 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Web Accessibility Audit with MLLMs as Copilots
Nov 05, 2025


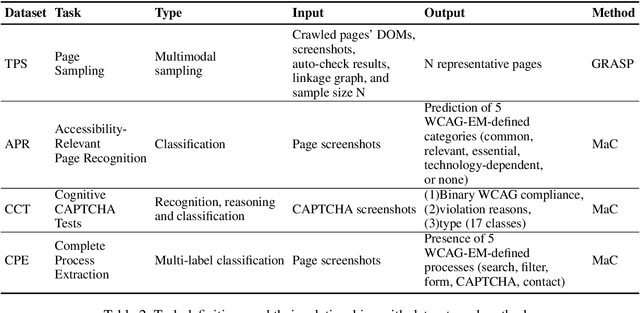
Ensuring web accessibility is crucial for advancing social welfare, justice, and equality in digital spaces, yet the vast majority of website user interfaces remain non-compliant, due in part to the resource-intensive and unscalable nature of current auditing practices. While WCAG-EM offers a structured methodology for site-wise conformance evaluation, it involves great human efforts and lacks practical support for execution at scale. In this work, we present an auditing framework, AAA, which operationalizes WCAG-EM through a human-AI partnership model. AAA is anchored by two key innovations: GRASP, a graph-based multimodal sampling method that ensures representative page coverage via learned embeddings of visual, textual, and relational cues; and MaC, a multimodal large language model-based copilot that supports auditors through cross-modal reasoning and intelligent assistance in high-effort tasks. Together, these components enable scalable, end-to-end web accessibility auditing, empowering human auditors with AI-enhanced assistance for real-world impact. We further contribute four novel datasets designed for benchmarking core stages of the audit pipeline. Extensive experiments demonstrate the effectiveness of our methods, providing insights that small-scale language models can serve as capable experts when fine-tuned.
FatesGS: Fast and Accurate Sparse-View Surface Reconstruction using Gaussian Splatting with Depth-Feature Consistency
Jan 08, 2025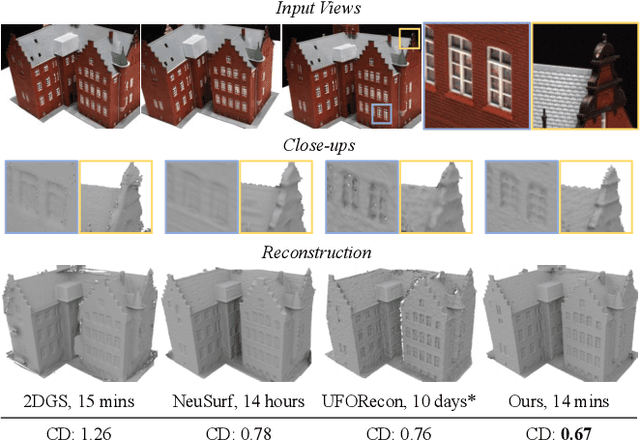
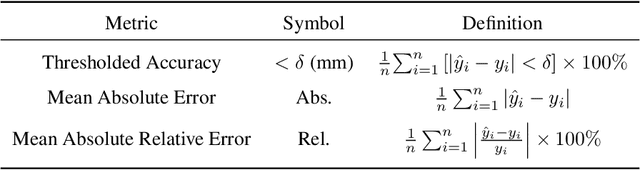

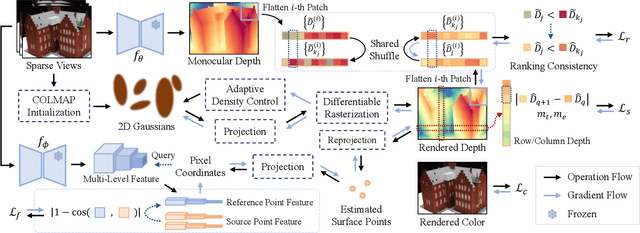
Recently, Gaussian Splatting has sparked a new trend in the field of computer vision. Apart from novel view synthesis, it has also been extended to the area of multi-view reconstruction. The latest methods facilitate complete, detailed surface reconstruction while ensuring fast training speed. However, these methods still require dense input views, and their output quality significantly degrades with sparse views. We observed that the Gaussian primitives tend to overfit the few training views, leading to noisy floaters and incomplete reconstruction surfaces. In this paper, we present an innovative sparse-view reconstruction framework that leverages intra-view depth and multi-view feature consistency to achieve remarkably accurate surface reconstruction. Specifically, we utilize monocular depth ranking information to supervise the consistency of depth distribution within patches and employ a smoothness loss to enhance the continuity of the distribution. To achieve finer surface reconstruction, we optimize the absolute position of depth through multi-view projection features. Extensive experiments on DTU and BlendedMVS demonstrate that our method outperforms state-of-the-art methods with a speedup of 60x to 200x, achieving swift and fine-grained mesh reconstruction without the need for costly pre-training.
