 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferences That Matter: Auditing Models for Capability Gap Discovery and Rectification
Dec 18, 2025

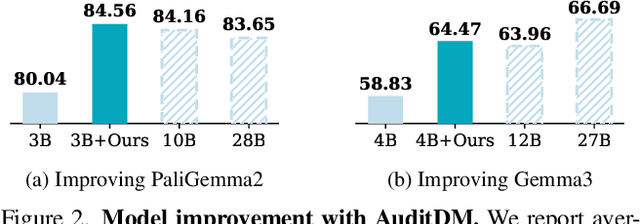
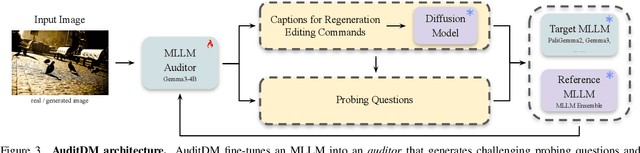
Conventional evaluation methods for multimodal LLMs (MLLMs) lack interpretability and are often insufficient to fully disclose significant capability gaps across models. To address this, we introduce AuditDM, an automated framework that actively discovers and rectifies MLLM failure modes by auditing their divergence. AuditDM fine-tunes an MLLM as an auditor via reinforcement learning to generate challenging questions and counterfactual images that maximize disagreement among target models. Once trained, the auditor uncovers diverse, interpretable exemplars that reveal model weaknesses and serve as annotation-free data for rectification. When applied to SoTA models like Gemma-3 and PaliGemma-2, AuditDM discovers more than 20 distinct failure types. Fine-tuning on these discoveries consistently improves all models across 16 benchmarks, and enables a 3B model to surpass its 28B counterpart. Our results suggest that as data scaling hits diminishing returns, targeted model auditing offers an effective path to model diagnosis and improvement.
Rethinking Domain Generalization for Face Anti-spoofing: Separability and Alignment
Mar 23, 2023This work studies the generalization issue of face anti-spoofing (FAS) models on domain gaps, such as image resolution, blurriness and sensor variations. Most prior works regard domain-specific signals as a negative impact, and apply metric learning or adversarial losses to remove them from feature representation. Though learning a domain-invariant feature space is viable for the training data, we show that the feature shift still exists in an unseen test domain, which backfires on the generalizability of the classifier. In this work, instead of constructing a domain-invariant feature space, we encourage domain separability while aligning the live-to-spoof transition (i.e., the trajectory from live to spoof) to be the same for all domains. We formulate this FAS strategy of separability and alignment (SA-FAS) as a problem of invariant risk minimization (IRM), and learn domain-variant feature representation but domain-invariant classifier. We demonstrate the effectiveness of SA-FAS on challenging cross-domain FAS datasets and establish state-of-the-art performance.
Multi-domain Learning for Updating Face Anti-spoofing Models
Aug 23, 2022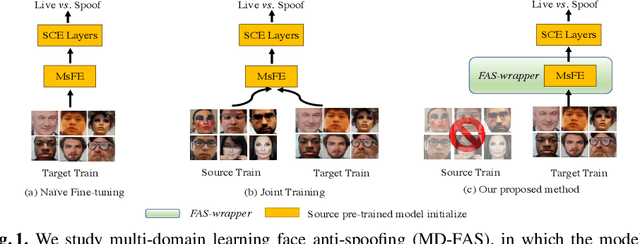
