 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Transformer-Based Novel View Synthesis Models with Token Disentanglement and Synthetic Data
Sep 08, 2025Large transformer-based models have made significant progress in generalizable novel view synthesis (NVS) from sparse input views, generating novel viewpoints without the need for test-time optimization. However, these models are constrained by the limited diversity of publicly available scene datasets, making most real-world (in-the-wild) scenes out-of-distribution. To overcome this, we incorporate synthetic training data generated from diffusion models, which improves generalization across unseen domains. While synthetic data offers scalability, we identify artifacts introduced during data generation as a key bottleneck affecting reconstruction quality. To address this, we propose a token disentanglement process within the transformer architecture, enhancing feature separation and ensuring more effective learning. This refinement not only improves reconstruction quality over standard transformers but also enables scalable training with synthetic data. As a result, our method outperforms existing models on both in-dataset and cross-dataset evaluations, achieving state-of-the-art results across multiple benchmarks while significantly reducing computational costs. Project page: https://scaling3dnvs.github.io/
SplatVoxel: History-Aware Novel View Streaming without Temporal Training
Mar 18, 2025We study the problem of novel view streaming from sparse-view videos, which aims to generate a continuous sequence of high-quality, temporally consistent novel views as new input frames arrive. However, existing novel view synthesis methods struggle with temporal coherence and visual fidelity, leading to flickering and inconsistency. To address these challenges, we introduce history-awareness, leveraging previous frames to reconstruct the scene and improve quality and stability. We propose a hybrid splat-voxel feed-forward scene reconstruction approach that combines Gaussian Splatting to propagate information over time, with a hierarchical voxel grid for temporal fusion. Gaussian primitives are efficiently warped over time using a motion graph that extends 2D tracking models to 3D motion, while a sparse voxel transformer integrates new temporal observations in an error-aware manner. Crucially, our method does not require training on multi-view video datasets, which are currently limited in size and diversity, and can be directly applied to sparse-view video streams in a history-aware manner at inference time. Our approach achieves state-of-the-art performance in both static and streaming scene reconstruction, effectively reducing temporal artifacts and visual artifacts while running at interactive rates (15 fps with 350ms delay) on a single H100 GPU. Project Page: https://19reborn.github.io/SplatVoxel/
Quark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
Text2Immersion: Generative Immersive Scene with 3D Gaussians
Dec 14, 2023



We introduce Text2Immersion, an elegant method for producing high-quality 3D immersive scenes from text prompts. Our proposed pipeline initiates by progressively generating a Gaussian cloud using pre-trained 2D diffusion and depth estimation models. This is followed by a refining stage on the Gaussian cloud, interpolating and refining it to enhance the details of the generated scene. Distinct from prevalent methods that focus on single object or indoor scenes, or employ zoom-out trajectories, our approach generates diverse scenes with various objects, even extending to the creation of imaginary scenes. Consequently, Text2Immersion can have wide-ranging implications for various applications such as virtual reality, game development, and automated content creation. Extensive evaluations demonstrate that our system surpasses other methods in rendering quality and diversity, further progressing towards text-driven 3D scene generation. We will make the source code publicly accessible at the project page.
AlteredAvatar: Stylizing Dynamic 3D Avatars with Fast Style Adaptation
May 30, 2023This paper presents a method that can quickly adapt dynamic 3D avatars to arbitrary text descriptions of novel styles. Among existing approaches for avatar stylization, direct optimization methods can produce excellent results for arbitrary styles but they are unpleasantly slow. Furthermore, they require redoing the optimization process from scratch for every new input. Fast approximation methods using feed-forward networks trained on a large dataset of style images can generate results for new inputs quickly, but tend not to generalize well to novel styles and fall short in quality. We therefore investigate a new approach, AlteredAvatar, that combines those two approaches using the meta-learning framework. In the inner loop, the model learns to optimize to match a single target style well; while in the outer loop, the model learns to stylize efficiently across many styles. After training, AlteredAvatar learns an initialization that can quickly adapt within a small number of update steps to a novel style, which can be given using texts, a reference image, or a combination of both. We show that AlteredAvatar can achieve a good balance between speed, flexibility and quality, while maintaining consistency across a wide range of novel views and facial expressions.
MEGANE: Morphable Eyeglass and Avatar Network
Feb 09, 2023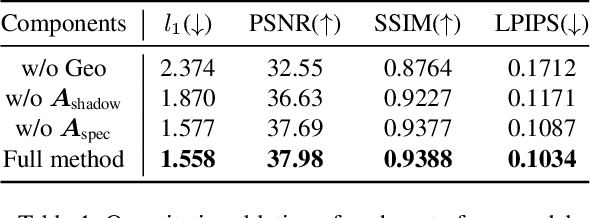
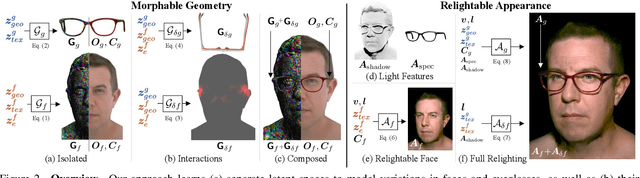
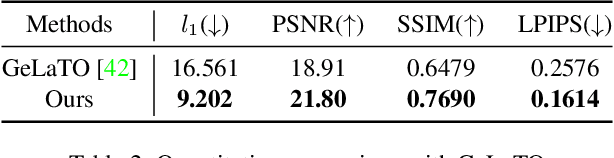

