 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Distribution Matching for Amortized Sequential Monte Carlo in Discrete Diffusion
May 22, 2026Discrete diffusion models have emerged as powerful frameworks for generating structured categorical data. However, efficiently sampling from reward-tilted distributions remains a fundamental challenge. While Twisted Sequential Monte Carlo (SMC) offers asymptotic exactness for this task, estimating the optimal twist function in discrete state spaces necessitates costly Monte Carlo approximations, resulting a severe computational bottleneck at inference. To overcome this limitation, we introduce Contrastive Distribution Matching (CDM), a novel framework that amortizes the cost of SMC inference by learning a parameterized twist function via positive and negative samples. For efficient training, we reformulate the gradient estimator to leverage the closed-form forward kernels of discrete diffusion models. In practice, evaluating our learned twist function incurs less than 5% additional computational overhead compared to a single forward pass of the base model. Through extensive empirical evaluations, we demonstrate that CDM consistently outperforms existing baselines under matched wall-clock time. We validate the effectiveness and versatility of our approach across a diverse range of applications, including toxic text generation, regulatory DNA sequence design, protein designability, and diffusion large language model alignment.
Token Warping Helps MLLMs Look from Nearby Viewpoints
Apr 03, 2026Can warping tokens, rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint? While MLLMs perform well on visual reasoning, they remain fragile to viewpoint changes, as pixel-wise warping is highly sensitive to small depth errors and often introduces geometric distortions. Drawing on theories of mental imagery that posit part-level structural representations as the basis for human perspective transformation, we examine whether image tokens in ViT-based MLLMs serve as an effective substrate for viewpoint changes. We compare forward and backward warping, finding that backward token warping, which defines a dense grid on the target view and retrieves a corresponding source-view token for each grid point, achieves greater stability and better preserves semantic coherence under viewpoint shifts. Experiments on our proposed ViewBench benchmark demonstrate that token-level warping enables MLLMs to reason reliably from nearby viewpoints, consistently outperforming all baselines including pixel-wise warping approaches, spatially fine-tuned MLLMs, and a generative warping method.
BoxSplitGen: A Generative Model for 3D Part Bounding Boxes in Varying Granularity
Feb 24, 2026Human creativity follows a perceptual process, moving from abstract ideas to finer details during creation. While 3D generative models have advanced dramatically, models specifically designed to assist human imagination in 3D creation -- particularly for detailing abstractions from coarse to fine -- have not been explored. We propose a framework that enables intuitive and interactive 3D shape generation by iteratively splitting bounding boxes to refine the set of bounding boxes. The main technical components of our framework are two generative models: the box-splitting generative model and the box-to-shape generative model. The first model, named BoxSplitGen, generates a collection of 3D part bounding boxes with varying granularity by iteratively splitting coarse bounding boxes. It utilizes part bounding boxes created through agglomerative merging and learns the reverse of the merging process -- the splitting sequences. The model consists of two main components: the first learns the categorical distribution of the box to be split, and the second learns the distribution of the two new boxes, given the set of boxes and the indication of which box to split. The second model, the box-to-shape generative model, is trained by leveraging the 3D shape priors learned by an existing 3D diffusion model while adapting the model to incorporate bounding box conditioning. In our experiments, we demonstrate that the box-splitting generative model outperforms token prediction models and the inpainting approach with an unconditional diffusion model. Also, we show that our box-to-shape model, based on a state-of-the-art 3D diffusion model, provides superior results compared to a previous model.
DiffusionRollout: Uncertainty-Aware Rollout Planning in Long-Horizon PDE Solving
Feb 14, 2026We propose DiffusionRollout, a novel selective rollout planning strategy for autoregressive diffusion models, aimed at mitigating error accumulation in long-horizon predictions of physical systems governed by partial differential equations (PDEs). Building on the recently validated probabilistic approach to PDE solving, we further explore its ability to quantify predictive uncertainty and demonstrate a strong correlation between prediction errors and standard deviations computed over multiple samples-supporting their use as a proxy for the model's predictive confidence. Based on this observation, we introduce a mechanism that adaptively selects step sizes during autoregressive rollouts, improving long-term prediction reliability by reducing the compounding effect of conditioning on inaccurate prior outputs. Extensive evaluation on long-trajectory PDE prediction benchmarks validates the effectiveness of the proposed uncertainty measure and adaptive planning strategy, as evidenced by lower prediction errors and longer predicted trajectories that retain a high correlation with their ground truths.
Reward-Guided Discrete Diffusion via Clean-Sample Markov Chain for Molecule and Biological Sequence Design
Feb 10, 2026Discrete diffusion models have recently emerged as a powerful class of generative models for chemistry and biology data. In these fields, the goal is to generate various samples with high rewards (e.g., drug-likeness in molecules), making reward-based guidance crucial. Most existing methods are based on guiding the diffusion model using intermediate rewards but tend to underperform since intermediate rewards are noisy due to the non-smooth nature of reward functions used in scientific domains. To address this, we propose Clean-Sample Markov Chain (CSMC) Sampler, a method that performs effective test-time reward-guided sampling for discrete diffusion models, enabling local search without relying on intermediate rewards. CSMC constructs a Markov chain of clean samples using the Metropolis-Hastings algorithm such that its stationary distribution is the target distribution. We design a proposal distribution by sequentially applying the forward and backward diffusion processes, making the acceptance probability tractable. Experiments on molecule and biological sequence generation with various reward functions demonstrate that our method consistently outperforms prior approaches that rely on intermediate rewards.