Sparis: Neural Implicit Surface Reconstruction of Indoor Scenes from Sparse Views
Jan 02, 2025



In recent years, reconstructing indoor scene geometry from multi-view images has achieved encouraging accomplishments. Current methods incorporate monocular priors into neural implicit surface models to achieve high-quality reconstructions. However, these methods require hundreds of images for scene reconstruction. When only a limited number of views are available as input, the performance of monocular priors deteriorates due to scale ambiguity, leading to the collapse of the reconstructed scene geometry. In this paper, we propose a new method, named Sparis, for indoor surface reconstruction from sparse views. Specifically, we investigate the impact of monocular priors on sparse scene reconstruction, introducing a novel prior based on inter-image matching information. Our prior offers more accurate depth information while ensuring cross-view matching consistency. Additionally, we employ an angular filter strategy and an epipolar matching weight function, aiming to reduce errors due to view matching inaccuracies, thereby refining the inter-image prior for improved reconstruction accuracy. The experiments conducted on widely used benchmarks demonstrate superior performance in sparse-view scene reconstruction.
Universal Inceptive GNNs by Eliminating the Smoothness-generalization Dilemma
Dec 13, 2024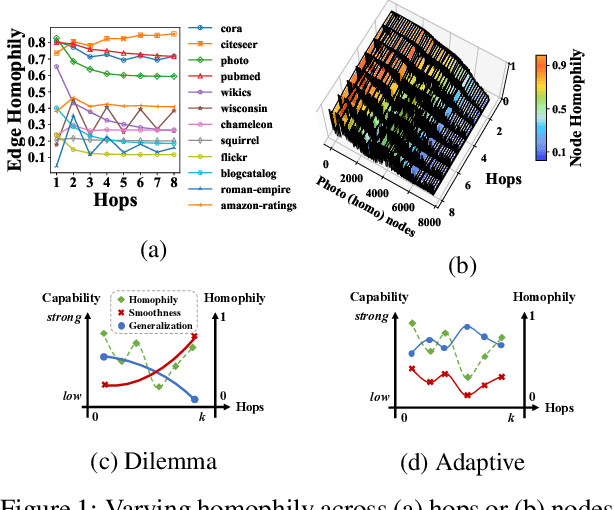

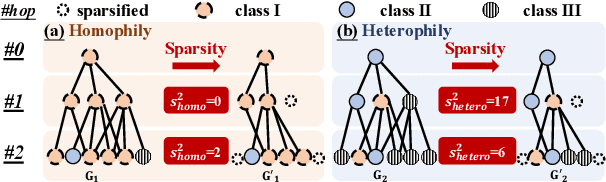

Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains, such as transaction and social net-works. However, their application is often hindered by the varyinghomophily levels across different orders of neighboring nodes, ne-cessitating separate model designs for homophilic and heterophilicgraphs. In this paper, we aim to develop a unified framework ca-pable of handling neighborhoods of various orders and homophilylevels. Through theoretical exploration, we identify a previouslyoverlooked architectural aspect in multi-hop learning: the cascadedependency, which leads to asmoothness-generalization dilemma.This dilemma significantly affects the learning process, especiallyin the context of high-order neighborhoods and heterophilic graphs.To resolve this issue, we propose an Inceptive Graph Neural Net-work (IGNN), a universal message-passing framework that replacesthe cascade dependency with an inceptive architecture. IGNN pro-vides independent representations for each hop, allowing personal-ized generalization capabilities, and captures neighborhood-wiserelationships to select appropriate receptive fields. Extensive ex-periments show that our IGNN outperforms 23 baseline methods,demonstrating superior performance on both homophilic and het-erophilic graphs, while also scaling efficiently to large graphs.
