 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Distribution Matching for Amortized Sequential Monte Carlo in Discrete Diffusion
May 22, 2026Discrete diffusion models have emerged as powerful frameworks for generating structured categorical data. However, efficiently sampling from reward-tilted distributions remains a fundamental challenge. While Twisted Sequential Monte Carlo (SMC) offers asymptotic exactness for this task, estimating the optimal twist function in discrete state spaces necessitates costly Monte Carlo approximations, resulting a severe computational bottleneck at inference. To overcome this limitation, we introduce Contrastive Distribution Matching (CDM), a novel framework that amortizes the cost of SMC inference by learning a parameterized twist function via positive and negative samples. For efficient training, we reformulate the gradient estimator to leverage the closed-form forward kernels of discrete diffusion models. In practice, evaluating our learned twist function incurs less than 5% additional computational overhead compared to a single forward pass of the base model. Through extensive empirical evaluations, we demonstrate that CDM consistently outperforms existing baselines under matched wall-clock time. We validate the effectiveness and versatility of our approach across a diverse range of applications, including toxic text generation, regulatory DNA sequence design, protein designability, and diffusion large language model alignment.
MatLat: Material Latent Space for PBR Texture Generation
Dec 19, 2025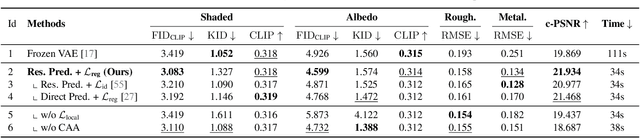
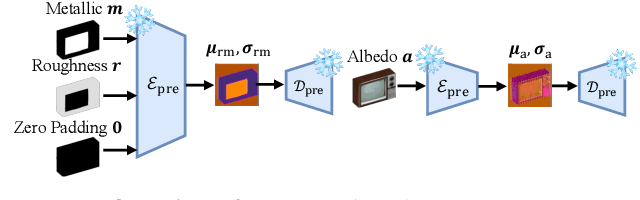
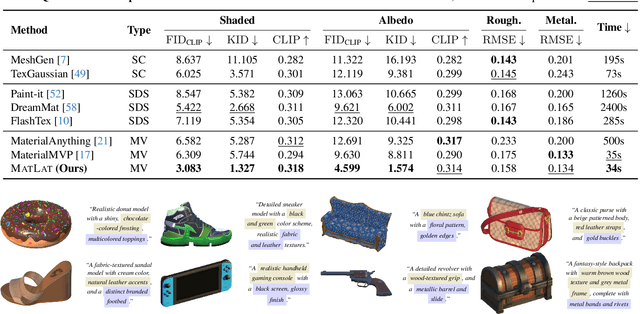
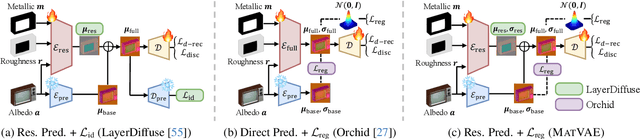
We propose a generative framework for producing high-quality PBR textures on a given 3D mesh. As large-scale PBR texture datasets are scarce, our approach focuses on effectively leveraging the embedding space and diffusion priors of pretrained latent image generative models while learning a material latent space, MatLat, through targeted fine-tuning. Unlike prior methods that freeze the embedding network and thus lead to distribution shifts when encoding additional PBR channels and hinder subsequent diffusion training, we fine-tune the pretrained VAE so that new material channels can be incorporated with minimal latent distribution deviation. We further show that correspondence-aware attention alone is insufficient for cross-view consistency unless the latent-to-image mapping preserves locality. To enforce this locality, we introduce a regularization in the VAE fine-tuning that crops latent patches, decodes them, and aligns the corresponding image regions to maintain strong pixel-latent spatial correspondence. Ablation studies and comparison with previous baselines demonstrate that our framework improves PBR texture fidelity and that each component is critical for achieving state-of-the-art performance.
Inference-Time Scaling for Flow Models via Stochastic Generation and Rollover Budget Forcing
Mar 26, 2025We propose an inference-time scaling approach for pretrained flow models. Recently, inference-time scaling has gained significant attention in LLMs and diffusion models, improving sample quality or better aligning outputs with user preferences by leveraging additional computation. For diffusion models, particle sampling has allowed more efficient scaling due to the stochasticity at intermediate denoising steps. On the contrary, while flow models have gained popularity as an alternative to diffusion models--offering faster generation and high-quality outputs in state-of-the-art image and video generative models--efficient inference-time scaling methods used for diffusion models cannot be directly applied due to their deterministic generative process. To enable efficient inference-time scaling for flow models, we propose three key ideas: 1) SDE-based generation, enabling particle sampling in flow models, 2) Interpolant conversion, broadening the search space and enhancing sample diversity, and 3) Rollover Budget Forcing (RBF), an adaptive allocation of computational resources across timesteps to maximize budget utilization. Our experiments show that SDE-based generation, particularly variance-preserving (VP) interpolant-based generation, improves the performance of particle sampling methods for inference-time scaling in flow models. Additionally, we demonstrate that RBF with VP-SDE achieves the best performance, outperforming all previous inference-time scaling approaches.
Unconditional Priors Matter! Improving Conditional Generation of Fine-Tuned Diffusion Models
Mar 26, 2025



