 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI Hippocampus: How Far are We From Human Memory?
Jan 14, 2026Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models and Multi-Modal LLMs. As these models transition from static predictors to interactive systems capable of continual learning and personalized inference, the incorporation of memory mechanisms has emerged as a central theme in their architectural and functional evolution. This survey presents a comprehensive and structured synthesis of memory in LLMs and MLLMs, organizing the literature into a cohesive taxonomy comprising implicit, explicit, and agentic memory paradigms. Specifically, the survey delineates three primary memory frameworks. Implicit memory refers to the knowledge embedded within the internal parameters of pre-trained transformers, encompassing their capacity for memorization, associative retrieval, and contextual reasoning. Recent work has explored methods to interpret, manipulate, and reconfigure this latent memory. Explicit memory involves external storage and retrieval components designed to augment model outputs with dynamic, queryable knowledge representations, such as textual corpora, dense vectors, and graph-based structures, thereby enabling scalable and updatable interaction with information sources. Agentic memory introduces persistent, temporally extended memory structures within autonomous agents, facilitating long-term planning, self-consistency, and collaborative behavior in multi-agent systems, with relevance to embodied and interactive AI. Extending beyond text, the survey examines the integration of memory within multi-modal settings, where coherence across vision, language, audio, and action modalities is essential. Key architectural advances, benchmark tasks, and open challenges are discussed, including issues related to memory capacity, alignment, factual consistency, and cross-system interoperability.
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
Dec 19, 2025We introduce Native Parallel Reasoner (NPR), a teacher-free framework that enables Large Language Models (LLMs) to self-evolve genuine parallel reasoning capabilities. NPR transforms the model from sequential emulation to native parallel cognition through three key innovations: 1) a self-distilled progressive training paradigm that transitions from ``cold-start'' format discovery to strict topological constraints without external supervision; 2) a novel Parallel-Aware Policy Optimization (PAPO) algorithm that optimizes branching policies directly within the execution graph, allowing the model to learn adaptive decomposition via trial and error; and 3) a robust NPR Engine that refactors memory management and flow control of SGLang to enable stable, large-scale parallel RL training. Across eight reasoning benchmarks, NPR trained on Qwen3-4B achieves performance gains of up to 24.5% and inference speedups up to 4.6x. Unlike prior baselines that often fall back to autoregressive decoding, NPR demonstrates 100% genuine parallel execution, establishing a new standard for self-evolving, efficient, and scalable agentic reasoning.
Interpretable Reward Model via Sparse Autoencoder
Aug 12, 2025Large language models (LLMs) have been widely deployed across numerous fields. Reinforcement Learning from Human Feedback (RLHF) leverages reward models (RMs) as proxies for human preferences to align LLM behaviors with human values, making the accuracy, reliability, and interpretability of RMs critical for effective alignment. However, traditional RMs lack interpretability, offer limited insight into the reasoning behind reward assignments, and are inflexible toward user preference shifts. While recent multidimensional RMs aim for improved interpretability, they often fail to provide feature-level attribution and require costly annotations. To overcome these limitations, we introduce the Sparse Autoencoder-enhanced Reward Model (\textbf{SARM}), a novel architecture that integrates a pretrained Sparse Autoencoder (SAE) into a reward model. SARM maps the hidden activations of LLM-based RM into an interpretable, sparse, and monosemantic feature space, from which a scalar head aggregates feature activations to produce transparent and conceptually meaningful reward scores. Empirical evaluations demonstrate that SARM facilitates direct feature-level attribution of reward assignments, allows dynamic adjustment to preference shifts, and achieves superior alignment performance compared to conventional reward models. Our code is available at https://github.com/schrieffer-z/sarm.
