 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Large Language Models with Continual Learning for Aspect-based Sentiment Analysis
May 09, 2024Aspect-based sentiment analysis (ABSA) is an important subtask of sentiment analysis, which aims to extract the aspects and predict their sentiments. Most existing studies focus on improving the performance of the target domain by fine-tuning domain-specific models (trained on source domains) based on the target domain dataset. Few works propose continual learning tasks for ABSA, which aim to learn the target domain's ability while maintaining the history domains' abilities. In this paper, we propose a Large Language Model-based Continual Learning (\texttt{LLM-CL}) model for ABSA. First, we design a domain knowledge decoupling module to learn a domain-invariant adapter and separate domain-variant adapters dependently with an orthogonal constraint. Then, we introduce a domain knowledge warmup strategy to align the representation between domain-invariant and domain-variant knowledge. In the test phase, we index the corresponding domain-variant knowledge via domain positioning to not require each sample's domain ID. Extensive experiments over 19 datasets indicate that our \texttt{LLM-CL} model obtains new state-of-the-art performance.
Magic Clothing: Controllable Garment-Driven Image Synthesis
Apr 15, 2024



We propose Magic Clothing, a latent diffusion model (LDM)-based network architecture for an unexplored garment-driven image synthesis task. Aiming at generating customized characters wearing the target garments with diverse text prompts, the image controllability is the most critical issue, i.e., to preserve the garment details and maintain faithfulness to the text prompts. To this end, we introduce a garment extractor to capture the detailed garment features, and employ self-attention fusion to incorporate them into the pretrained LDMs, ensuring that the garment details remain unchanged on the target character. Then, we leverage the joint classifier-free guidance to balance the control of garment features and text prompts over the generated results. Meanwhile, the proposed garment extractor is a plug-in module applicable to various finetuned LDMs, and it can be combined with other extensions like ControlNet and IP-Adapter to enhance the diversity and controllability of the generated characters. Furthermore, we design Matched-Points-LPIPS (MP-LPIPS), a robust metric for evaluating the consistency of the target image to the source garment. Extensive experiments demonstrate that our Magic Clothing achieves state-of-the-art results under various conditional controls for garment-driven image synthesis. Our source code is available at https://github.com/ShineChen1024/MagicClothing.
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on
Mar 07, 2024



We present OOTDiffusion, a novel network architecture for realistic and controllable image-based virtual try-on (VTON). We leverage the power of pretrained latent diffusion models, designing an outfitting UNet to learn the garment detail features. Without a redundant warping process, the garment features are precisely aligned with the target human body via the proposed outfitting fusion in the self-attention layers of the denoising UNet. In order to further enhance the controllability, we introduce outfitting dropout to the training process, which enables us to adjust the strength of the garment features through classifier-free guidance. Our comprehensive experiments on the VITON-HD and Dress Code datasets demonstrate that OOTDiffusion efficiently generates high-quality try-on results for arbitrary human and garment images, which outperforms other VTON methods in both realism and controllability, indicating an impressive breakthrough in virtual try-on. Our source code is available at https://github.com/levihsu/OOTDiffusion.
State Value Generation with Prompt Learning and Self-Training for Low-Resource Dialogue State Tracking
Jan 30, 2024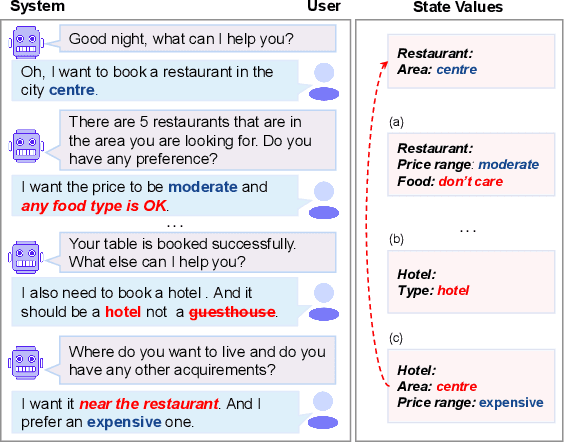
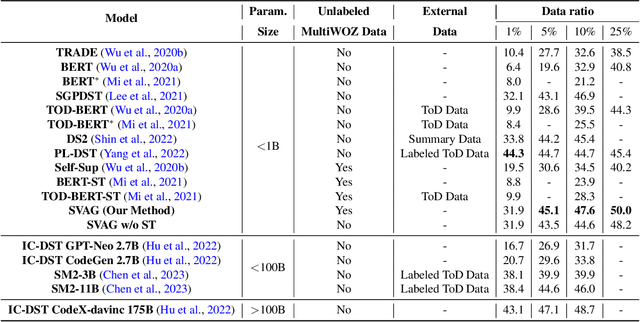
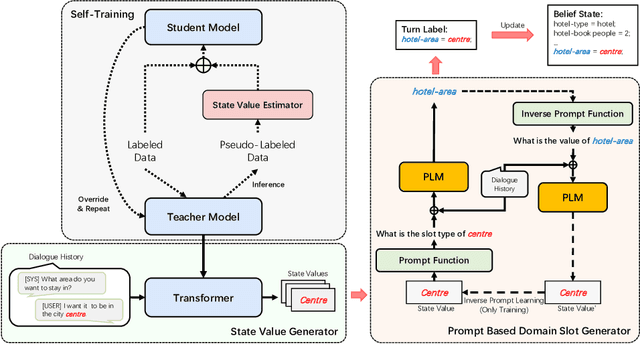

