 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024

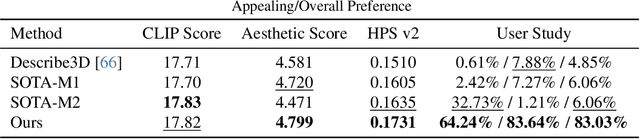
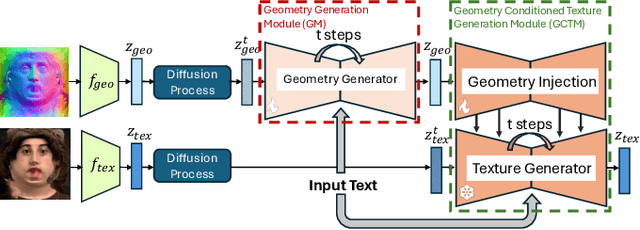
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Robust Egocentric Photo-realistic Facial Expression Transfer for Virtual Reality
Apr 10, 2021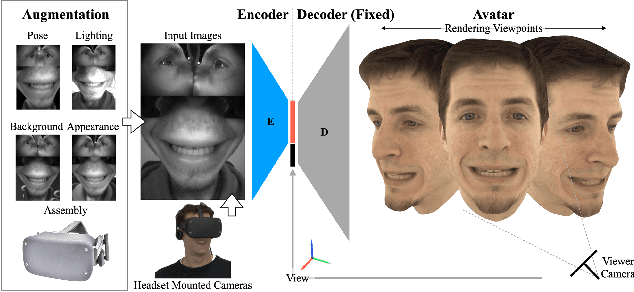
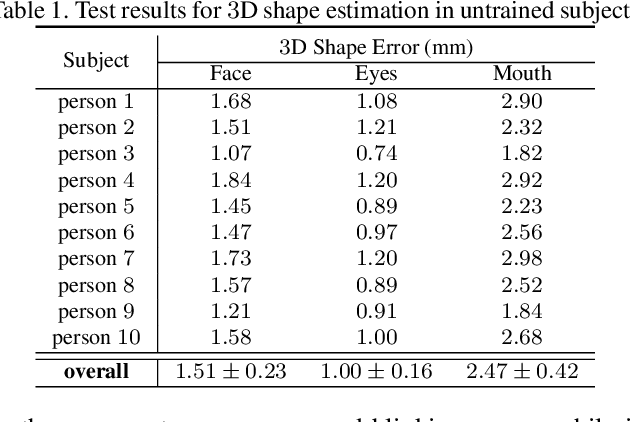

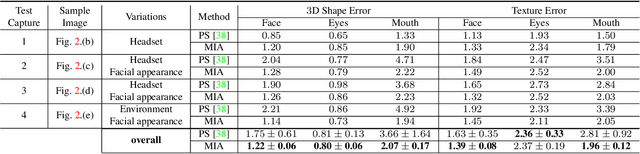
Social presence, the feeling of being there with a real person, will fuel the next generation of communication systems driven by digital humans in virtual reality (VR). The best 3D video-realistic VR avatars that minimize the uncanny effect rely on person-specific (PS) models. However, these PS models are time-consuming to build and are typically trained with limited data variability, which results in poor generalization and robustness. Major sources of variability that affects the accuracy of facial expression transfer algorithms include using different VR headsets (e.g., camera configuration, slop of the headset), facial appearance changes over time (e.g., beard, make-up), and environmental factors (e.g., lighting, backgrounds). This is a major drawback for the scalability of these models in VR. This paper makes progress in overcoming these limitations by proposing an end-to-end multi-identity architecture (MIA) trained with specialized augmentation strategies. MIA drives the shape component of the avatar from three cameras in the VR headset (two eyes, one mouth), in untrained subjects, using minimal personalized information (i.e., neutral 3D mesh shape). Similarly, if the PS texture decoder is available, MIA is able to drive the full avatar (shape+texture) robustly outperforming PS models in challenging scenarios. Our key contribution to improve robustness and generalization, is that our method implicitly decouples, in an unsupervised manner, the facial expression from nuisance factors (e.g., headset, environment, facial appearance). We demonstrate the superior performance and robustness of the proposed method versus state-of-the-art PS approaches in a variety of experiments.
