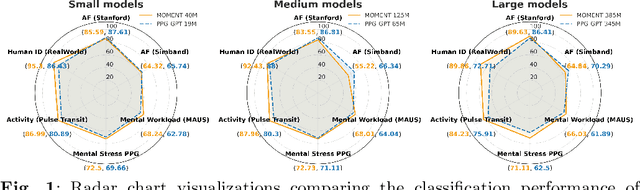
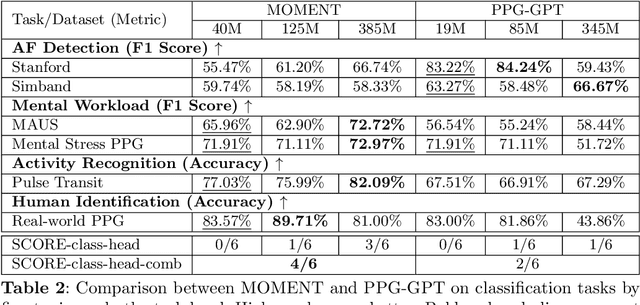
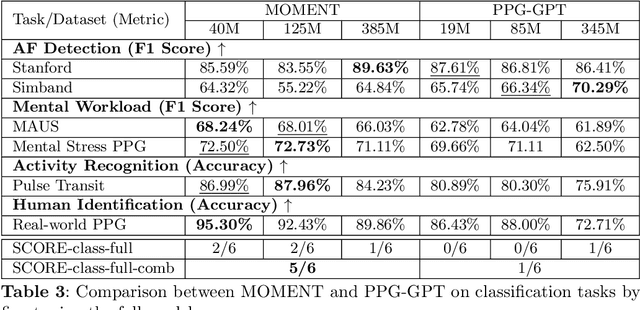
Foundation models are large-scale machine learning models that are pre-trained on massive amounts of data and can be adapted for various downstream tasks. They have been extensively applied to tasks in Natural Language Processing and Computer Vision with models such as GPT, BERT, and CLIP. They are now also increasingly gaining attention in time-series analysis, particularly for physiological sensing. However, most time series foundation models are specialist models - with data in pre-training and testing of the same type, such as Electrocardiogram, Electroencephalogram, and Photoplethysmogram (PPG). Recent works, such as MOMENT, train a generalist time series foundation model with data from multiple domains, such as weather, traffic, and electricity. This paper aims to conduct a comprehensive benchmarking study to compare the performance of generalist and specialist models, with a focus on PPG signals. Through an extensive suite of total 51 tasks covering cardiac state assessment, laboratory value estimation, and cross-modal inference, we comprehensively evaluate both models across seven dimensions, including win score, average performance, feature quality, tuning gain, performance variance, transferability, and scalability. These metrics jointly capture not only the models' capability but also their adaptability, robustness, and efficiency under different fine-tuning strategies, providing a holistic understanding of their strengths and limitations for diverse downstream scenarios. In a full-tuning scenario, we demonstrate that the specialist model achieves a 27% higher win score. Finally, we provide further analysis on generalization, fairness, attention visualizations, and the importance of training data choice.
GraphFM: A Comprehensive Benchmark for Graph Foundation Model
Jun 12, 2024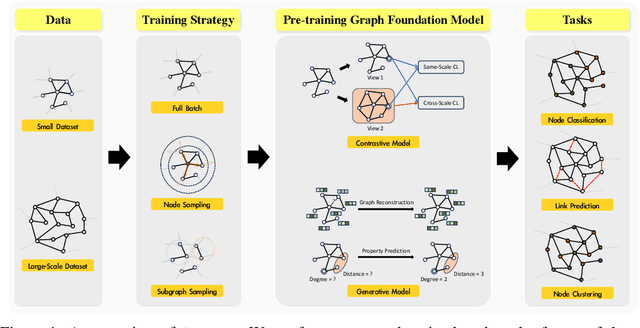
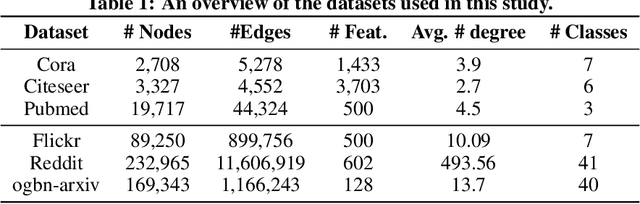
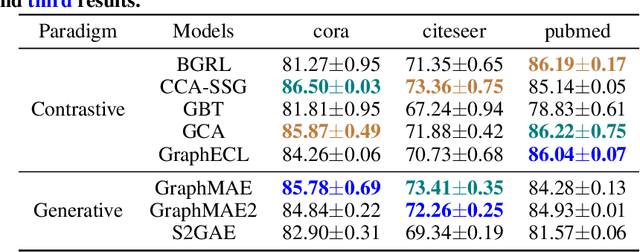
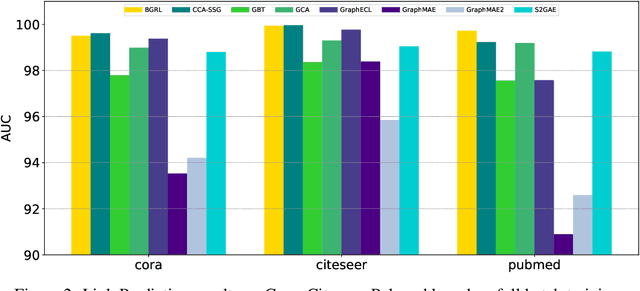
Foundation Models (FMs) serve as a general class for the development of artificial intelligence systems, offering broad potential for generalization across a spectrum of downstream tasks. Despite extensive research into self-supervised learning as the cornerstone of FMs, several outstanding issues persist in Graph Foundation Models that rely on graph self-supervised learning, namely: 1) Homogenization. The extent of generalization capability on downstream tasks remains unclear. 2) Scalability. It is unknown how effectively these models can scale to large datasets. 3) Efficiency. The training time and memory usage of these models require evaluation. 4) Training Stop Criteria. Determining the optimal stopping strategy for pre-training across multiple tasks to maximize performance on downstream tasks. To address these questions, we have constructed a rigorous benchmark that thoroughly analyzes and studies the generalization and scalability of self-supervised Graph Neural Network (GNN) models. Regarding generalization, we have implemented and compared the performance of various self-supervised GNN models, trained to generate node representations, across tasks such as node classification, link prediction, and node clustering. For scalability, we have compared the performance of various models after training using full-batch and mini-batch strategies. Additionally, we have assessed the training efficiency of these models by conducting experiments to test their GPU memory usage and throughput. Through these experiments, we aim to provide insights to motivate future research. The code for this benchmark is publicly available at https://github.com/NYUSHCS/GraphFM.
Magic Clothing: Controllable Garment-Driven Image Synthesis
Apr 15, 2024