Recently, low-resource dialogue state tracking (DST) has received increasing attention. First obtaining state values then based on values to generate slot types has made great progress in this task. However, obtaining state values is still an under-studied problem. Existing extraction-based approaches cannot capture values that require the understanding of context and are not generalizable either. To address these issues, we propose a novel State VAlue Generation based framework (SVAG), decomposing DST into state value generation and domain slot generation. Specifically, we propose to generate state values and use self-training to further improve state value generation. Moreover, we design an estimator aiming at detecting incomplete generation and incorrect generation for pseudo-labeled data selection during self-training. Experimental results on the MultiWOZ 2.1 dataset show that our method which has only less than 1 billion parameters achieves state-of-the-art performance under the data ratio settings of 5%, 10%, and 25% when limited to models under 100 billion parameters. Compared to models with more than 100 billion parameters, SVAG still reaches competitive results.
Using Language Models For Knowledge Acquisition in Natural Language Reasoning Problems
Apr 04, 2023For a natural language problem that requires some non-trivial reasoning to solve, there are at least two ways to do it using a large language model (LLM). One is to ask it to solve it directly. The other is to use it to extract the facts from the problem text and then use a theorem prover to solve it. In this note, we compare the two methods using ChatGPT and GPT4 on a series of logic word puzzles, and conclude that the latter is the right approach.
MOSS: End-to-End Dialog System Framework with Modular Supervision
Sep 12, 2019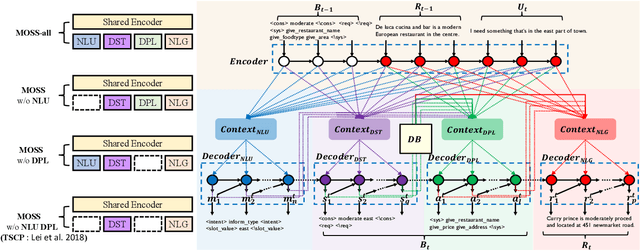
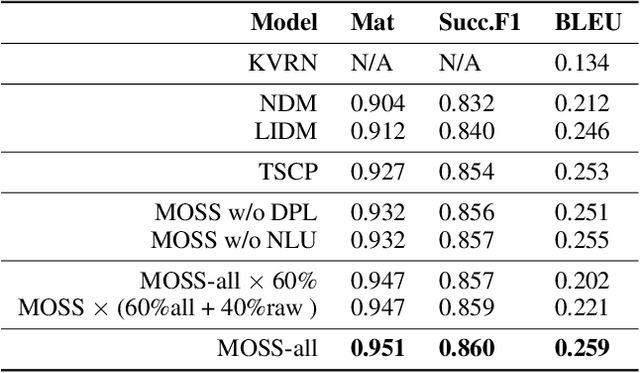
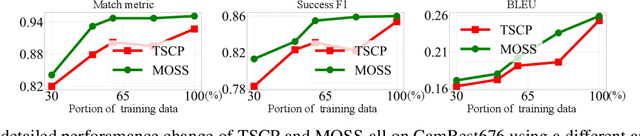

A major bottleneck in training end-to-end task-oriented dialog system is the lack of data. To utilize limited training data more efficiently, we propose Modular Supervision Network (MOSS), an encoder-decoder training framework that could incorporate supervision from various intermediate dialog system modules including natural language understanding, dialog state tracking, dialog policy learning, and natural language generation. With only 60% of the training data, MOSS-all (i.e., MOSS with supervision from all four dialog modules) outperforms state-of-the-art models on CamRest676. Moreover, introducing modular supervision has even bigger benefits when the dialog task has a more complex dialog state and action space. With only 40% of the training data, MOSS-all outperforms the state-of-the-art model on a complex laptop network troubleshooting dataset, LaptopNetwork, that we introduced. LaptopNetwork consists of conversations between real customers and customer service agents in Chinese. Moreover, MOSS framework can accommodate dialogs that have supervision from different dialog modules at both the framework level and model level. Therefore, MOSS is extremely flexible to update in a real-world deployment.