Eyeglasses play an important role in the perception of identity. Authentic virtual representations of faces can benefit greatly from their inclusion. However, modeling the geometric and appearance interactions of glasses and the face of virtual representations of humans is challenging. Glasses and faces affect each other's geometry at their contact points, and also induce appearance changes due to light transport. Most existing approaches do not capture these physical interactions since they model eyeglasses and faces independently. Others attempt to resolve interactions as a 2D image synthesis problem and suffer from view and temporal inconsistencies. In this work, we propose a 3D compositional morphable model of eyeglasses that accurately incorporates high-fidelity geometric and photometric interaction effects. To support the large variation in eyeglass topology efficiently, we employ a hybrid representation that combines surface geometry and a volumetric representation. Unlike volumetric approaches, our model naturally retains correspondences across glasses, and hence explicit modification of geometry, such as lens insertion and frame deformation, is greatly simplified. In addition, our model is relightable under point lights and natural illumination, supporting high-fidelity rendering of various frame materials, including translucent plastic and metal within a single morphable model. Importantly, our approach models global light transport effects, such as casting shadows between faces and glasses. Our morphable model for eyeglasses can also be fit to novel glasses via inverse rendering. We compare our approach to state-of-the-art methods and demonstrate significant quality improvements.
RelightableHands: Efficient Neural Relighting of Articulated Hand Models
Feb 09, 2023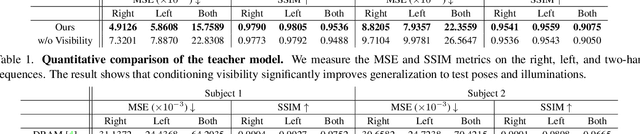
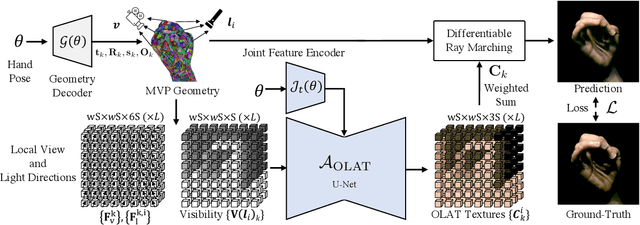

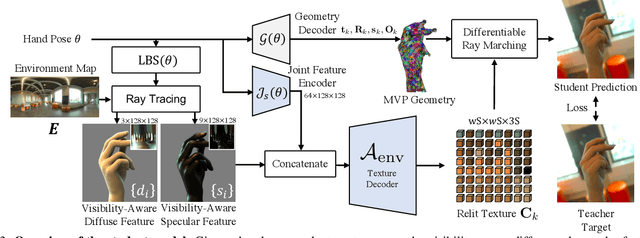
We present the first neural relighting approach for rendering high-fidelity personalized hands that can be animated in real-time under novel illumination. Our approach adopts a teacher-student framework, where the teacher learns appearance under a single point light from images captured in a light-stage, allowing us to synthesize hands in arbitrary illuminations but with heavy compute. Using images rendered by the teacher model as training data, an efficient student model directly predicts appearance under natural illuminations in real-time. To achieve generalization, we condition the student model with physics-inspired illumination features such as visibility, diffuse shading, and specular reflections computed on a coarse proxy geometry, maintaining a small computational overhead. Our key insight is that these features have strong correlation with subsequent global light transport effects, which proves sufficient as conditioning data for the neural relighting network. Moreover, in contrast to bottleneck illumination conditioning, these features are spatially aligned based on underlying geometry, leading to better generalization to unseen illuminations and poses. In our experiments, we demonstrate the efficacy of our illumination feature representations, outperforming baseline approaches. We also show that our approach can photorealistically relight two interacting hands at real-time speeds. https://sh8.io/#/relightable_hands
NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation
Dec 08, 2022