We propose Magic Clothing, a latent diffusion model (LDM)-based network architecture for an unexplored garment-driven image synthesis task. Aiming at generating customized characters wearing the target garments with diverse text prompts, the image controllability is the most critical issue, i.e., to preserve the garment details and maintain faithfulness to the text prompts. To this end, we introduce a garment extractor to capture the detailed garment features, and employ self-attention fusion to incorporate them into the pretrained LDMs, ensuring that the garment details remain unchanged on the target character. Then, we leverage the joint classifier-free guidance to balance the control of garment features and text prompts over the generated results. Meanwhile, the proposed garment extractor is a plug-in module applicable to various finetuned LDMs, and it can be combined with other extensions like ControlNet and IP-Adapter to enhance the diversity and controllability of the generated characters. Furthermore, we design Matched-Points-LPIPS (MP-LPIPS), a robust metric for evaluating the consistency of the target image to the source garment. Extensive experiments demonstrate that our Magic Clothing achieves state-of-the-art results under various conditional controls for garment-driven image synthesis. Our source code is available at https://github.com/ShineChen1024/MagicClothing.
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on
Mar 07, 2024



We present OOTDiffusion, a novel network architecture for realistic and controllable image-based virtual try-on (VTON). We leverage the power of pretrained latent diffusion models, designing an outfitting UNet to learn the garment detail features. Without a redundant warping process, the garment features are precisely aligned with the target human body via the proposed outfitting fusion in the self-attention layers of the denoising UNet. In order to further enhance the controllability, we introduce outfitting dropout to the training process, which enables us to adjust the strength of the garment features through classifier-free guidance. Our comprehensive experiments on the VITON-HD and Dress Code datasets demonstrate that OOTDiffusion efficiently generates high-quality try-on results for arbitrary human and garment images, which outperforms other VTON methods in both realism and controllability, indicating an impressive breakthrough in virtual try-on. Our source code is available at https://github.com/levihsu/OOTDiffusion.
A unified neural network for object detection, multiple object tracking and vehicle re-identification
Jul 08, 2019

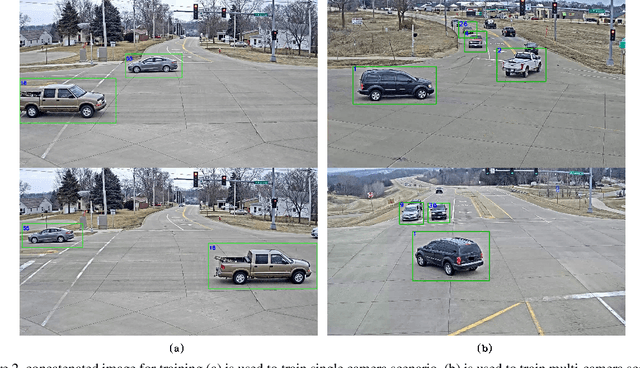

Deep SORT\cite{wojke2017simple} is a tracking-by-detetion approach to multiple object tracking with a detector and a RE-ID model. Both separately training and inference with the two model is time-comsuming. In this paper, we unify the detector and RE-ID model into an end-to-end network, by adding an additional track branch for tracking in Faster RCNN architecture. With a unified network, we are able to train the whole model end-to-end with multi loss, which has shown much benefit in other recent works. The RE-ID model in Deep SORT needs to use deep CNNs to extract feature map from detected object images, However, track branch in our proposed network straight make use of the RoI feature vector in Faster RCNN baseline, which reduced the amount of calculation. Since the single image lacks the same object which is necessary when we use the triplet loss to optimizer the track branch, we concatenate the neighbouring frames in a video to construct our training dataset. We have trained and evaluated our model on AIC19 vehicle tracking dataset, experiment shows that our model with resnet101 backbone can achieve 57.79 \% mAP and track vehicle well.