 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWispy to Voluminous: Prior-free Multi-view Capture of Strand-level Facial Hair
Jun 06, 2026Facial hair is a defining trait of personal identity, yet remains a critical bottleneck for digital avatars. Recent volumetric methods achieve photorealism but bake hair into the underlying face geometry, preventing editability and failing to resolve sparse, strand-like structures. Meanwhile, scalp-hair reconstruction methods target dense hair volumes and do not transfer to the sparse, spatially-varying nature of facial hair. We present a pipeline that automatically reconstructs facial hair -- beard, mustache, lashes, and brows -- from multi-view images, converting an unstructured 3D Gaussian representation into an explicit curve-based strand representation. We resolve geometric ambiguities in four stages: (i) optimizing 3D Gaussians constrained by tracked head geometry to enforce early ray termination and suppress sub-surface noise; (ii) tracing continuous strands robust to frequent crossings and extreme curvature; (iii) grounding strands to the surface and resolving root-tip ambiguity via a physically-motivated prior; and (iv) refining the reconstruction through opacity-driven density control under photometric optimization. To our knowledge, this is the first method to reconstruct high-fidelity facial hair strands from a 3D Gaussian representation. The recovered strands faithfully preserve the orientation and sparsity patterns characteristic of facial hair, and yield assets immediately suitable for downstream production tasks, including facial animation and physical simulation, geometric grooming and transfer, appearance editing, and physics-based rendering.
Snapshot Polarimetric Display Inverse Rendering
May 24, 2026Inverse rendering remains a core challenge in graphics and vision, especially in the snapshot configurations required for lightweight desktop workflows, where the per-frame information budget is highly constrained. Previous inverse rendering work explores various available dimensions for enriching the per-shot information, including temporal modulation, spectral encoding, and polarization. In this work, we introduce polarimetric display inverse rendering, using an LCD to project a linearly polarized RGB binary pattern and an RGB polarization camera augmented with a quarter-wave plate to acquire spectro-polarimetric measurements in a single shot. A feed-forward transformer maps these measurements to per-pixel normal, albedo, roughness, and metallicity. To overcome training data scarcity, we expand a limited set of measured polarimetric bidirectional reflectance distribution functions via a generative manifold. Evaluations on a real desktop setup demonstrate accurate inverse rendering across diverse scenes, outperforming existing approaches.
GeoRelight: Learning Joint Geometrical Relighting and Reconstruction with Flexible Multi-Modal Diffusion Transformers
Apr 22, 2026Relighting a person from a single photo is an attractive but ill-posed task, as a 2D image ambiguously entangles 3D geometry, intrinsic appearance, and illumination. Current methods either use sequential pipelines that suffer from error accumulation, or they do not explicitly leverage 3D geometry during relighting, which limits physical consistency. Since relighting and estimation of 3D geometry are mutually beneficial tasks, we propose a unified Multi-Modal Diffusion Transformer (DiT) that jointly solves for both: GeoRelight. We make this possible through two key technical contributions: isotropic NDC-Orthographic Depth (iNOD), a distortion-free 3D representation compatible with latent diffusion models; and a strategic mixed-data training method that combines synthetic and auto-labeled real data. By solving geometry and relighting jointly, GeoRelight achieves better performance than both sequential models and previous systems that ignored geometry.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
CamLit: Unified Video Diffusion with Explicit Camera and Lighting Control
Mar 15, 2026We present CamLit, the first unified video diffusion model that jointly performs novel view synthesis (NVS) and relighting from a single input image. Given one reference image, a user-defined camera trajectory, and an environment map, CamLit synthesizes a video of the scene from new viewpoints under the specified illumination. Within a single generative process, our model produces temporally coherent and spatially aligned outputs, including relit novel-view frames and corresponding albedo frames, enabling high-quality control of both camera pose and lighting. Qualitative and quantitative experiments demonstrate that CamLit achieves high-fidelity outputs on par with state-of-the-art methods in both novel view synthesis and relighting, without sacrificing visual quality in either task. We show that a single generative model can effectively integrate camera and lighting control, simplifying the video generation pipeline while maintaining competitive performance and consistent realism.