The capture and animation of human hair are two of the major challenges in the creation of realistic avatars for the virtual reality. Both problems are highly challenging, because hair has complex geometry and appearance, as well as exhibits challenging motion. In this paper, we present a two-stage approach that models hair independently from the head to address these challenges in a data-driven manner. The first stage, state compression, learns a low-dimensional latent space of 3D hair states containing motion and appearance, via a novel autoencoder-as-a-tracker strategy. To better disentangle the hair and head in appearance learning, we employ multi-view hair segmentation masks in combination with a differentiable volumetric renderer. The second stage learns a novel hair dynamics model that performs temporal hair transfer based on the discovered latent codes. To enforce higher stability while driving our dynamics model, we employ the 3D point-cloud autoencoder from the compression stage for de-noising of the hair state. Our model outperforms the state of the art in novel view synthesis and is capable of creating novel hair animations without having to rely on hair observations as a driving signal. Project page is here https://ziyanw1.github.io/neuwigs/.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
HVH: Learning a Hybrid Neural Volumetric Representation for Dynamic Hair Performance Capture
Dec 19, 2021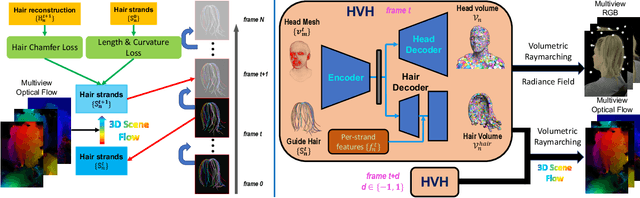

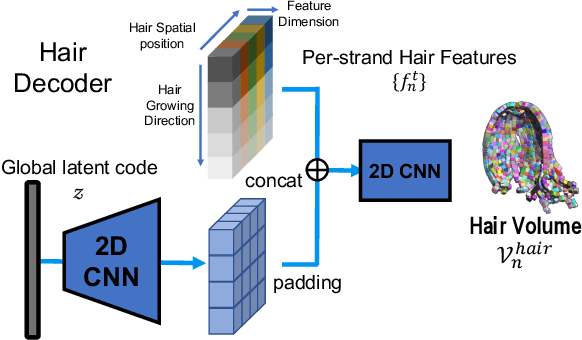
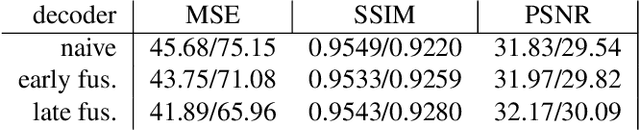
Capturing and rendering life-like hair is particularly challenging due to its fine geometric structure, the complex physical interaction and its non-trivial visual appearance.Yet, hair is a critical component for believable avatars. In this paper, we address the aforementioned problems: 1) we use a novel, volumetric hair representation that is com-posed of thousands of primitives. Each primitive can be rendered efficiently, yet realistically, by building on the latest advances in neural rendering. 2) To have a reliable control signal, we present a novel way of tracking hair on the strand level. To keep the computational effort manageable, we use guide hairs and classic techniques to expand those into a dense hood of hair. 3) To better enforce temporal consistency and generalization ability of our model, we further optimize the 3D scene flow of our representation with multi-view optical flow, using volumetric ray marching. Our method can not only create realistic renders of recorded multi-view sequences, but also create renderings for new hair configurations by providing new control signals. We compare our method with existing work on viewpoint synthesis and drivable animation and achieve state-of-the-art results. Please check out our project website at https://ziyanw1.github.io/hvh/.