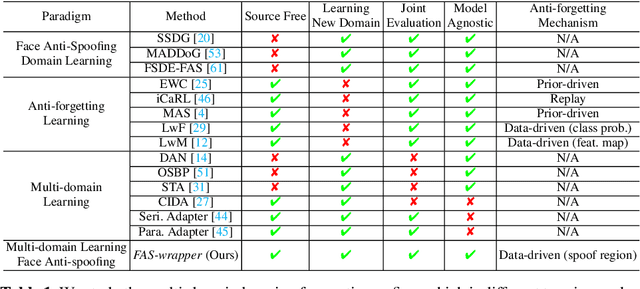
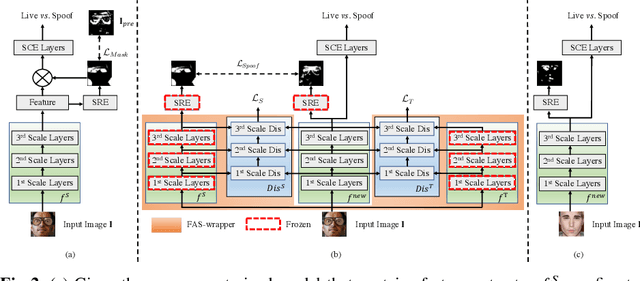
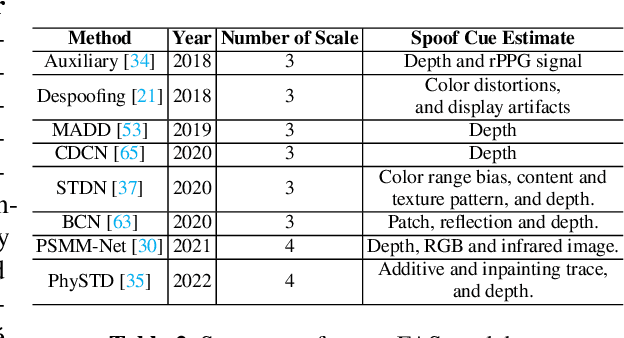
In this work, we study multi-domain learning for face anti-spoofing(MD-FAS), where a pre-trained FAS model needs to be updated to perform equally well on both source and target domains while only using target domain data for updating. We present a new model for MD-FAS, which addresses the forgetting issue when learning new domain data, while possessing a high level of adaptability. First, we devise a simple yet effective module, called spoof region estimator(SRE), to identify spoof traces in the spoof image. Such spoof traces reflect the source pre-trained model's responses that help upgraded models combat catastrophic forgetting during updating. Unlike prior works that estimate spoof traces which generate multiple outputs or a low-resolution binary mask, SRE produces one single, detailed pixel-wise estimate in an unsupervised manner. Secondly, we propose a novel framework, named FAS-wrapper, which transfers knowledge from the pre-trained models and seamlessly integrates with different FAS models. Lastly, to help the community further advance MD-FAS, we construct a new benchmark based on SIW, SIW-Mv2 and Oulu-NPU, and introduce four distinct protocols for evaluation, where source and target domains are different in terms of spoof type, age, ethnicity, and illumination. Our proposed method achieves superior performance on the MD-FAS benchmark than previous methods. Our code and newly curated SIW-Mv2 are publicly available.
Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing
Mar 23, 2022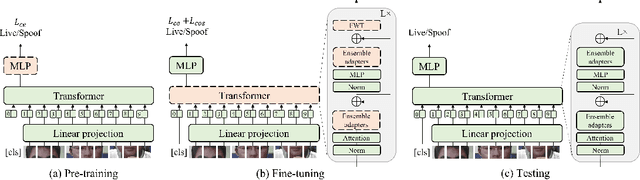
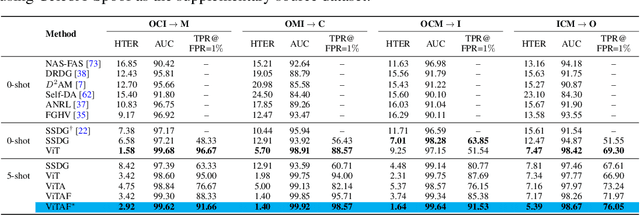
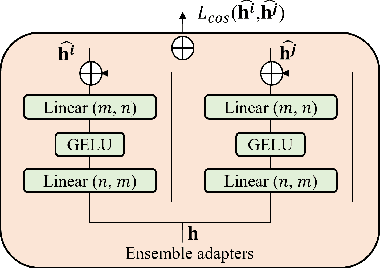
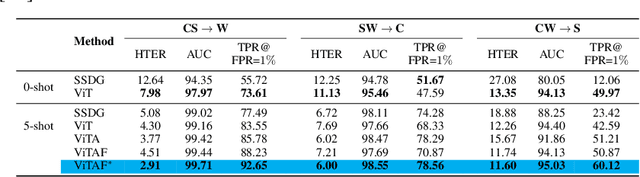
While recent face anti-spoofing methods perform well under the intra-domain setups, an effective approach needs to account for much larger appearance variations of images acquired in complex scenes with different sensors for robust performance. In this paper, we present adaptive vision transformers (ViT) for robust cross-domain face anti-spoofing. Specifically, we adopt ViT as a backbone to exploit its strength to account for long-range dependencies among pixels. We further introduce the ensemble adapters module and feature-wise transformation layers in the ViT to adapt to different domains for robust performance with a few samples. Experiments on several benchmark datasets show that the proposed models achieve both robust and competitive performance against the state-of-the-art methods.
