 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-dimensional Zero-shot Dialogue State Tracking Evaluation Method using GPT-4
Paper and Code

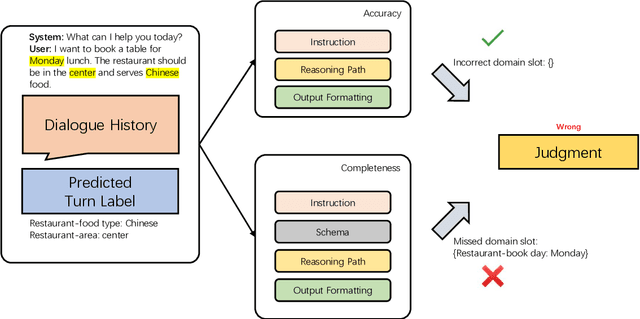
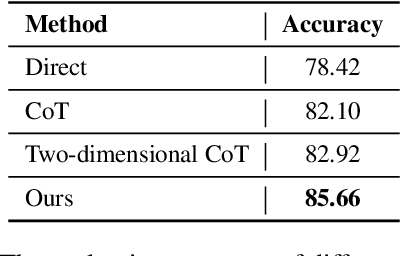
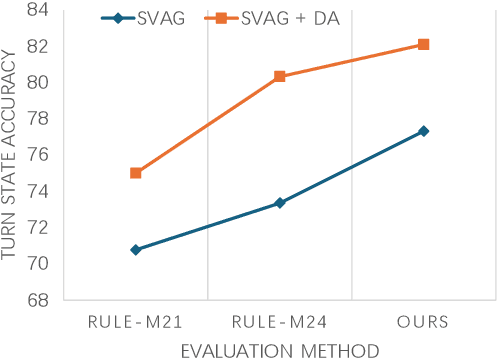
Dialogue state tracking (DST) is evaluated by exact matching methods, which rely on large amounts of labeled data and ignore semantic consistency, leading to over-evaluation. Currently, leveraging large language models (LLM) in evaluating natural language processing tasks has achieved promising results. However, using LLM for DST evaluation is still under explored. In this paper, we propose a two-dimensional zero-shot evaluation method for DST using GPT-4, which divides the evaluation into two dimensions: accuracy and completeness. Furthermore, we also design two manual reasoning paths in prompting to further improve the accuracy of evaluation. Experimental results show that our method achieves better performance compared to the baselines, and is consistent with traditional exact matching based methods.