 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Beats Linear for Fast Implicit Neural Representation Generation
Jul 22, 2024



Implicit Neural Representation (INR) has gained increasing popularity as a data representation method, serving as a prerequisite for innovative generation models. Unlike gradient-based methods, which exhibit lower efficiency in inference, the adoption of hyper-network for generating parameters in Multi-Layer Perceptrons (MLP), responsible for executing INR functions, has surfaced as a promising and efficient alternative. However, as a global continuous function, MLP is challenging in modeling highly discontinuous signals, resulting in slow convergence during the training phase and inaccurate reconstruction performance. Moreover, MLP requires massive representation parameters, which implies inefficiencies in data representation. In this paper, we propose a novel Attention-based Localized INR (ANR) composed of a localized attention layer (LAL) and a global MLP that integrates coordinate features with data features and converts them to meaningful outputs. Subsequently, we design an instance representation framework that delivers a transformer-like hyper-network to represent data instances as a compact representation vector. With instance-specific representation vector and instance-agnostic ANR parameters, the target signals are well reconstructed as a continuous function. We further address aliasing artifacts with variational coordinates when obtaining the super-resolution inference results. Extensive experimentation across four datasets showcases the notable efficacy of our ANR method, e.g. enhancing the PSNR value from 37.95dB to 47.25dB on the CelebA dataset. Code is released at https://github.com/Roninton/ANR.
3D Facial Geometry Recovery from a Depth View with Attention Guided Generative Adversarial Network
Sep 02, 2020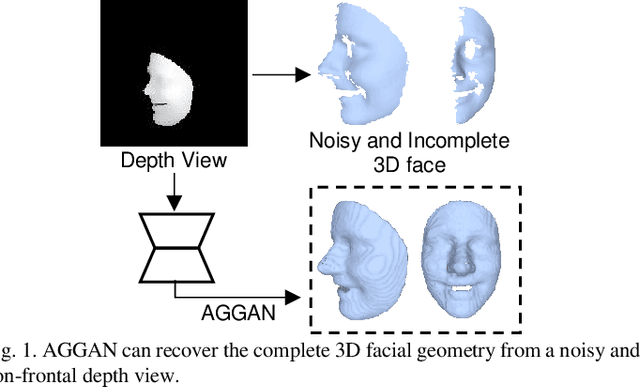


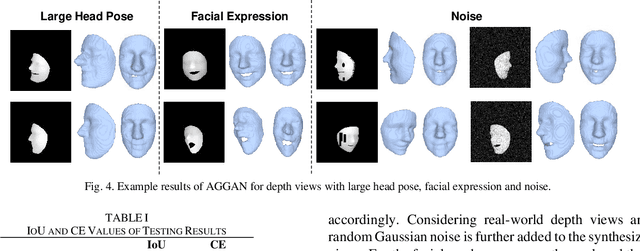
We present to recover the complete 3D facial geometry from a single depth view by proposing an Attention Guided Generative Adversarial Networks (AGGAN). In contrast to existing work which normally requires two or more depth views to recover a full 3D facial geometry, the proposed AGGAN is able to generate a dense 3D voxel grid of the face from a single unconstrained depth view. Specifically, AGGAN encodes the 3D facial geometry within a voxel space and utilizes an attention-guided GAN to model the illposed 2.5D depth-3D mapping. Multiple loss functions, which enforce the 3D facial geometry consistency, together with a prior distribution of facial surface points in voxel space are incorporated to guide the training process. Both qualitative and quantitative comparisons show that AGGAN recovers a more complete and smoother 3D facial shape, with the capability to handle a much wider range of view angles and resist to noise in the depth view than conventional methods
Real-time 3D Facial Tracking via Cascaded Compositional Learning
Sep 02, 2020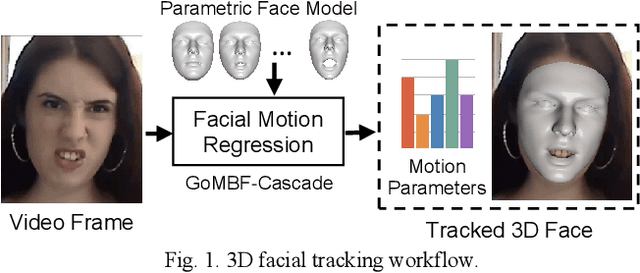
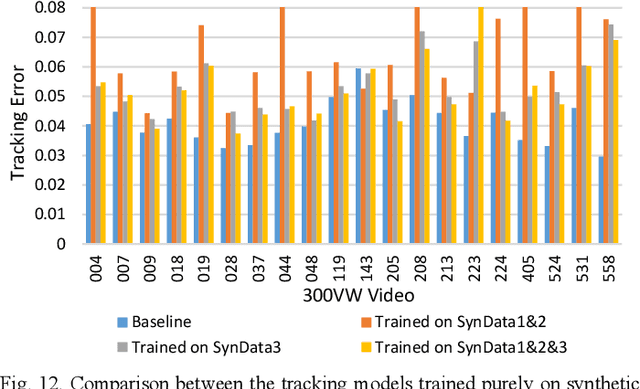
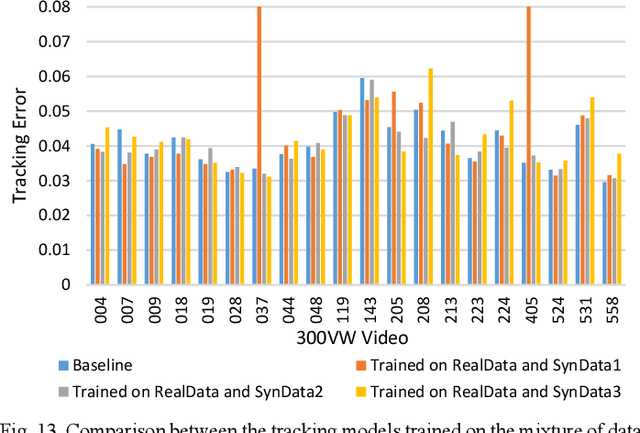
We propose to learn a cascade of globally-optimized modular boosted ferns (GoMBF) to solve multi-modal facial motion regression for real-time 3D facial tracking from a monocular RGB camera. GoMBF is a deep composition of multiple regression models with each is a boosted ferns initially trained to predict partial motion parameters of the same modality, and then concatenated together via a global optimization step to form a singular strong boosted ferns that can effectively handle the whole regression target. It can explicitly cope with the modality variety in output variables, while manifesting increased fitting power and a faster learning speed comparing against the conventional boosted ferns. By further cascading a sequence of GoMBFs (GoMBF-Cascade) to regress facial motion parameters, we achieve competitive tracking performance on a variety of in-the-wild videos comparing to the state-of-the-art methods, which require much more training data or have higher computational complexity. It provides a robust and highly elegant solution to real-time 3D facial tracking using a small set of training data and hence makes it more practical in real-world applications.