 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception
Aug 24, 2022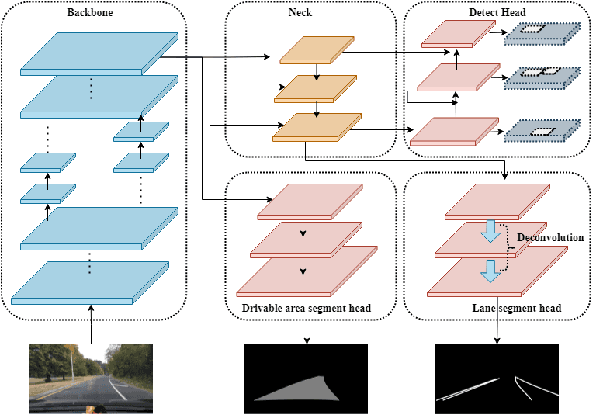
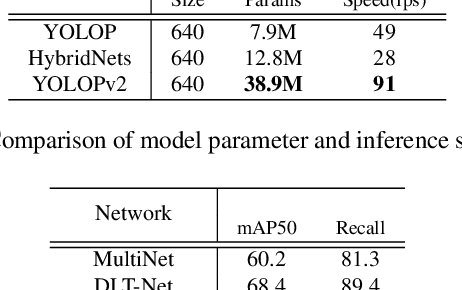
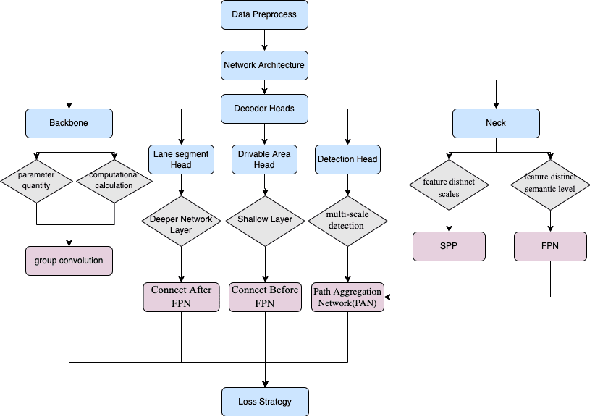
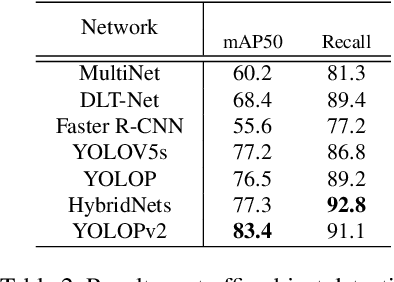
Over the last decade, multi-tasking learning approaches have achieved promising results in solving panoptic driving perception problems, providing both high-precision and high-efficiency performance. It has become a popular paradigm when designing networks for real-time practical autonomous driving system, where computation resources are limited. This paper proposed an effective and efficient multi-task learning network to simultaneously perform the task of traffic object detection, drivable road area segmentation and lane detection. Our model achieved the new state-of-the-art (SOTA) performance in terms of accuracy and speed on the challenging BDD100K dataset. Especially, the inference time is reduced by half compared to the previous SOTA model. Code will be released in the near future.
Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing
Mar 23, 2022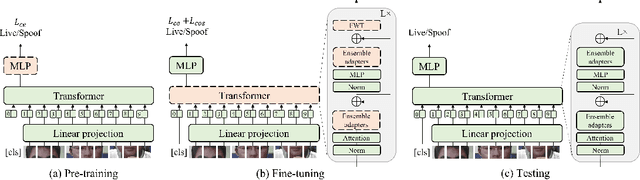
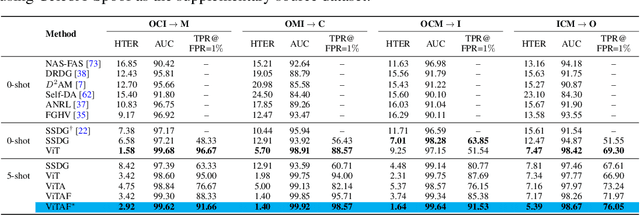
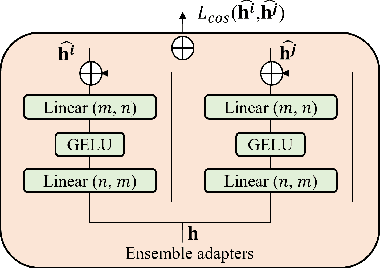
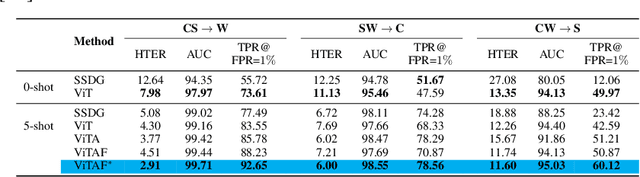
While recent face anti-spoofing methods perform well under the intra-domain setups, an effective approach needs to account for much larger appearance variations of images acquired in complex scenes with different sensors for robust performance. In this paper, we present adaptive vision transformers (ViT) for robust cross-domain face anti-spoofing. Specifically, we adopt ViT as a backbone to exploit its strength to account for long-range dependencies among pixels. We further introduce the ensemble adapters module and feature-wise transformation layers in the ViT to adapt to different domains for robust performance with a few samples. Experiments on several benchmark datasets show that the proposed models achieve both robust and competitive performance against the state-of-the-art methods.
CLIP2TV: An Empirical Study on Transformer-based Methods for Video-Text Retrieval
Nov 10, 2021