PSCC-Net: Progressive Spatio-Channel Correlation Network for Image Manipulation Detection and Localization
Mar 19, 2021

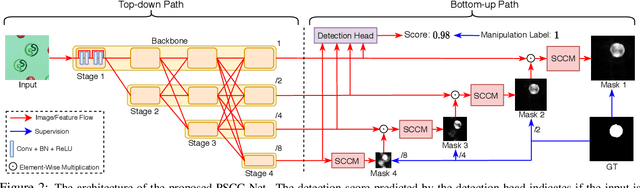
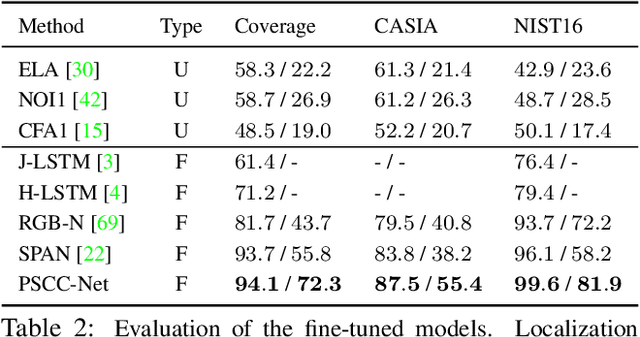
To defend against manipulation of image content, such as splicing, copy-move, and removal, we develop a Progressive Spatio-Channel Correlation Network (PSCC-Net) to detect and localize image manipulations. PSCC-Net processes the image in a two-path procedure: a top-down path that extracts local and global features and a bottom-up path that detects whether the input image is manipulated, and estimates its manipulation masks at 4 scales, where each mask is conditioned on the previous one. Different from the conventional encoder-decoder and no-pooling structures, PSCC-Net leverages features at different scales with dense cross-connections to produce manipulation masks in a coarse-to-fine fashion. Moreover, a Spatio-Channel Correlation Module (SCCM) captures both spatial and channel-wise correlations in the bottom-up path, which endows features with holistic cues, enabling the network to cope with a wide range of manipulation attacks. Thanks to the light-weight backbone and progressive mechanism, PSCC-Net can process 1,080P images at 50+ FPS. Extensive experiments demonstrate the superiority of PSCC-Net over the state-of-the-art methods on both detection and localization.