Implicit Filtering for Learning Neural Signed Distance Functions from 3D Point Clouds
Jul 18, 2024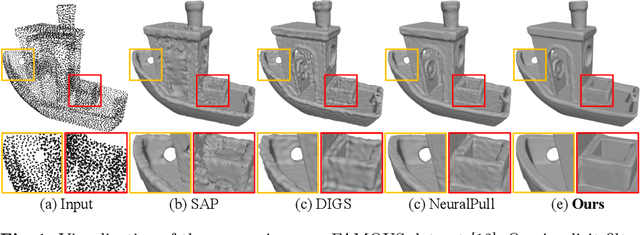
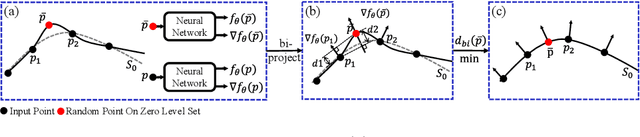
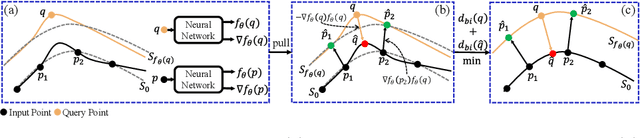
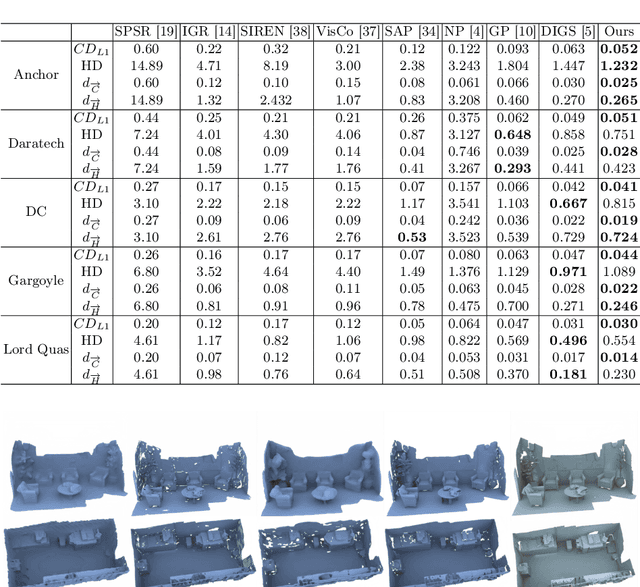
Neural signed distance functions (SDFs) have shown powerful ability in fitting the shape geometry. However, inferring continuous signed distance fields from discrete unoriented point clouds still remains a challenge. The neural network typically fits the shape with a rough surface and omits fine-grained geometric details such as shape edges and corners. In this paper, we propose a novel non-linear implicit filter to smooth the implicit field while preserving high-frequency geometry details. Our novelty lies in that we can filter the surface (zero level set) by the neighbor input points with gradients of the signed distance field. By moving the input raw point clouds along the gradient, our proposed implicit filtering can be extended to non-zero level sets to keep the promise consistency between different level sets, which consequently results in a better regularization of the zero level set. We conduct comprehensive experiments in surface reconstruction from objects and complex scene point clouds, the numerical and visual comparisons demonstrate our improvements over the state-of-the-art methods under the widely used benchmarks.