Marine Chlorophyll Prediction and Driver Analysis based on LSTM-RF Hybrid Models
Aug 07, 2025Marine chlorophyll concentration is an important indicator of ecosystem health and carbon cycle strength, and its accurate prediction is crucial for red tide warning and ecological response. In this paper, we propose a LSTM-RF hybrid model that combines the advantages of LSTM and RF, which solves the deficiencies of a single model in time-series modelling and nonlinear feature portrayal. Trained with multi-source ocean data(temperature, salinity, dissolved oxygen, etc.), the experimental results show that the LSTM-RF model has an R^2 of 0.5386, an MSE of 0.005806, and an MAE of 0.057147 on the test set, which is significantly better than using LSTM (R^2 = 0.0208) and RF (R^2 =0.4934) alone , respectively. The standardised treatment and sliding window approach improved the prediction accuracy of the model and provided an innovative solution for high-frequency prediction of marine ecological variables.
A Context-Aware Dual-Metric Framework for Confidence Estimation in Large Language Models
Aug 01, 2025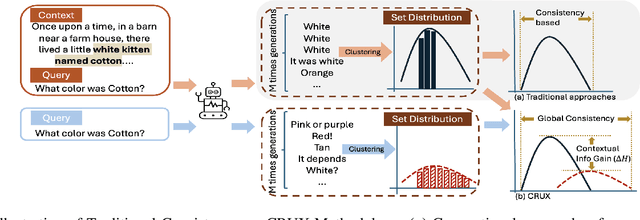
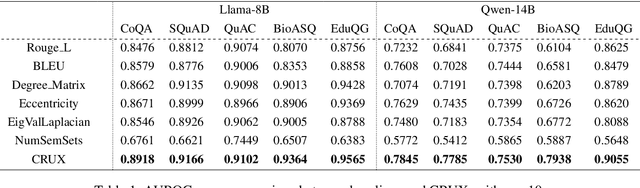

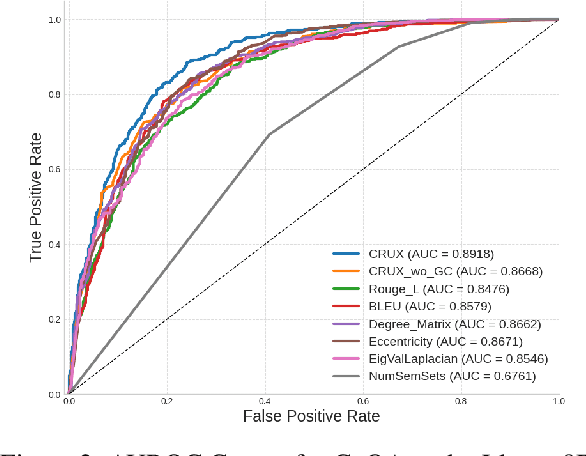
Accurate confidence estimation is essential for trustworthy large language models (LLMs) systems, as it empowers the user to determine when to trust outputs and enables reliable deployment in safety-critical applications. Current confidence estimation methods for LLMs neglect the relevance between responses and contextual information, a crucial factor in output quality evaluation, particularly in scenarios where background knowledge is provided. To bridge this gap, we propose CRUX (Context-aware entropy Reduction and Unified consistency eXamination), the first framework that integrates context faithfulness and consistency for confidence estimation via two novel metrics. First, contextual entropy reduction represents data uncertainty with the information gain through contrastive sampling with and without context. Second, unified consistency examination captures potential model uncertainty through the global consistency of the generated answers with and without context. Experiments across three benchmark datasets (CoQA, SQuAD, QuAC) and two domain-specific datasets (BioASQ, EduQG) demonstrate CRUX's effectiveness, achieving the highest AUROC than existing baselines.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
