 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVasGuideNet: Vascular Topology-Guided Couinaud Liver Segmentation with Structural Contrastive Loss
Feb 25, 2026Accurate Couinaud liver segmentation is critical for preoperative surgical planning and tumor localization.However, existing methods primarily rely on image intensity and spatial location cues, without explicitly modeling vascular topology. As a result, they often produce indistinct boundaries near vessels and show limited generalization under anatomical variability.We propose VasGuideNet, the first Couinaud segmentation framework explicitly guided by vascular topology. Specifically, skeletonized vessels, Euclidean distance transform (EDT)--derived geometry, and k-nearest neighbor (kNN) connectivity are encoded into topology features using Graph Convolutional Networks (GCNs). These features are then injected into a 3D encoder--decoder backbone via a cross-attention fusion module. To further improve inter-class separability and anatomical consistency, we introduce a Structural Contrastive Loss (SCL) with a global memory bank.On Task08_HepaticVessel and our private LASSD dataset, VasGuideNet achieves Dice scores of 83.68% and 76.65% with RVDs of 1.68 and 7.08, respectively. It consistently outperforms representative baselines including UNETR, Swin UNETR, and G-UNETR++, delivering higher Dice/mIoU and lower RVD across datasets, demonstrating its effectiveness for anatomically consistent segmentation. Code is available at https://github.com/Qacket/VasGuideNet.git.
Attention Beats Linear for Fast Implicit Neural Representation Generation
Jul 22, 2024



Implicit Neural Representation (INR) has gained increasing popularity as a data representation method, serving as a prerequisite for innovative generation models. Unlike gradient-based methods, which exhibit lower efficiency in inference, the adoption of hyper-network for generating parameters in Multi-Layer Perceptrons (MLP), responsible for executing INR functions, has surfaced as a promising and efficient alternative. However, as a global continuous function, MLP is challenging in modeling highly discontinuous signals, resulting in slow convergence during the training phase and inaccurate reconstruction performance. Moreover, MLP requires massive representation parameters, which implies inefficiencies in data representation. In this paper, we propose a novel Attention-based Localized INR (ANR) composed of a localized attention layer (LAL) and a global MLP that integrates coordinate features with data features and converts them to meaningful outputs. Subsequently, we design an instance representation framework that delivers a transformer-like hyper-network to represent data instances as a compact representation vector. With instance-specific representation vector and instance-agnostic ANR parameters, the target signals are well reconstructed as a continuous function. We further address aliasing artifacts with variational coordinates when obtaining the super-resolution inference results. Extensive experimentation across four datasets showcases the notable efficacy of our ANR method, e.g. enhancing the PSNR value from 37.95dB to 47.25dB on the CelebA dataset. Code is released at https://github.com/Roninton/ANR.
Heterophilous Distribution Propagation for Graph Neural Networks
May 31, 2024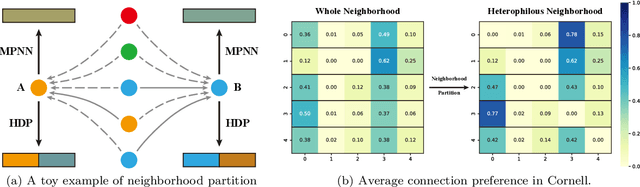
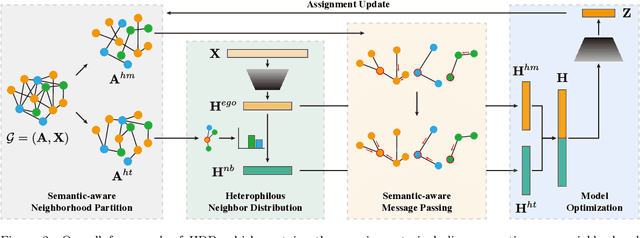
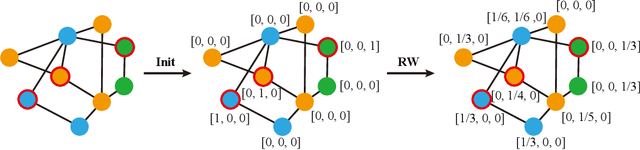
Graph Neural Networks (GNNs) have achieved remarkable success in various graph mining tasks by aggregating information from neighborhoods for representation learning. The success relies on the homophily assumption that nearby nodes exhibit similar behaviors, while it may be violated in many real-world graphs. Recently, heterophilous graph neural networks (HeterGNNs) have attracted increasing attention by modifying the neural message passing schema for heterophilous neighborhoods. However, they suffer from insufficient neighborhood partition and heterophily modeling, both of which are critical but challenging to break through. To tackle these challenges, in this paper, we propose heterophilous distribution propagation (HDP) for graph neural networks. Instead of aggregating information from all neighborhoods, HDP adaptively separates the neighbors into homophilous and heterphilous parts based on the pseudo assignments during training. The heterophilous neighborhood distribution is learned with orthogonality-oriented constraint via a trusted prototype contrastive learning paradigm. Both the homophilous and heterophilous patterns are propagated with a novel semantic-aware message passing mechanism. We conduct extensive experiments on 9 benchmark datasets with different levels of homophily. Experimental results show that our method outperforms representative baselines on heterophilous datasets.