A Two-dimensional Zero-shot Dialogue State Tracking Evaluation Method using GPT-4
Jun 17, 2024
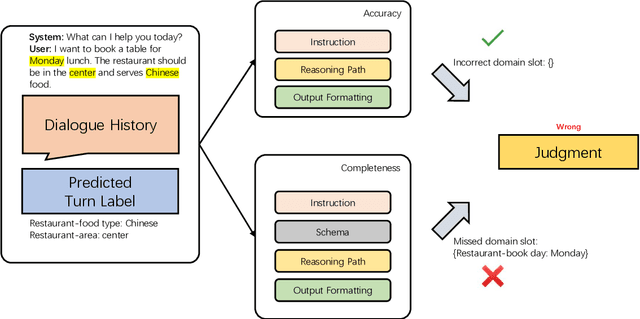
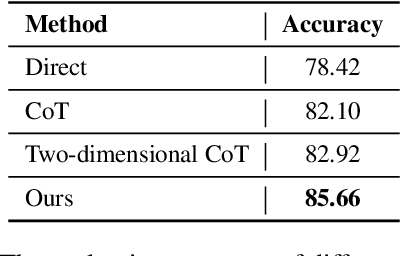
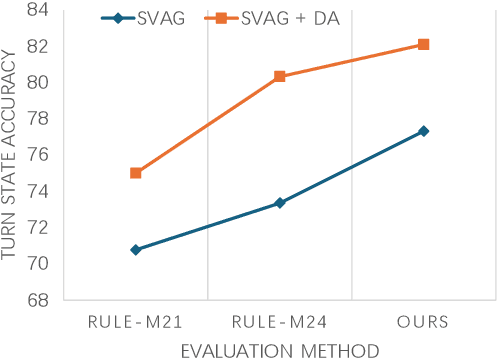
Dialogue state tracking (DST) is evaluated by exact matching methods, which rely on large amounts of labeled data and ignore semantic consistency, leading to over-evaluation. Currently, leveraging large language models (LLM) in evaluating natural language processing tasks has achieved promising results. However, using LLM for DST evaluation is still under explored. In this paper, we propose a two-dimensional zero-shot evaluation method for DST using GPT-4, which divides the evaluation into two dimensions: accuracy and completeness. Furthermore, we also design two manual reasoning paths in prompting to further improve the accuracy of evaluation. Experimental results show that our method achieves better performance compared to the baselines, and is consistent with traditional exact matching based methods.
Plan, Generate and Complicate: Improving Low-resource Dialogue State Tracking via Easy-to-Difficult Zero-shot Data Augmentation
Jun 13, 2024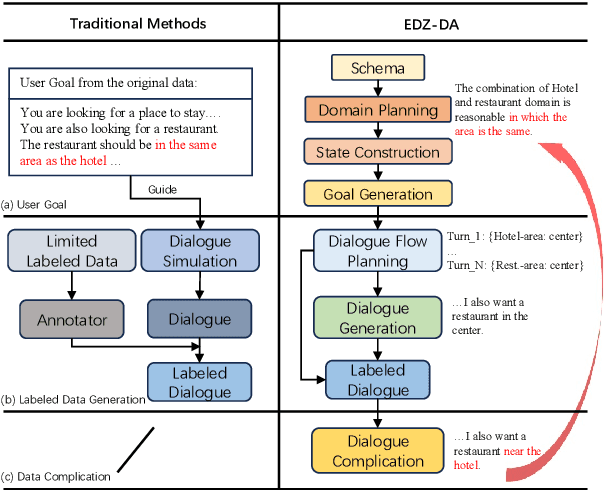
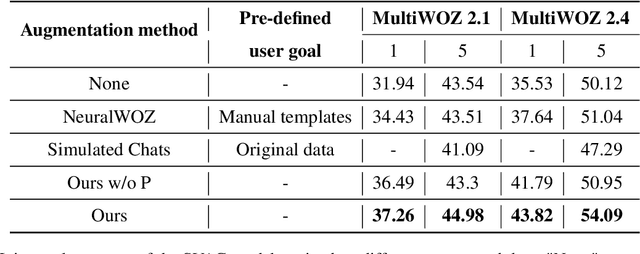
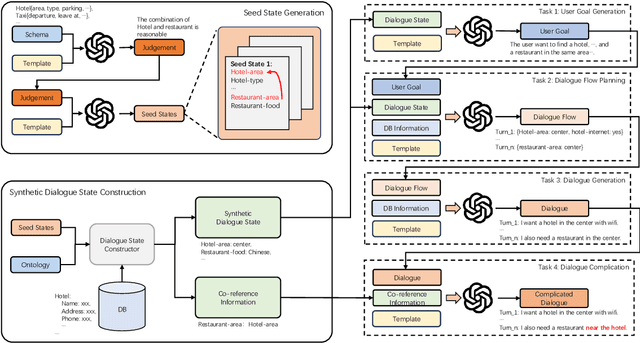
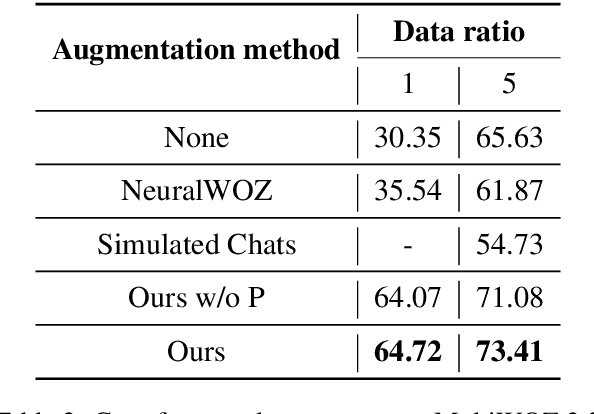
Data augmentation methods have been a promising direction to improve the performance of small models for low-resource dialogue state tracking. However, traditional methods rely on pre-defined user goals and neglect the importance of data complexity in this task. In this paper, we propose EDZ-DA, an Easy-to-Difficult Zero-shot Data Augmentation framework for low-resource dialogue state tracking that utilizes large language models to automatically catch the relationships of different domains and