Noise Modeling, Synthesis and Classification for Generic Object Anti-Spoofing
Mar 31, 2020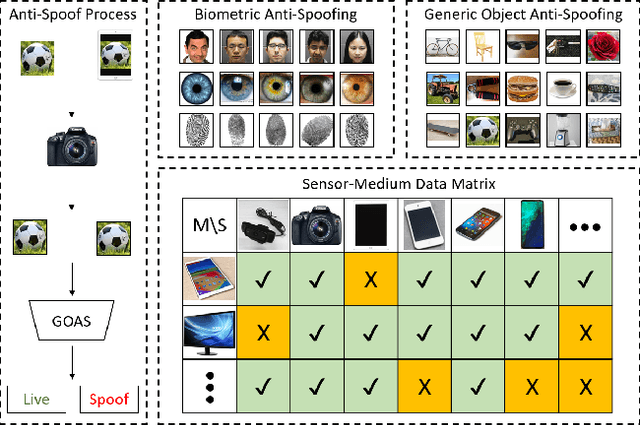
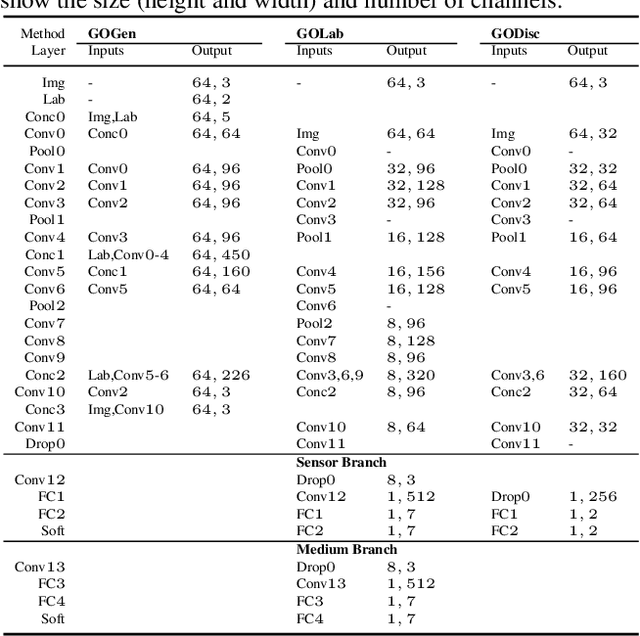
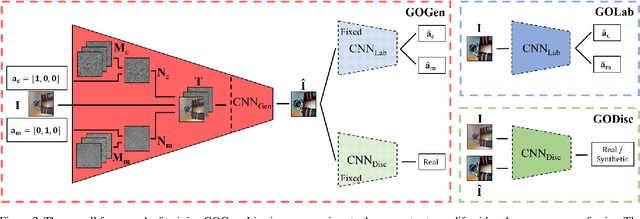
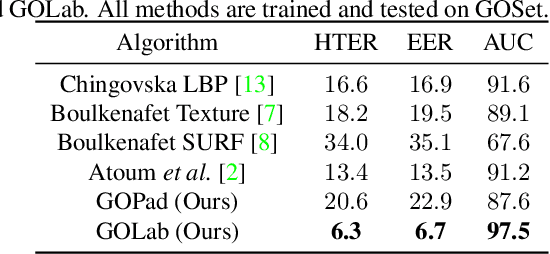
Using printed photograph and replaying videos of biometric modalities, such as iris, fingerprint and face, are common attacks to fool the recognition systems for granting access as the genuine user. With the growing online person-to-person shopping (e.g., Ebay and Craigslist), such attacks also threaten those services, where the online photo illustration might not be captured from real items but from paper or digital screen. Thus, the study of anti-spoofing should be extended from modality-specific solutions to generic-object-based ones. In this work, we define and tackle the problem of Generic Object Anti-Spoofing (GOAS) for the first time. One significant cue to detect these attacks is the noise patterns introduced by the capture sensors and spoof mediums. Different sensor/medium combinations can result in diverse noise patterns. We propose a GAN-based architecture to synthesize and identify the noise patterns from seen and unseen medium/sensor combinations. We show that the procedure of synthesis and identification are mutually beneficial. We further demonstrate the learned GOAS models can directly contribute to modality-specific anti-spoofing without domain transfer. The code and GOSet dataset are available at cvlab.cse.msu.edu/project-goas.html.