Video-CoT: A Comprehensive Dataset for Spatiotemporal Understanding of Videos Based on Chain-of-Thought
Jun 12, 2025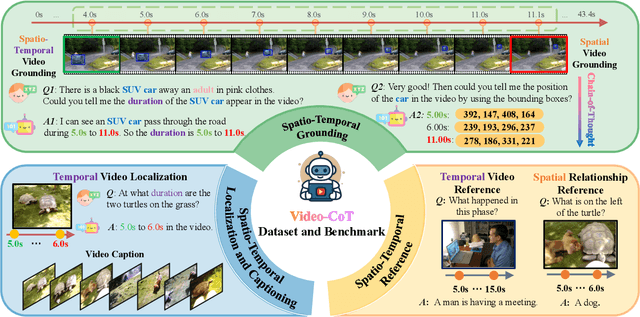
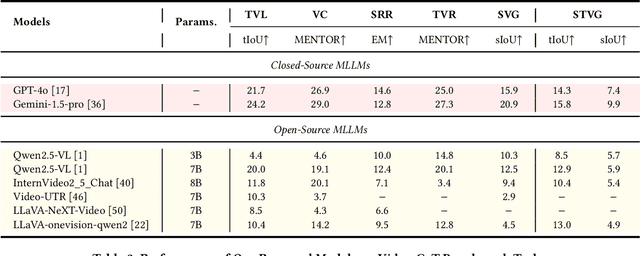
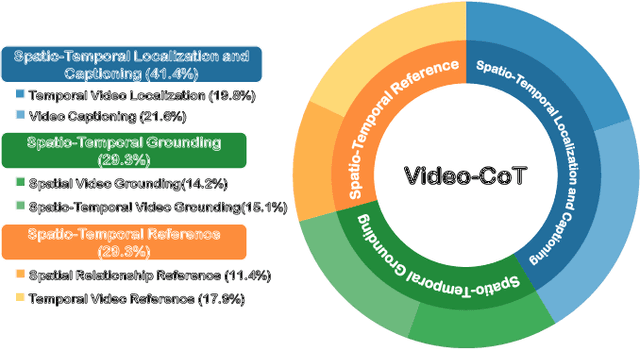

Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis. To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spa-tiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics. Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, high-lighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset and benchmark open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area. Project website:https://video-cot.github.io/ .
Attention Beats Linear for Fast Implicit Neural Representation Generation
Jul 22, 2024



Implicit Neural Representation (INR) has gained increasing popularity as a data representation method, serving as a prerequisite for innovative generation models. Unlike gradient-based methods, which exhibit lower efficiency in inference, the adoption of hyper-network for generating parameters in Multi-Layer Perceptrons (MLP), responsible for executing INR functions, has surfaced as a promising and efficient alternative. However, as a global continuous function, MLP is challenging in modeling highly discontinuous signals, resulting in slow convergence during the training phase and inaccurate reconstruction performance. Moreover, MLP requires massive representation parameters, which implies inefficiencies in data representation. In this paper, we propose a novel Attention-based Localized INR (ANR) composed of a localized attention layer (LAL) and a global MLP that integrates coordinate features with data features and converts them to meaningful outputs. Subsequently, we design an instance representation framework that delivers a transformer-like hyper-network to represent data instances as a compact representation vector. With instance-specific representation vector and instance-agnostic ANR parameters, the target signals are well reconstructed as a continuous function. We further address aliasing artifacts with variational coordinates when obtaining the super-resolution inference results. Extensive experimentation across four datasets showcases the notable efficacy of our ANR method, e.g. enhancing the PSNR value from 37.95dB to 47.25dB on the CelebA dataset. Code is released at https://github.com/Roninton/ANR.