then generate the dialogue data. We also complicate the dialogues based on the domain relation to enhance the model's capability for co-reference slot tracking. Furthermore, we permute slot values to mitigate the influence of output orders and the problem of incomplete value generation. Experimental results illustrate the superiority of our proposed method compared to previous strong data augmentation baselines on MultiWOZ.
Towards a Unified Framework of Clustering-based Anomaly Detection
Jun 01, 2024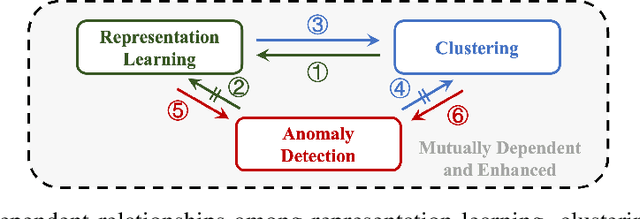
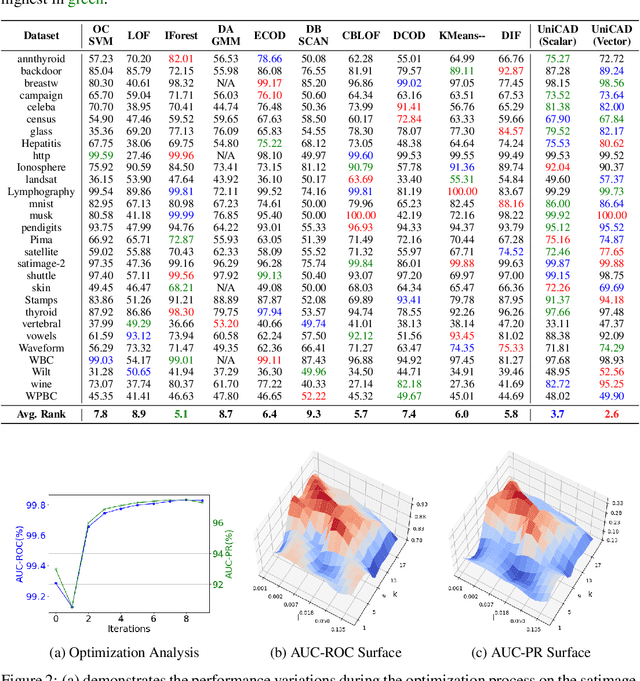
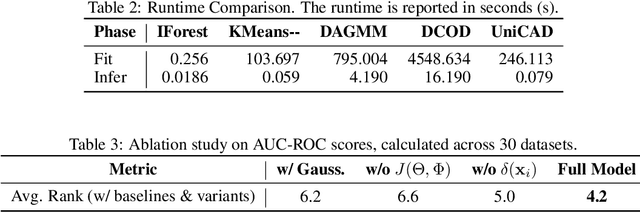
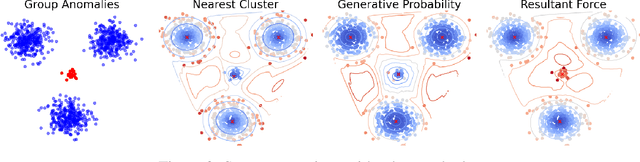
Unsupervised Anomaly Detection (UAD) plays a crucial role in identifying abnormal patterns within data without labeled examples, holding significant practical implications across various domains. Although the individual contributions of representation learning and clustering to anomaly detection are well-established, their interdependencies remain under-explored due to the absence of a unified theoretical framework. Consequently, their collective potential to enhance anomaly detection performance remains largely untapped. To bridge this gap, in this paper, we propose a novel probabilistic mixture model for anomaly detection to establish a theoretical connection among representation learning, clustering, and anomaly detection. By maximizing a novel anomaly-aware data likelihood, representation learning and clustering can effectively reduce the adverse impact of anomalous data and collaboratively benefit anomaly detection. Meanwhile, a theoretically substantiated anomaly score is naturally derived from this framework. Lastly, drawing inspiration from gravitational analysis in physics, we have devised an improved anomaly score that more effectively harnesses the combined power of representation learning and clustering. Extensive experiments, involving 17 baseline methods across 30 diverse datasets, validate the effectiveness and generalization capability of the proposed method, surpassing state-of-the-art methods.