Physics-Guided Spoof Trace Disentanglement for Generic Face Anti-Spoofing
Dec 09, 2020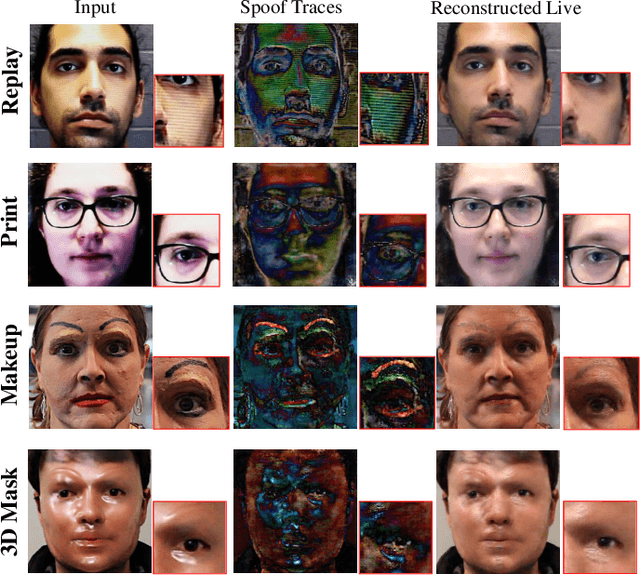
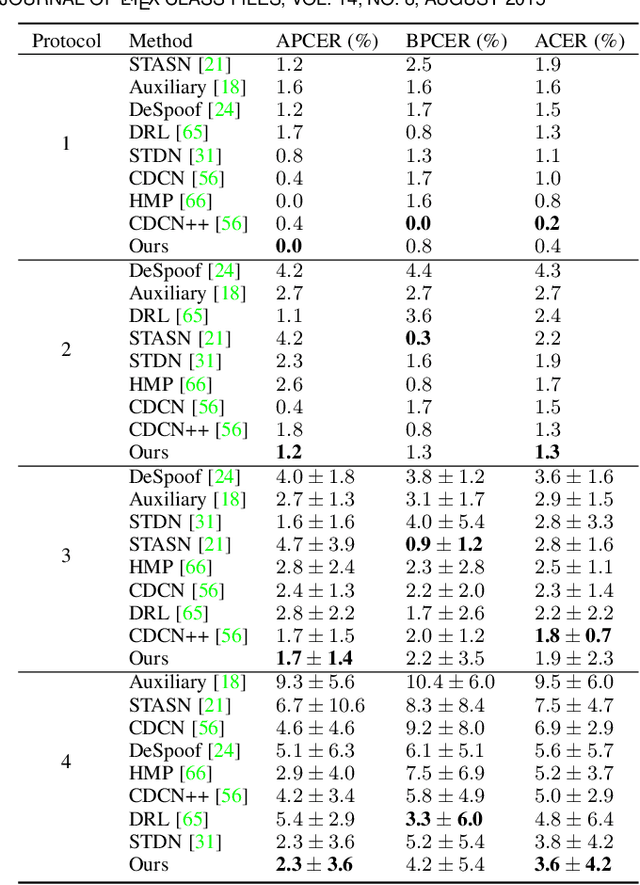
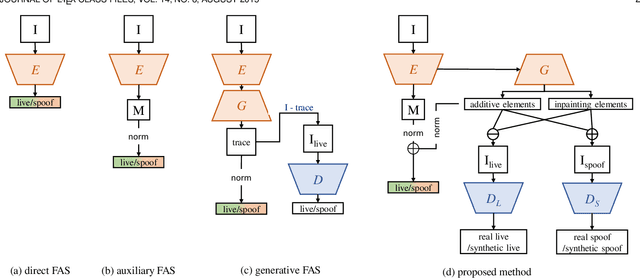
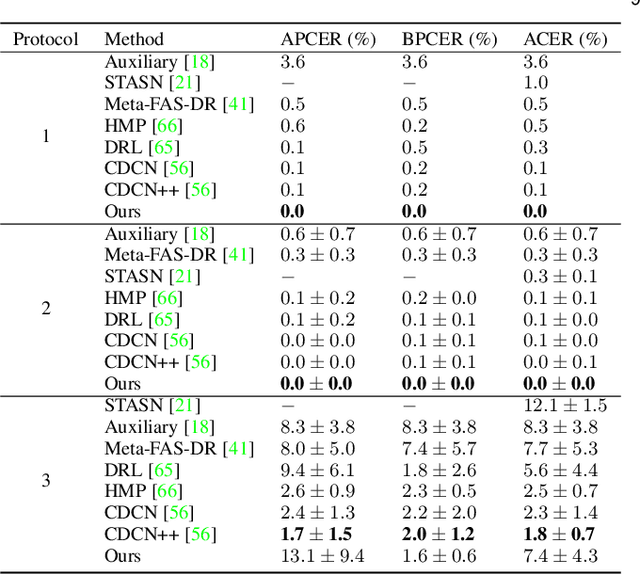
Prior studies show that the key to face anti-spoofing lies in the subtle image pattern, termed "spoof trace", e.g., color distortion, 3D mask edge, Moire pattern, and many others. Designing a generic face anti-spoofing model to estimate those spoof traces can improve not only the generalization of the spoof detection, but also the interpretability of the model's decision. Yet, this is a challenging task due to the diversity of spoof types and the lack of ground truth in spoof traces. In this work, we design a novel adversarial learning framework to disentangle spoof faces into the spoof traces and the live counterparts. Guided by physical properties, the spoof generation is represented as a combination of additive process and inpainting process. Additive process describes spoofing as spoof material introducing extra patterns (e.g., moire pattern), where the live counterpart can be recovered by removing those patterns. Inpainting process describes spoofing as spoof material fully covering certain regions, where the live counterpart of those regions has to be "guessed". We use 3 additive components and 1 inpainting component to represent traces at different frequency bands. The disentangled spoof traces can