Efficient Medical Image Segmentation Based on Knowledge Distillation
Aug 23, 2021
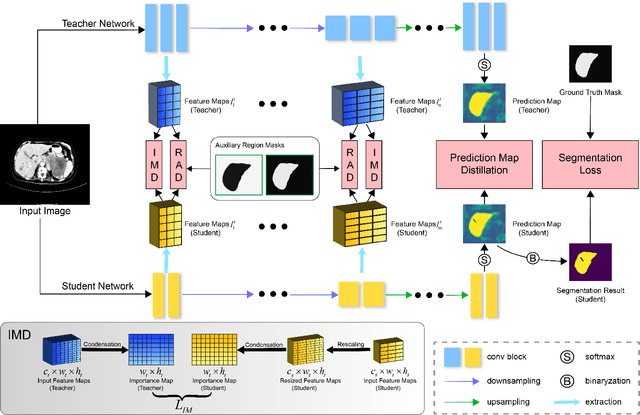
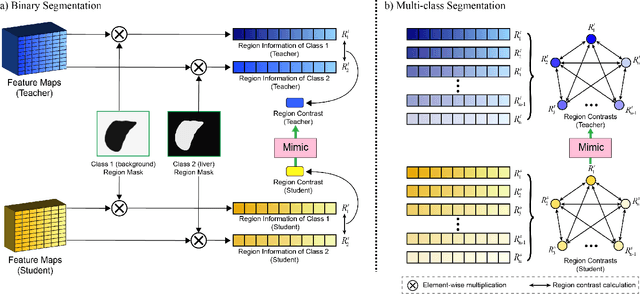
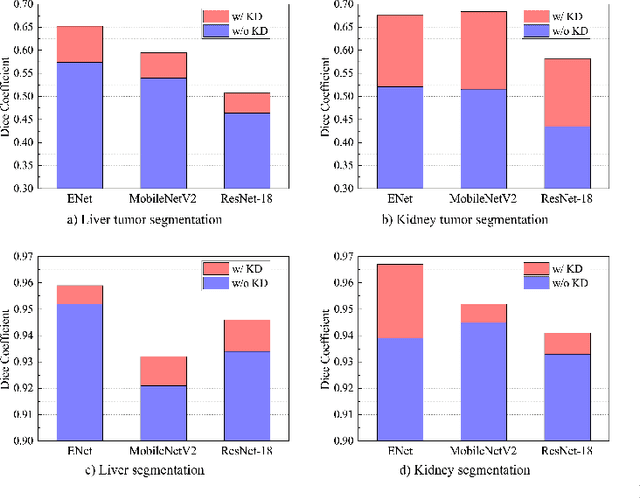
Recent advances have been made in applying convolutional neural networks to achieve more precise prediction results for medical image segmentation problems. However, the success of existing methods has highly relied on huge computational complexity and massive storage, which is impractical in the real-world scenario. To deal with this problem, we propose an efficient architecture by distilling knowledge from well-trained medical image segmentation networks to train another lightweight network. This architecture empowers the lightweight network to get a significant improvement on segmentation capability while retaining its runtime efficiency. We further devise a novel distillation module tailored for medical image segmentation to transfer semantic region information from teacher to student network. It forces the student network to mimic the extent of difference of representations calculated from different tissue regions. This module avoids the ambiguous boundary problem encountered when dealing with medical imaging but instead encodes the internal information of each semantic region for transferring. Benefited from our module, the lightweight network could receive an improvement of up to 32.6% in our experiment while maintaining its portability in the inference phase. The entire structure has been verified on two widely accepted public CT datasets LiTS17 and KiTS19. We demonstrate that a lightweight network distilled by our method has non-negligible value in the scenario which requires relatively high operating speed and low storage usage.