 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSS: End-to-End Dialog System Framework with Modular Supervision
Sep 12, 2019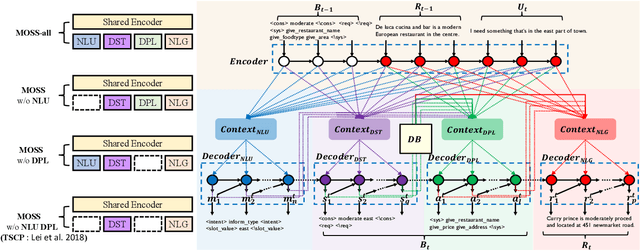
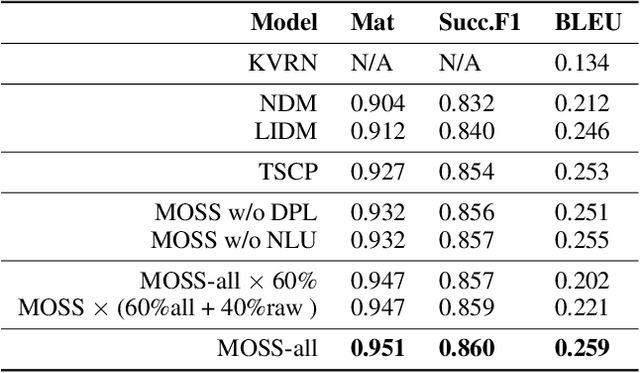
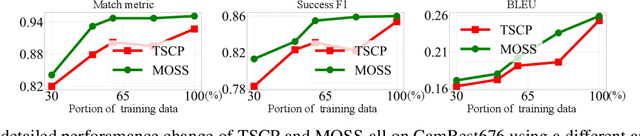

A major bottleneck in training end-to-end task-oriented dialog system is the lack of data. To utilize limited training data more efficiently, we propose Modular Supervision Network (MOSS), an encoder-decoder training framework that could incorporate supervision from various intermediate dialog system modules including natural language understanding, dialog state tracking, dialog policy learning, and natural language generation. With only 60% of the training data, MOSS-all (i.e., MOSS with supervision from all four dialog modules) outperforms state-of-the-art models on CamRest676. Moreover, introducing modular supervision has even bigger benefits when the dialog task has a more complex dialog state and action space. With only 40% of the training data, MOSS-all outperforms the state-of-the-art model on a complex laptop network troubleshooting dataset, LaptopNetwork, that we introduced. LaptopNetwork consists of conversations between real customers and customer service agents in Chinese. Moreover, MOSS framework can accommodate dialogs that have supervision from different dialog modules at both the framework level and model level. Therefore, MOSS is extremely flexible to update in a real-world deployment.
Structured Content Preservation for Unsupervised Text Style Transfer
Oct 31, 2018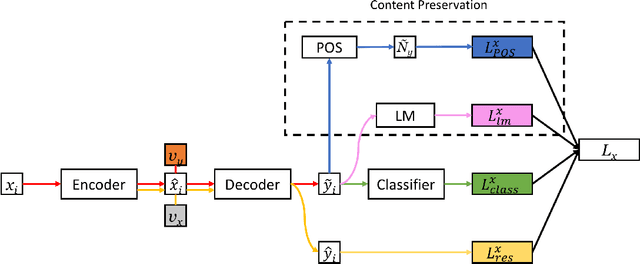
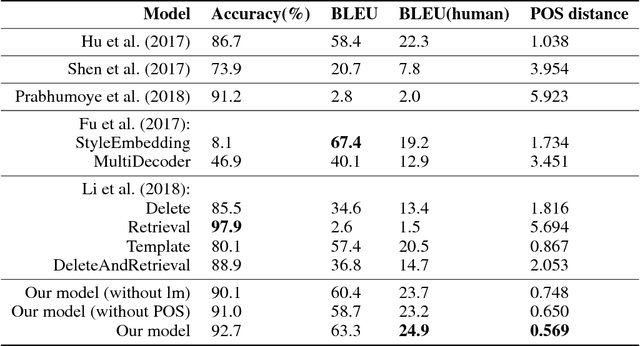
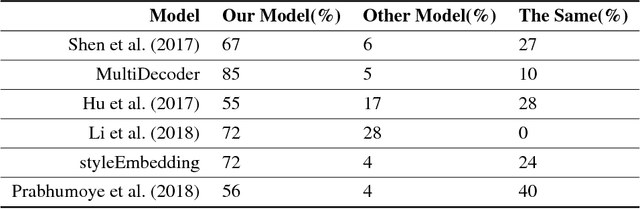

Text style transfer aims to modify the style of a sentence while keeping its content unchanged. Recent style transfer systems often fail to faithfully preserve the content after changing the style. This paper proposes a structured content preserving model that leverages linguistic information in the structured fine-grained supervisions to better preserve the style-independent content during style transfer. In particular, we achieve the goal by devising rich model objectives based on both the sentence's lexical information and a language model that conditions on content. The resulting model therefore is encouraged to retain the semantic meaning of the target sentences. We perform extensive experiments that compare our model to other existing approaches in the tasks of sentiment and political slant transfer. Our model achieves significant improvement in terms of both content preservation and style transfer in automatic and human evaluation.