Projected Gradient Ascent for Efficient Reward-Guided Updates with One-Step Generative Models
Feb 09, 2026We propose a constrained latent optimization method for reward-guided generation that preserves white Gaussian noise characteristics with negligible overhead. Test-time latent optimization can unlock substantially better reward-guided generations from pretrained generative models, but it is prone to reward hacking that degrades quality and also too slow for practical use. In this work, we make test-time optimization both efficient and reliable by replacing soft regularization with hard white Gaussian noise constraints enforced via projected gradient ascent. Our method applies a closed-form projection after each update to keep the latent vector explicitly noise-like throughout optimization, preventing the drift that leads to unrealistic artifacts. This enforcement adds minimal cost: the projection matches the $O(N \log N)$ complexity of standard algorithms such as sorting or FFT and does not practically increase wall-clock time. In experiments, our approach reaches a comparable Aesthetic Score using only 30% of the wall-clock time required by the SOTA regularization-based method, while preventing reward hacking.
CAMO: Category-Agnostic 3D Motion Transfer from Monocular 2D Videos
Jan 06, 2026Motion transfer from 2D videos to 3D assets is a challenging problem, due to inherent pose ambiguities and diverse object shapes, often requiring category-specific parametric templates. We propose CAMO, a category-agnostic framework that transfers motion to diverse target meshes directly from monocular 2D videos without relying on predefined templates or explicit 3D supervision. The core of CAMO is a morphology-parameterized articulated 3D Gaussian splatting model combined with dense semantic correspondences to jointly adapt shape and pose through optimization. This approach effectively alleviates shape-pose ambiguities, enabling visually faithful motion transfer for diverse categories. Experimental results demonstrate superior motion accuracy, efficiency, and visual coherence compared to existing methods, significantly advancing motion transfer in varied object categories and casual video scenarios.
BézierFlow: Learning Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 28, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
PairFlow: Closed-Form Source-Target Coupling for Few-Step Generation in Discrete Flow Models
Dec 23, 2025We introduce $\texttt{PairFlow}$, a lightweight preprocessing step for training Discrete Flow Models (DFMs) to achieve few-step sampling without requiring a pretrained teacher. DFMs have recently emerged as a new class of generative models for discrete data, offering strong performance. However, they suffer from slow sampling due to their iterative nature. Existing acceleration methods largely depend on finetuning, which introduces substantial additional training overhead. $\texttt{PairFlow}$ addresses this issue with a lightweight preprocessing step. Inspired by ReFlow and its extension to DFMs, we train DFMs from coupled samples of source and target distributions, without requiring any pretrained teacher. At the core of our approach is a closed-form inversion for DFMs, which allows efficient construction of paired source-target samples. Despite its extremely low cost, taking only up to 1.7% of the compute needed for full model training, $\texttt{PairFlow}$ matches or even surpasses the performance of two-stage training involving finetuning. Furthermore, models trained with our framework provide stronger base models for subsequent distillation, yielding further acceleration after finetuning. Experiments on molecular data as well as binary and RGB images demonstrate the broad applicability and effectiveness of our approach.
MatLat: Material Latent Space for PBR Texture Generation
Dec 19, 2025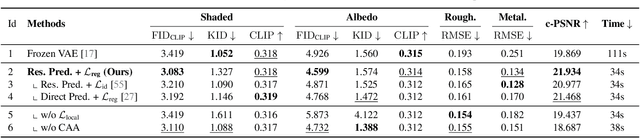
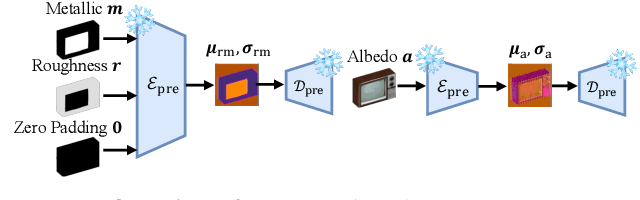
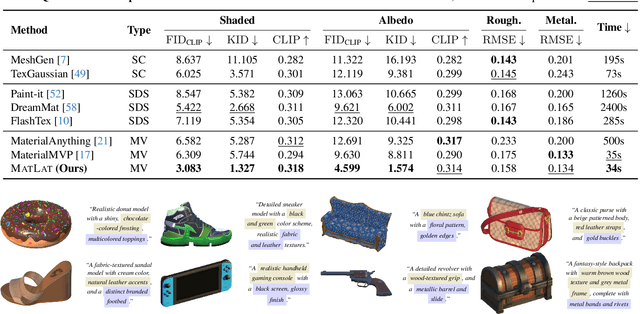
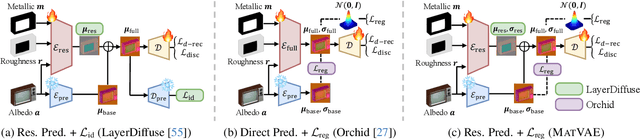
We propose a generative framework for producing high-quality PBR textures on a given 3D mesh. As large-scale PBR texture datasets are scarce, our approach focuses on effectively leveraging the embedding space and diffusion priors of pretrained latent image generative models while learning a material latent space, MatLat, through targeted fine-tuning. Unlike prior methods that freeze the embedding network and thus lead to distribution shifts when encoding additional PBR channels and hinder subsequent diffusion training, we fine-tune the pretrained VAE so that new material channels can be incorporated with minimal latent distribution deviation. We further show that correspondence-aware attention alone is insufficient for cross-view consistency unless the latent-to-image mapping preserves locality. To enforce this locality, we introduce a regularization in the VAE fine-tuning that crops latent patches, decodes them, and aligns the corresponding image regions to maintain strong pixel-latent spatial correspondence. Ablation studies and comparison with previous baselines demonstrate that our framework improves PBR texture fidelity and that each component is critical for achieving state-of-the-art performance.