Bilateral Unsymmetrical Graph Contrastive Learning for Recommendation
Mar 22, 2024



Recent methods utilize graph contrastive Learning within graph-structured user-item interaction data for collaborative filtering and have demonstrated their efficacy in recommendation tasks. However, they ignore that the difference relation density of nodes between the user- and item-side causes the adaptability of graphs on bilateral nodes to be different after multi-hop graph interaction calculation, which limits existing models to achieve ideal results. To solve this issue, we propose a novel framework for recommendation tasks called Bilateral Unsymmetrical Graph Contrastive Learning (BusGCL) that consider the bilateral unsymmetry on user-item node relation density for sliced user and item graph reasoning better with bilateral slicing contrastive training. Especially, taking into account the aggregation ability of hypergraph-based graph convolutional network (GCN) in digging implicit similarities is more suitable for user nodes, embeddings generated from three different modules: hypergraph-based GCN, GCN and perturbed GCN, are sliced into two subviews by the user- and item-side respectively, and selectively combined into subview pairs bilaterally based on the characteristics of inter-node relation structure. Furthermore, to align the distribution of user and item embeddings after aggregation, a dispersing loss is leveraged to adjust the mutual distance between all embeddings for maintaining learning ability. Comprehensive experiments on two public datasets have proved the superiority of BusGCL in comparison to various recommendation methods. Other models can simply utilize our bilateral slicing contrastive learning to enhance recommending performance without incurring extra expenses.
YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception
Aug 24, 2022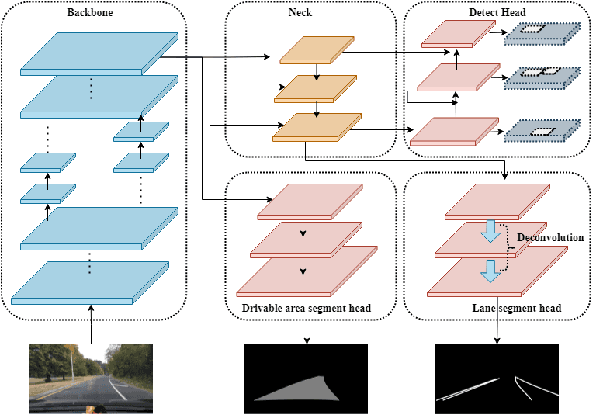
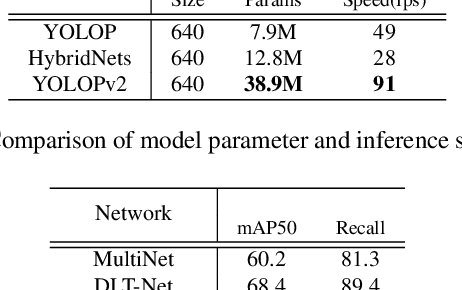
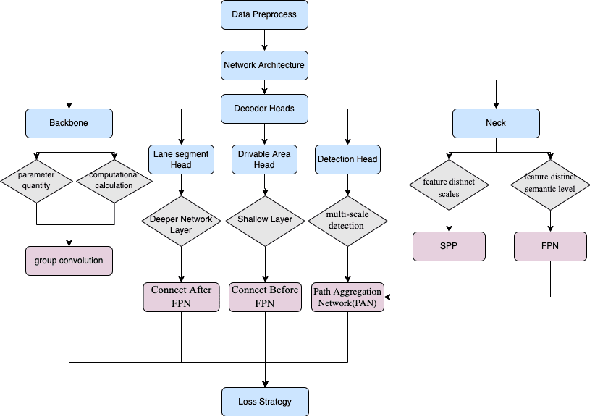
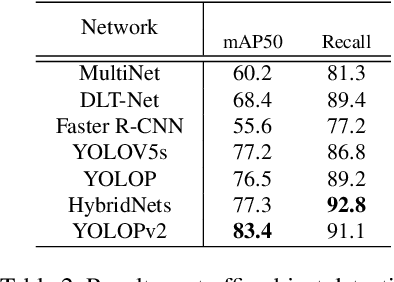
Over the last decade, multi-tasking learning approaches have achieved promising results in solving panoptic driving perception problems, providing both high-precision and high-efficiency performance. It has become a popular paradigm when designing networks for real-time practical autonomous driving system, where computation resources are limited. This paper proposed an effective and efficient multi-task learning network to simultaneously perform the task of traffic object detection, drivable road area segmentation and lane detection. Our model achieved the new state-of-the-art (SOTA) performance in terms of accuracy and speed on the challenging BDD100K dataset. Especially, the inference time is reduced by half compared to the previous SOTA model. Code will be released in the near future.