be utilized to synthesize realistic new spoof faces after proper geometric correction, and the synthesized spoof can be used for training and improve the generalization of spoof detection. Our approach demonstrates superior spoof detection performance on 3 testing scenarios: known attacks, unknown attacks, and open-set attacks. Meanwhile, it provides a visually-convincing estimation of the spoof traces. Source code and pre-trained models will be publicly available upon publication.
On Disentangling Spoof Trace for Generic Face Anti-Spoofing
Jul 17, 2020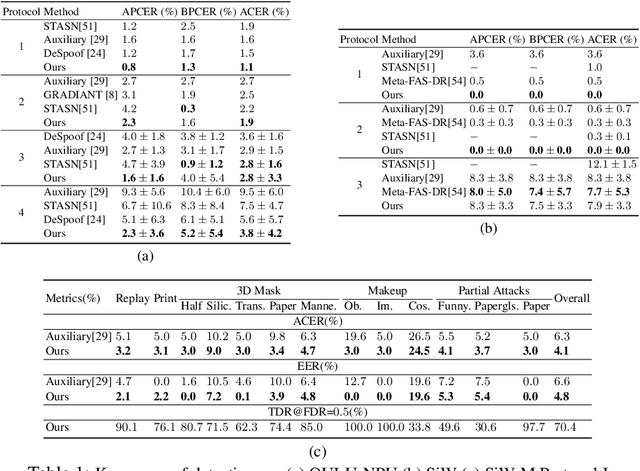
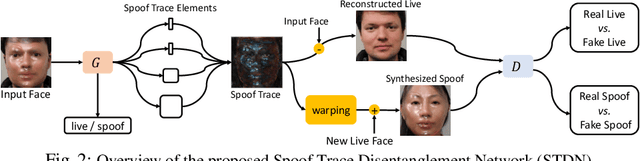
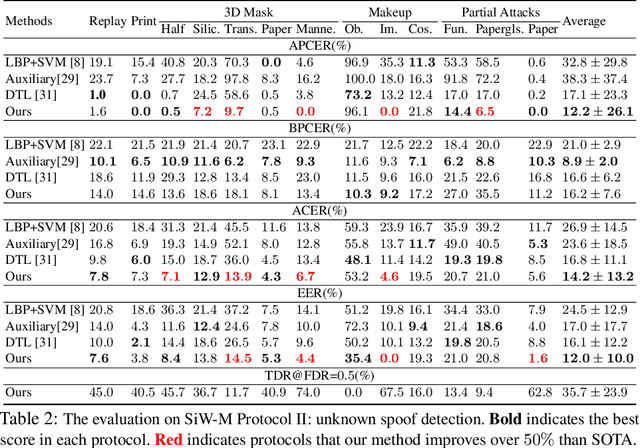
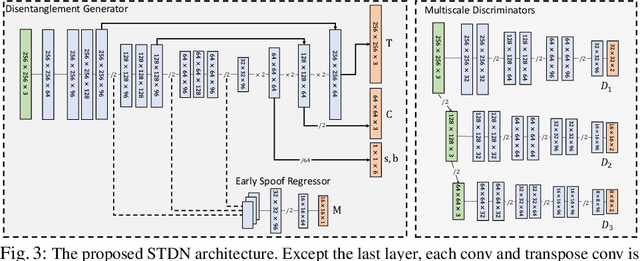
Prior studies show that the key to face anti-spoofing lies in the subtle image pattern, termed "spoof trace", e.g., color distortion, 3D mask edge, Moire pattern, and many others. Designing a generic anti-spoofing model to estimate those spoof traces can improve not only the generalization of the spoof detection, but also the interpretability of the model's decision. Yet, this is a challenging task due to the diversity of spoof types and the lack of ground truth in spoof traces. This work designs a novel adversarial learning framework to disentangle the spoof traces from input faces as a hierarchical combination of patterns at multiple scales. With the disentangled spoof traces, we unveil the live counterpart of the original spoof face, and