 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace De-Spoofing: Anti-Spoofing via Noise Modeling
Paper and Code
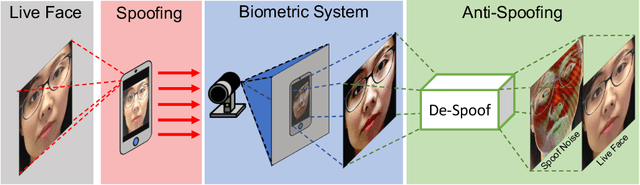
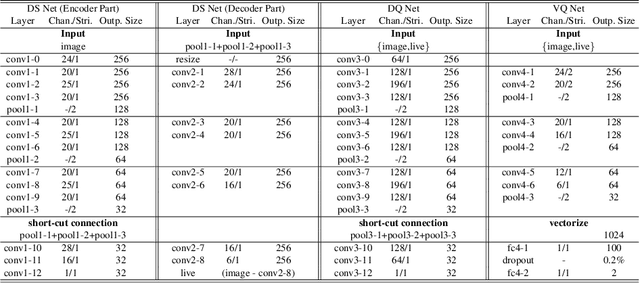
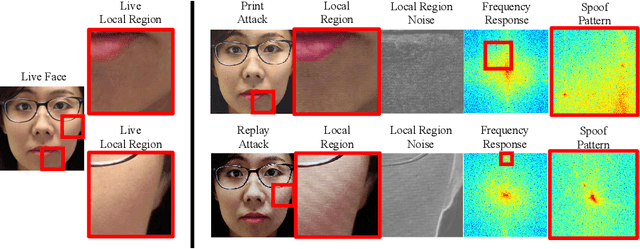
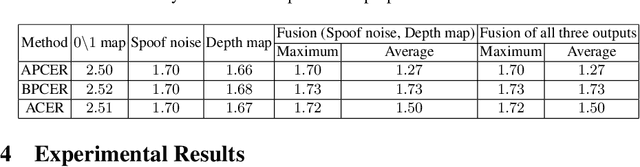
Many prior face anti-spoofing works develop discriminative models for recognizing the subtle differences between live and spoof faces. Those approaches often regard the image as an indivisible unit, and process it holistically, without explicit modeling of the spoofing process. In this work, motivated by the noise modeling and denoising algorithms, we identify a new problem of face de-spoofing, for the purpose of anti-spoofing: inversely decomposing a spoof face into a spoof noise and a live face, and then utilizing the spoof noise for classification. A CNN architecture with proper constraints and supervisions is proposed to overcome the problem of having no ground truth for the decomposition. We evaluate the proposed method on multiple face anti-spoofing databases. The results show promising improvements due to our spoof noise modeling. Moreover, the estimated spoof noise provides a visualization which helps to understand the added spoof noise by each spoof medium.