Heterophilous Distribution Propagation for Graph Neural Networks
May 31, 2024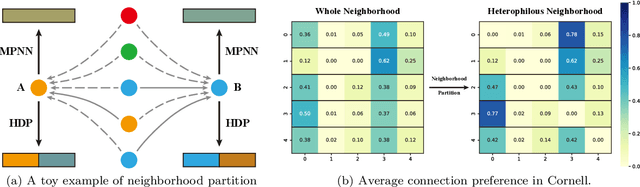
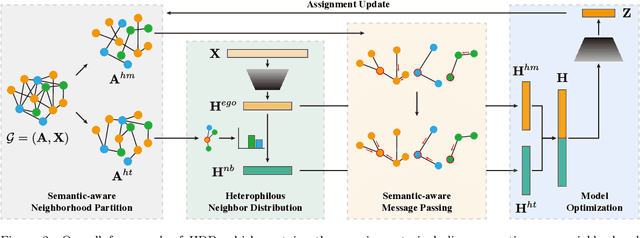
Graph Neural Networks (GNNs) have achieved remarkable success in various graph mining tasks by aggregating information from neighborhoods for representation learning. The success relies on the homophily assumption that nearby nodes exhibit similar behaviors, while it may be violated in many real-world graphs. Recently, heterophilous graph neural networks (HeterGNNs) have attracted increasing attention by modifying the neural message passing schema for heterophilous neighborhoods. However, they suffer from insufficient neighborhood partition and heterophily modeling, both of which are critical but challenging to break through. To tackle these challenges, in this paper, we propose heterophilous distribution propagation (HDP) for graph neural networks. Instead of aggregating information from all neighborhoods, HDP adaptively separates the neighbors into homophilous and heterphilous parts based on the pseudo assignments during training. The heterophilous neighborhood distribution is learned with orthogonality-oriented constraint via a trusted prototype contrastive learning paradigm. Both the homophilous and heterophilous patterns are propagated with a novel semantic-aware message passing mechanism. We conduct extensive experiments on 9 benchmark datasets with different levels of homophily. Experimental results show that our method outperforms representative baselines on heterophilous datasets.