further synthesize realistic new spoof faces after a proper geometric correction. Our method demonstrates superior spoof detection performance on both seen and unseen spoof scenarios while providing visually convincing estimation of spoof traces. Code is available at https://github.com/yaojieliu/ECCV20-STDN.
Noise Modeling, Synthesis and Classification for Generic Object Anti-Spoofing
Mar 31, 2020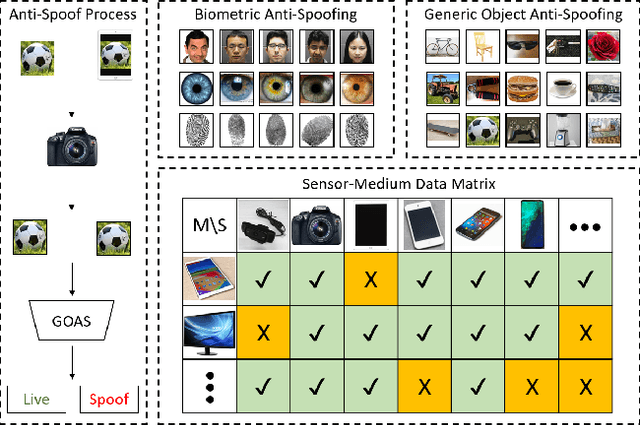
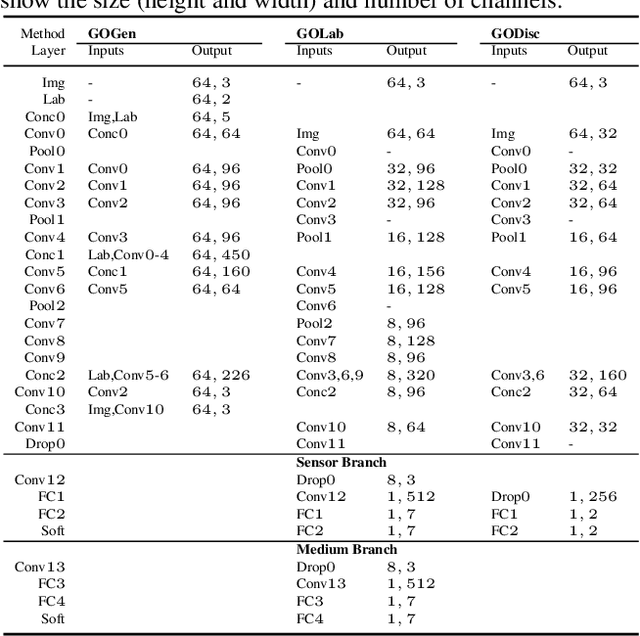
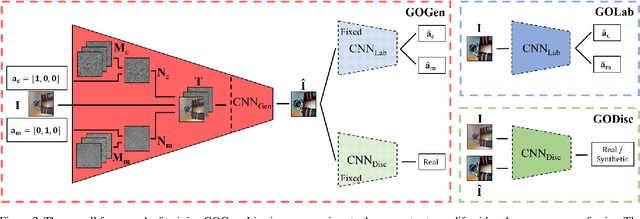
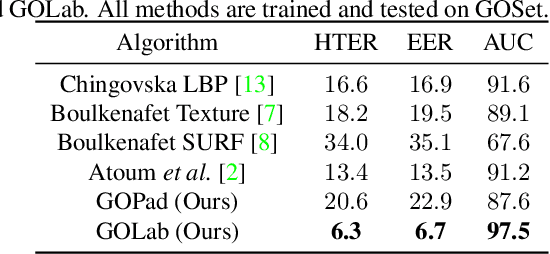
Using printed photograph and replaying videos of biometric modalities, such as iris, fingerprint and face, are common attacks to fool the recognition systems for granting access as the genuine user. With the growing online person-to-person shopping (e.g., Ebay and Craigslist), such attacks also threaten those services, where the online photo illustration might not be captured from real items but from paper or digital screen. Thus, the study of anti-spoofing should be extended from modality-specific solutions to generic-object-based ones. In this work, we define and tackle the problem of Generic Object Anti-Spoofing (GOAS) for the first time. One significant cue to detect these attacks is the noise patterns introduced by the capture sensors and spoof mediums. Different sensor/medium combinations can result in diverse noise patterns. We propose a GAN-based architecture to synthesize and identify the noise