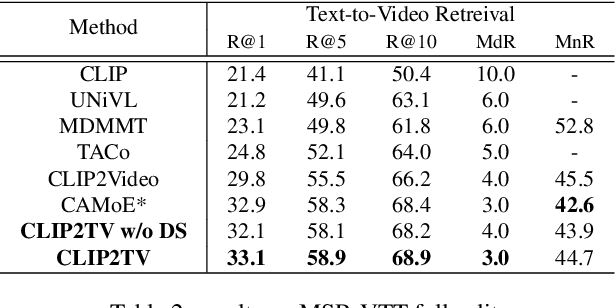

Modern video-text retrieval frameworks basically consist of three parts: video encoder, text encoder and the similarity head. With the success on both visual and textual representation learning, transformer based encoders and fusion methods have also been adopted in the field of video-text retrieval. In this report, we present CLIP2TV, aiming at exploring where the critical elements lie in transformer based methods. To achieve this, We first revisit some recent works on multi-modal learning, then introduce some techniques into video-text retrieval, finally evaluate them through extensive experiments in different configurations. Notably, CLIP2TV achieves 52.9@R1 on MSR-VTT dataset, outperforming the previous SOTA result by 4.1%.
Learnable Cost Volume Using the Cayley Representation
Jul 21, 2020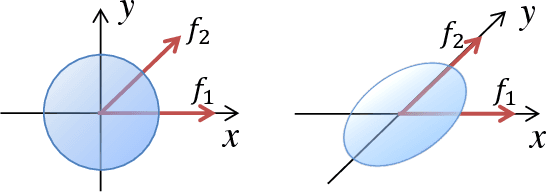
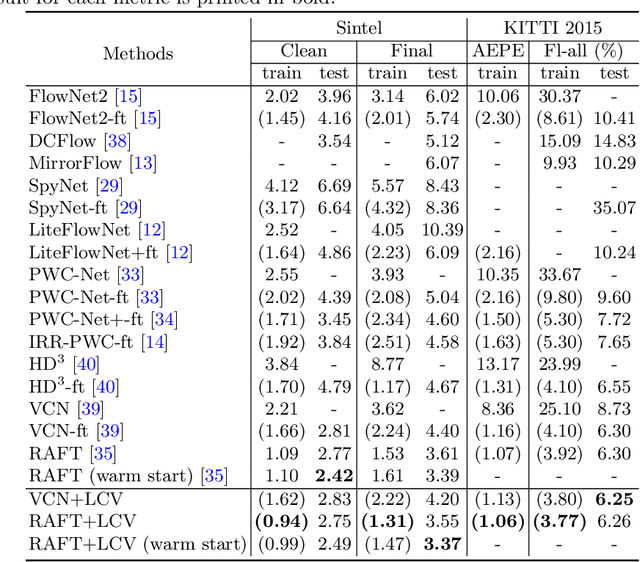

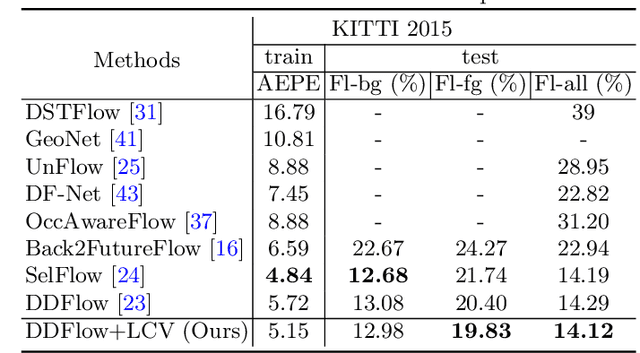
Cost volume is an essential component of recent deep models for optical flow estimation and is usually constructed by calculating the inner product between two feature vectors. However, the standard inner product in the commonly-used cost volume may limit the representation capacity of flow models because it neglects the correlation among different channel dimensions and weighs each dimension equally. To address this issue, we propose a learnable cost volume (LCV) using an elliptical inner product, which generalizes the standard inner product by a positive definite kernel matrix. To guarantee its positive definiteness, we perform spectral decomposition on the kernel matrix and re-parameterize it via the Cayley representation. The proposed LCV is a lightweight module and can be easily plugged into existing models to replace the vanilla cost volume. Experimental results show that the LCV module not only improves the accuracy of state-of-the-art models on standard benchmarks, but also promotes their robustness against illumination change, noises, and adversarial perturbations of the input signals.