Deep Tree Learning for Zero-shot Face Anti-Spoofing
Apr 09, 2019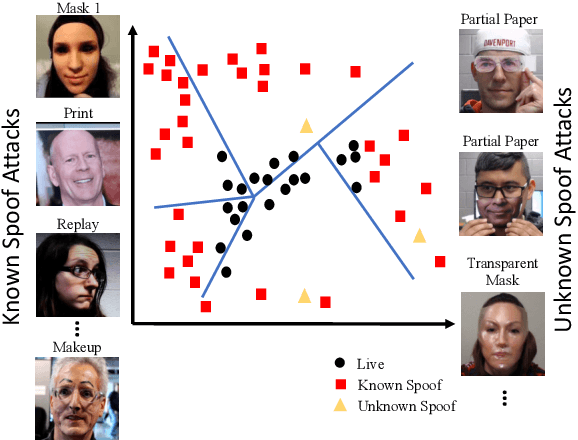
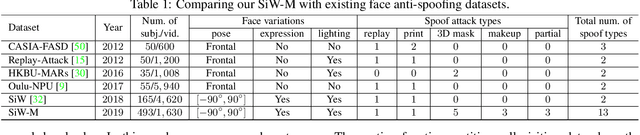
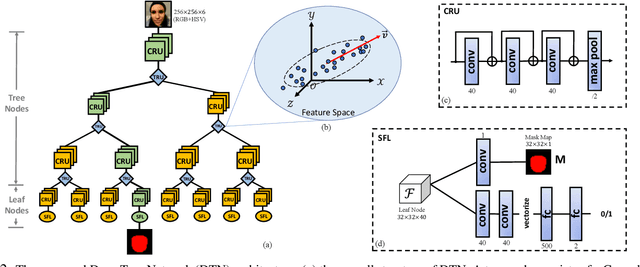
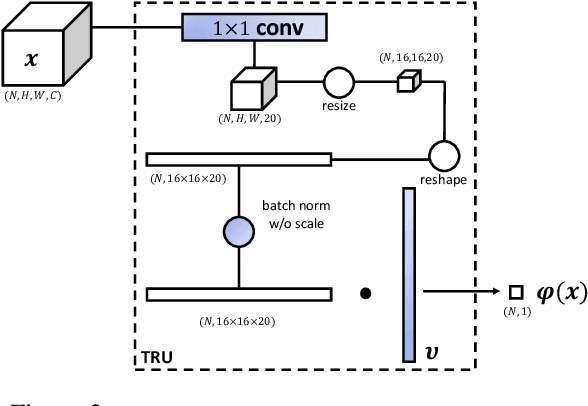
Face anti-spoofing is designed to keep face recognition systems from recognizing fake faces as the genuine users. While advanced face anti-spoofing methods are developed, new types of spoof attacks are also being created and becoming a threat to all existing systems. We define the detection of unknown spoof attacks as Zero-Shot Face Anti-spoofing (ZSFA). Previous works of ZSFA only study 1-2 types of spoof attacks, such as print/replay attacks, which limits the insight of this problem. In this work, we expand the ZSFA problem to a wide range of 13 types of spoof attacks, including print attack, replay attack, 3D mask attacks, and so on. A novel Deep Tree Network (DTN) is proposed to tackle the ZSFA. The tree is learned to partition the spoof samples into semantic sub-groups in an unsupervised fashion. When a data sample arrives, being know or unknown attacks, DTN routes it to the most similar spoof cluster, and make the binary decision. In addition, to enable the study of ZSFA, we introduce the first face anti-spoofing database that contains diverse types of spoof attacks. Experiments show that our proposed method achieves the state of the art on multiple testing protocols of ZSFA.
Face De-Spoofing: Anti-Spoofing via Noise Modeling
Jul 26, 2018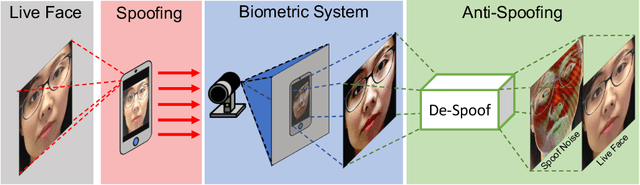
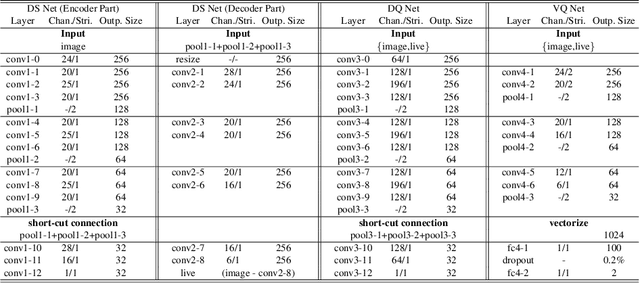
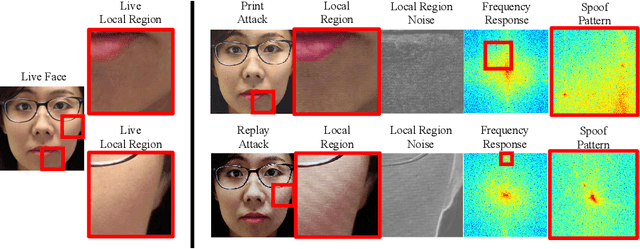
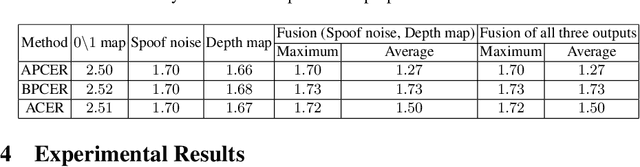
Many prior face anti-spoofing works develop discriminative models for recognizing the subtle differences between live and spoof faces. Those approaches often regard the image as an indivisible unit, and process it holistically, without explicit modeling of the spoofing process. In this work, motivated by the noise modeling and denoising algorithms, we identify a new problem of face de-spoofing, for the purpose of anti-spoofing: inversely decomposing a spoof face into a spoof noise and a live face, and then utilizing the spoof noise for classification. A CNN architecture with proper constraints and supervisions is proposed to overcome the problem of having no ground truth for the decomposition. We evaluate the proposed method on multiple face anti-spoofing databases. The results show promising improvements due to our spoof noise modeling. Moreover, the estimated spoof noise provides a visualization which helps to understand the added spoof noise by each spoof medium.
Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision
Mar 29, 2018
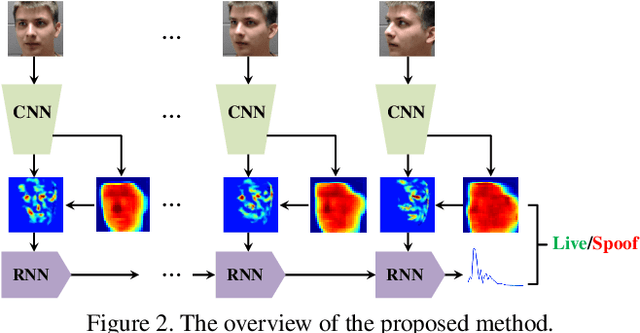
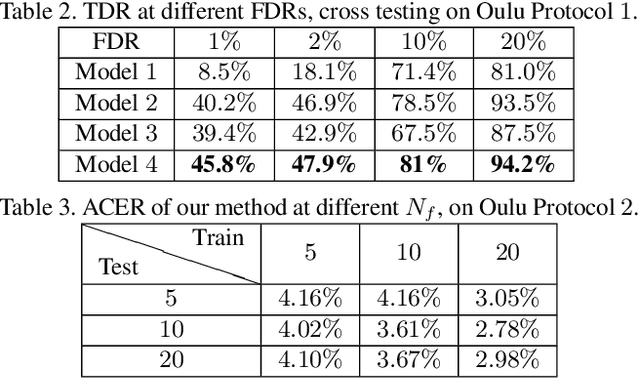
Face anti-spoofing is the crucial step to prevent face recognition systems from a security breach. Previous deep learning approaches formulate face anti-spoofing as a binary classification problem. Many of them struggle to grasp adequate spoofing cues and generalize poorly. In this paper, we argue the importance of auxiliary supervision to guide the learning toward discriminative and generalizable cues. A CNN-RNN model is learned to estimate the face depth with pixel-wise supervision, and to estimate rPPG signals with sequence-wise supervision. Then we fuse the estimated depth and rPPG to distinguish live vs. spoof faces. In addition, we introduce a new face anti-spoofing database that covers a large range of illumination, subject, and pose variations. Experimental results show that our model achieves the state-of-the-art performance on both intra-database and cross-database testing.
Do Convolutional Neural Networks Learn Class Hierarchy?
Oct 17, 2017



Convolutional Neural Networks (CNNs) currently achieve state-of-the-art accuracy in image classification. With a growing number of classes, the accuracy usually drops as the possibilities of confusion increase. Interestingly, the class confusion patterns follow a hierarchical structure over the classes. We present visual-analytics methods to reveal and analyze this hierarchy of similar classes in relation with CNN-internal data. We found that this hierarchy not only dictates the confusion patterns between the classes, it furthermore dictates the learning behavior of CNNs. In particular, the early layers in these networks develop feature detectors that can separate high-level groups of classes quite well, even after a few training epochs. In contrast, the latter layers require substantially more epochs to develop specialized feature detectors that can separate individual classes. We demonstrate how these insights are key to significant improvement in accuracy by designing hierarchy-aware CNNs that accelerate model convergence and alleviate overfitting. We further demonstrate how our methods help in identifying various quality issues in the training data.