patterns from seen and unseen medium/sensor combinations. We show that the procedure of synthesis and identification are mutually beneficial. We further demonstrate the learned GOAS models can directly contribute to modality-specific anti-spoofing without domain transfer. The code and GOSet dataset are available at cvlab.cse.msu.edu/project-goas.html.
Deep Tree Learning for Zero-shot Face Anti-Spoofing
Apr 09, 2019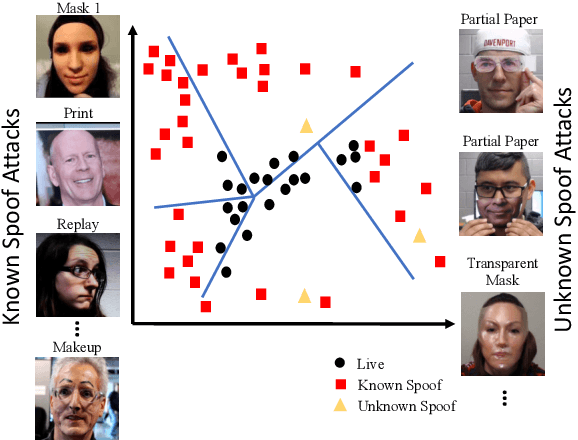
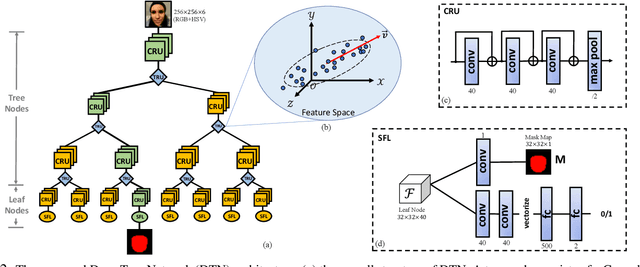
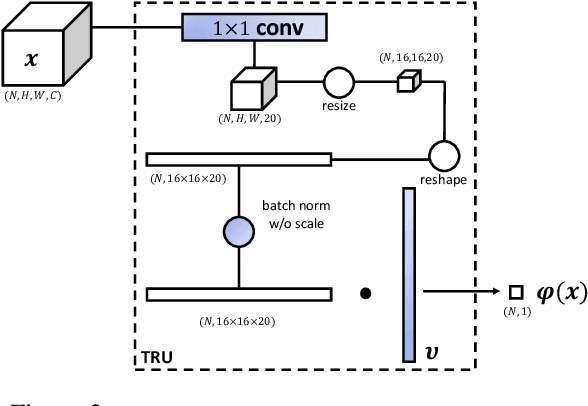
Face anti-spoofing is designed to keep face recognition systems from recognizing fake faces as the genuine users. While advanced face anti-spoofing methods are developed, new types of spoof attacks are also being created and becoming a threat to all existing systems. We define the detection of unknown spoof attacks as Zero-Shot Face Anti-spoofing (ZSFA). Previous works of ZSFA only study 1-2 types of spoof attacks, such as print/replay attacks, which limits the insight of this problem. In this work, we expand the ZSFA problem to a wide range of 13 types of spoof attacks, including print attack, replay attack, 3D mask attacks, and so on. A novel Deep Tree Network (DTN) is proposed to tackle the ZSFA. The tree is learned to partition the spoof samples into semantic sub-groups in an unsupervised fashion. When a data sample arrives, being know or unknown attacks, DTN routes it to the most similar spoof cluster, and make the