Classifier-Free Guidance (CFG) is a fundamental technique in training conditional diffusion models. The common practice for CFG-based training is to use a single network to learn both conditional and unconditional noise prediction, with a small dropout rate for conditioning. However, we observe that the joint learning of unconditional noise with limited bandwidth in training results in poor priors for the unconditional case. More importantly, these poor unconditional noise predictions become a serious reason for degrading the quality of conditional generation. Inspired by the fact that most CFG-based conditional models are trained by fine-tuning a base model with better unconditional generation, we first show that simply replacing the unconditional noise in CFG with that predicted by the base model can significantly improve conditional generation. Furthermore, we show that a diffusion model other than the one the fine-tuned model was trained on can be used for unconditional noise replacement. We experimentally verify our claim with a range of CFG-based conditional models for both image and video generation, including Zero-1-to-3, Versatile Diffusion, DiT, DynamiCrafter, and InstructPix2Pix.
StochSync: Stochastic Diffusion Synchronization for Image Generation in Arbitrary Spaces
Jan 26, 2025



We propose a zero-shot method for generating images in arbitrary spaces (e.g., a sphere for 360{\deg} panoramas and a mesh surface for texture) using a pretrained image diffusion model. The zero-shot generation of various visual content using a pretrained image diffusion model has been explored mainly in two directions. First, Diffusion Synchronization-performing reverse diffusion processes jointly across different projected spaces while synchronizing them in the target space-generates high-quality outputs when enough conditioning is provided, but it struggles in its absence. Second, Score Distillation Sampling-gradually updating the target space data through gradient descent-results in better coherence but often lacks detail. In this paper, we reveal for the first time the interconnection between these two methods while highlighting their differences. To this end, we propose StochSync, a novel approach that combines the strengths of both, enabling effective performance with weak conditioning. Our experiments demonstrate that StochSync provides the best performance in 360{\deg} panorama generation (where image conditioning is not given), outperforming previous finetuning-based methods, and also delivers comparable results in 3D mesh texturing (where depth conditioning is provided) with previous methods.
SyncTweedies: A General Generative Framework Based on Synchronized Diffusions
Mar 22, 2024



We introduce a general framework for generating diverse visual content, including ambiguous images, panorama images, mesh textures, and Gaussian splat textures, by synchronizing multiple diffusion processes. We present exhaustive investigation into all possible scenarios for synchronizing multiple diffusion processes through a canonical space and analyze their characteristics across applications. In doing so, we reveal a previously unexplored case: averaging the outputs of Tweedie's formula while conducting denoising in multiple instance spaces. This case also provides the best quality with the widest applicability to downstream tasks. We name this case SyncTweedies. In our experiments generating visual content aforementioned, we demonstrate the superior quality of generation by SyncTweedies compared to other synchronization methods, optimization-based and iterative-update-based methods.