* Video demo at https://vimeo.com/228263798
Dense Face Alignment
Sep 05, 2017
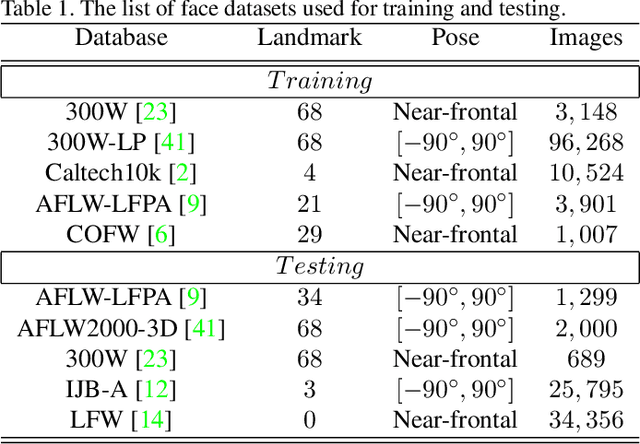
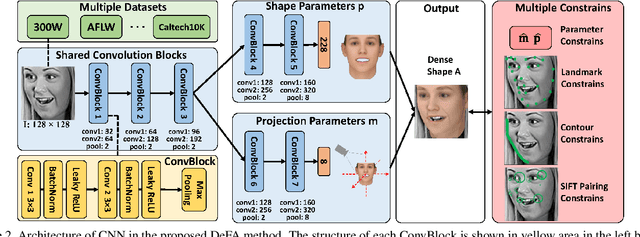

Face alignment is a classic problem in the computer vision field. Previous works mostly focus on sparse alignment with a limited number of facial landmark points, i.e., facial landmark detection. In this paper, for the first time, we aim at providing a very dense 3D alignment for large-pose face images. To achieve this, we train a CNN to estimate the 3D face shape, which not only aligns limited facial landmarks but also fits face contours and SIFT feature points. Moreover, we also address the bottleneck of training CNN with multiple datasets, due to different landmark markups on different datasets, such as 5, 34, 68. Experimental results show our method not only provides high-quality, dense 3D face fitting but also outperforms the state-of-the-art facial landmark detection methods on the challenging datasets. Our model can run at real time during testing.
Pose-Invariant Face Alignment with a Single CNN
Jul 19, 2017


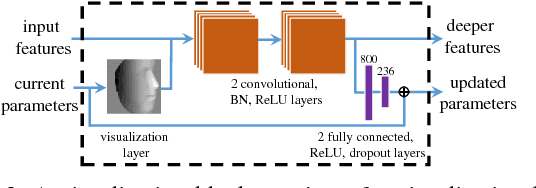
Face alignment has witnessed substantial progress in the last decade. One of the recent focuses has been aligning a dense 3D face shape to face images with large head poses. The dominant technology used is based on the cascade of regressors, e.g., CNN, which has shown promising results. Nonetheless, the cascade of CNNs suffers from several drawbacks, e.g., lack of end-to-end training, hand-crafted features and slow training speed. To address these issues, we propose a new layer, named visualization layer, that can be integrated into the CNN architecture and enables joint optimization with different loss functions. Extensive evaluation of the proposed method on multiple datasets demonstrates state-of-the-art accuracy, while reducing the training time by more than half compared to the typical cascade of CNNs. In addition, we compare multiple CNN architectures with the visualization layer to further demonstrate the advantage of its utilization.
Pose-Invariant 3D Face Alignment
Jun 11, 2015

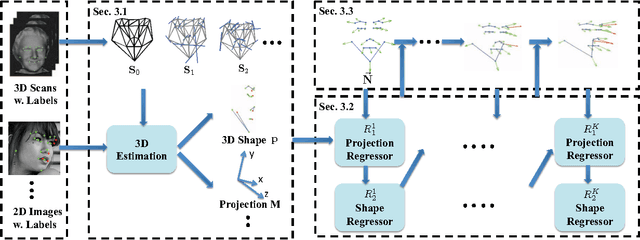

Face alignment aims to estimate the locations of a set of landmarks for a given image. This problem has received much attention as evidenced by the recent advancement in both the methodology and performance. However, most of the existing works neither explicitly handle face images with arbitrary poses, nor perform large-scale experiments on non-frontal and profile face images. In order to address these limitations, this paper proposes a novel face alignment algorithm that estimates both 2D and 3D landmarks and their 2D visibilities for a face image with an arbitrary pose. By integrating a 3D deformable model, a cascaded coupled-regressor approach is designed to estimate both the camera projection matrix and the 3D landmarks. Furthermore, the 3D model also allows us to automatically estimate the 2D landmark visibilities via surface normals. We gather a substantially larger collection of all-pose face images to evaluate our algorithm and demonstrate superior performances than the state-of-the-art methods.