Revisiting the Message Passing in Heterophilous Graph Neural Networks
May 28, 2024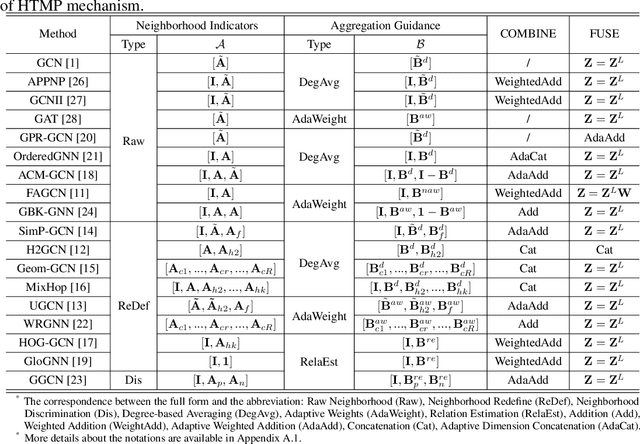
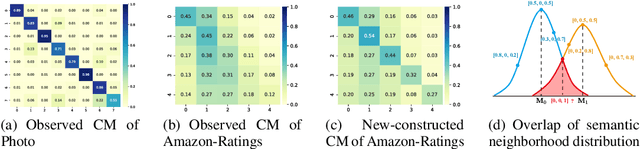
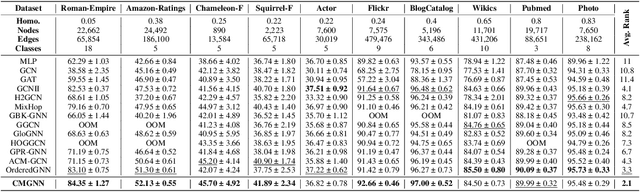
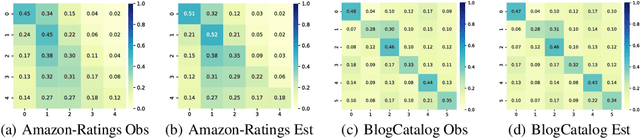
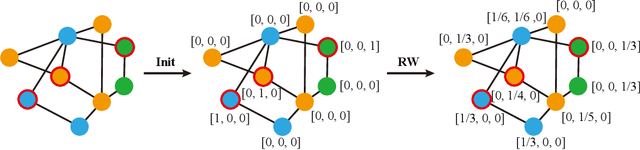
Graph Neural Networks (GNNs) have demonstrated strong performance in graph mining tasks due to their message-passing mechanism, which is aligned with the homophily assumption that adjacent nodes exhibit similar behaviors. However, in many real-world graphs, connected nodes may display contrasting behaviors, termed as heterophilous patterns, which has attracted increased interest in heterophilous GNNs (HTGNNs). Although the message-passing mechanism seems unsuitable for heterophilous graphs due to the propagation of class-irrelevant information, it is still widely used in many existing HTGNNs and consistently achieves notable success. This raises the question: why does message passing remain effective on heterophilous graphs? To answer this question, in this paper, we revisit the message-passing mechanisms in heterophilous graph neural networks and reformulate them into a unified heterophilious message-passing (HTMP) mechanism. Based on HTMP and empirical analysis, we reveal that the success of message passing in existing HTGNNs is attributed to implicitly enhancing the compatibility matrix among classes. Moreover, we argue that the full potential of the compatibility matrix is not completely achieved due to the existence of incomplete and noisy semantic neighborhoods in real-world heterophilous graphs. To bridge this gap, we introduce a new approach named CMGNN, which operates within the HTMP mechanism to explicitly leverage and improve the compatibility matrix. A thorough evaluation involving 10 benchmark datasets and comparative analysis against 13 well-established baselines highlights the superior performance of the HTMP mechanism and CMGNN method.