Event-based Photometric Stereo via Rotating Illumination and Per-Pixel Learning
Mar 11, 2026Photometric stereo is a technique for estimating surface normals using images captured under varying illumination. However, conventional frame-based photometric stereo methods are limited in real-world applications due to their reliance on controlled lighting, and susceptibility to ambient illumination. To address these limitations, we propose an event-based photometric stereo system that leverages an event camera, which is effective in scenarios with continuously varying scene radiance and high dynamic range conditions. Our setup employs a single light source moving along a predefined circular trajectory, eliminating the need for multiple synchronized light sources and enabling a more compact and scalable design. We further introduce a lightweight per-pixel multi-layer neural network that directly predicts surface normals from event signals generated by intensity changes as the light source rotates, without system calibration. Experimental results on benchmark datasets and real-world data collected with our data acquisition system demonstrate the effectiveness of our method, achieving a 7.12\% reduction in mean angular error compared to existing event-based photometric stereo methods. In addition, our method demonstrates robustness in regions with sparse event activity, strong ambient illumination, and scenes affected by specularities.
Decoupled Generative Modeling for Human-Object Interaction Synthesis
Dec 22, 2025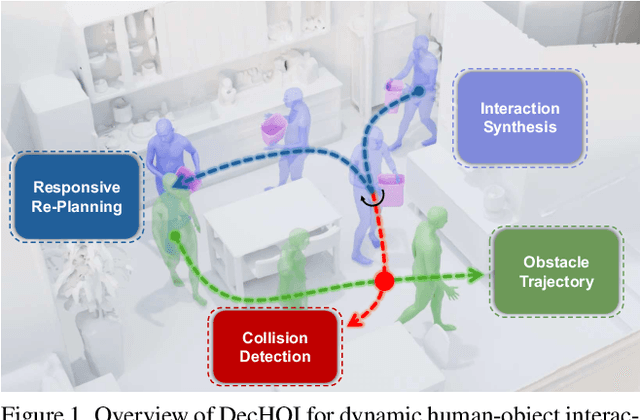
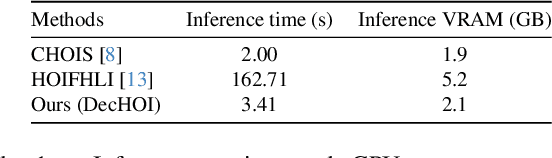
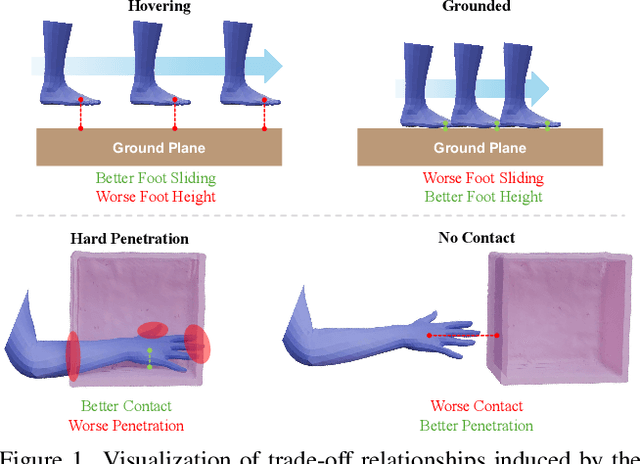
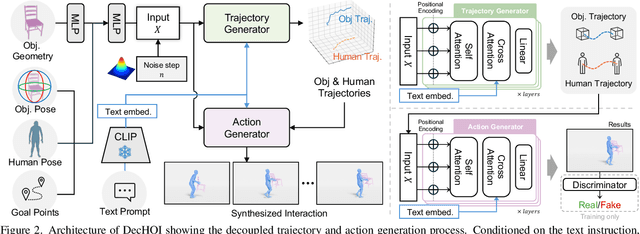
Synthesizing realistic human-object interaction (HOI) is essential for 3D computer vision and robotics, underpinning animation and embodied control. Existing approaches often require manually specified intermediate waypoints and place all optimization objectives on a single network, which increases complexity, reduces flexibility, and leads to errors such as unsynchronized human and object motion or penetration. To address these issues, we propose Decoupled Generative Modeling for Human-Object Interaction Synthesis (DecHOI), which separates path planning and action synthesis. A trajectory generator first produces human and object trajectories without prescribed waypoints, and an action generator conditions on these paths to synthesize detailed motions. To further improve contact realism, we employ adversarial training with a discriminator that focuses on the dynamics of distal joints. The framework also models a moving counterpart and supports responsive, long-sequence planning in dynamic scenes, while preserving plan consistency. Across two benchmarks, FullBodyManipulation and 3D-FUTURE, DecHOI surpasses prior methods on most quantitative metrics and qualitative evaluations, and perceptual studies likewise prefer our results.
Gaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
Dec 17, 2025We present Gaussian Pixel Codec Avatars (GPiCA), photorealistic head avatars that can be generated from multi-view images and efficiently rendered on mobile devices. GPiCA utilizes a unique hybrid representation that combines a triangle mesh and anisotropic 3D Gaussians. This combination maximizes memory and rendering efficiency while maintaining a photorealistic appearance. The triangle mesh is highly efficient in representing surface areas like facial skin, while the 3D Gaussians effectively handle non-surface areas such as hair and beard. To this end, we develop a unified differentiable rendering pipeline that treats the mesh as a semi-transparent layer within the volumetric rendering paradigm of 3D Gaussian Splatting. We train neural networks to decode a facial expression code into three components: a 3D face mesh, an RGBA texture, and a set of 3D Gaussians. These components are rendered simultaneously in a unified rendering engine. The networks are trained using multi-view image supervision. Our results demonstrate that GPiCA achieves the realism of purely Gaussian-based avatars while matching the rendering performance of mesh-based avatars.
A Real-world Display Inverse Rendering Dataset
Aug 20, 2025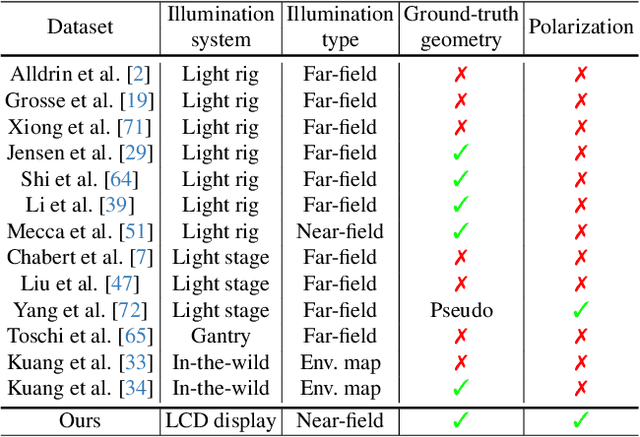
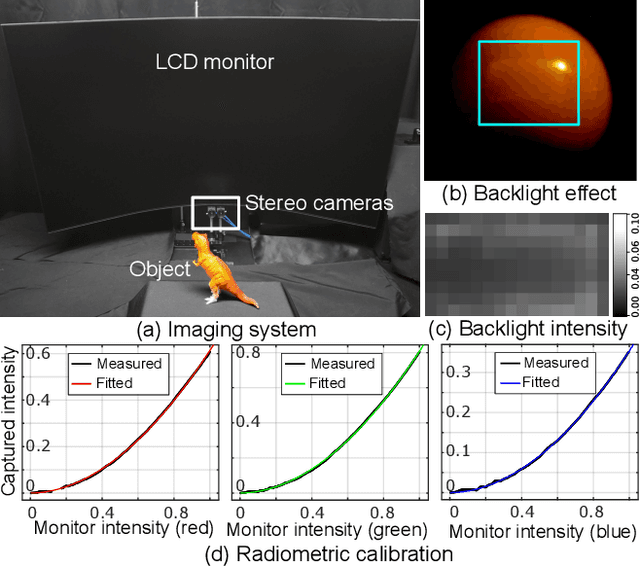


Inverse rendering aims to reconstruct geometry and reflectance from captured images. Display-camera imaging systems offer unique advantages for this task: each pixel can easily function as a programmable point light source, and the polarized light emitted by LCD displays facilitates diffuse-specular separation. Despite these benefits, there is currently no public real-world dataset captured using display-camera systems, unlike other setups such as light stages. This absence hinders the development and evaluation of display-based inverse rendering methods. In this paper, we introduce the first real-world dataset for display-based inverse rendering. To achieve this, we construct and calibrate an imaging system comprising an LCD display and stereo polarization cameras. We then capture a diverse set of objects with diverse geometry and reflectance under one-light-at-a-time (OLAT) display patterns. We also provide high-quality ground-truth geometry. Our dataset enables the synthesis of captured images under arbitrary display patterns and different noise levels. Using this dataset, we evaluate the performance of existing photometric stereo and inverse rendering methods, and provide a simple, yet effective baseline for display inverse rendering, outperforming state-of-the-art inverse rendering methods. Code and dataset are available on our project page at https://michaelcsj.github.io/DIR/
3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.