binary decision. In addition, to enable the study of ZSFA, we introduce the first face anti-spoofing database that contains diverse types of spoof attacks. Experiments show that our proposed method achieves the state of the art on multiple testing protocols of ZSFA.
Face De-Spoofing: Anti-Spoofing via Noise Modeling
Jul 26, 2018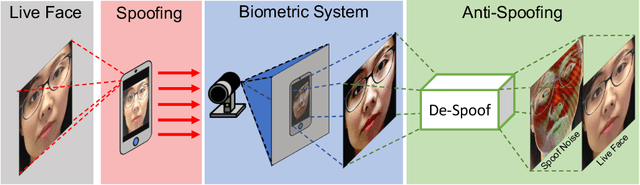
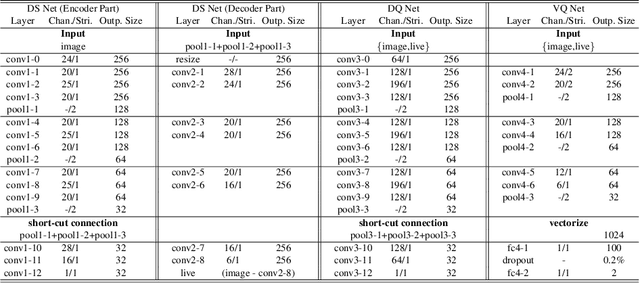
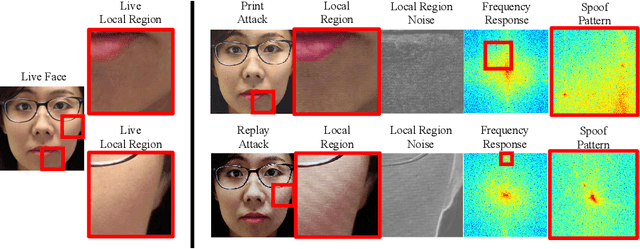
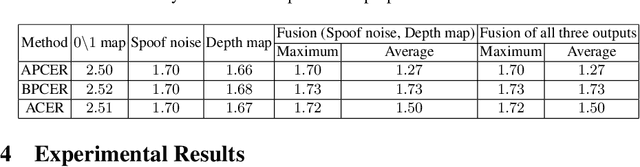
Many prior face anti-spoofing works develop discriminative models for recognizing the subtle differences between live and spoof faces. Those approaches often regard the image as an indivisible unit, and process it holistically, without explicit modeling of the spoofing process. In this work, motivated by the noise modeling and denoising algorithms, we identify a new problem of face de-spoofing, for the purpose of anti-spoofing: inversely decomposing a spoof face into a spoof noise and a live face, and then utilizing the spoof noise for classification. A CNN architecture with proper constraints and supervisions is proposed to overcome the problem of having no ground truth for the decomposition. We evaluate the proposed method on multiple face anti-spoofing databases. The results show promising improvements due to our spoof noise modeling. Moreover, the estimated spoof noise provides a visualization which helps to understand the added spoof noise by each spoof medium.