 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Ambulatory Vision: Learning Visually-Grounded Active View Selection
Dec 15, 2025Vision Language Models (VLMs) excel at visual question answering (VQA) but remain limited to snapshot vision, reasoning from static images. In contrast, embodied agents require ambulatory vision, actively moving to obtain more informative views. We introduce Visually Grounded Active View Selection (VG-AVS), a task that selects the most informative next viewpoint using only the visual information in the current image, without relying on scene memory or external knowledge. To support this task, we construct a synthetic dataset with automatically generated paired query-target views and question-answer prompts. We also propose a framework that fine-tunes pretrained VLMs through supervised fine-tuning (SFT) followed by RL-based policy optimization. Our approach achieves strong question answering performance based on viewpoint selection and generalizes robustly to unseen synthetic and real scenes. Furthermore, incorporating our learned VG-AVS framework into existing scene-exploration-based EQA systems improves downstream question-answering accuracy.
Perspective-Aware Reasoning in Vision-Language Models via Mental Imagery Simulation
Apr 24, 2025We present a framework for perspective-aware reasoning in vision-language models (VLMs) through mental imagery simulation. Perspective-taking, the ability to perceive an environment or situation from an alternative viewpoint, is a key benchmark for human-level visual understanding, essential for environmental interaction and collaboration with autonomous agents. Despite advancements in spatial reasoning within VLMs, recent research has shown that modern VLMs significantly lack perspective-aware reasoning capabilities and exhibit a strong bias toward egocentric interpretations. To bridge the gap between VLMs and human perception, we focus on the role of mental imagery, where humans perceive the world through abstracted representations that facilitate perspective shifts. Motivated by this, we propose a framework for perspective-aware reasoning, named Abstract Perspective Change (APC), that effectively leverages vision foundation models, such as object detection, segmentation, and orientation estimation, to construct scene abstractions and enable perspective transformations. Our experiments on synthetic and real-image benchmarks, compared with various VLMs, demonstrate significant improvements in perspective-aware reasoning with our framework, further outperforming fine-tuned spatial reasoning models and novel-view-synthesis-based approaches.
Unconditional Priors Matter! Improving Conditional Generation of Fine-Tuned Diffusion Models
Mar 26, 2025



Classifier-Free Guidance (CFG) is a fundamental technique in training conditional diffusion models. The common practice for CFG-based training is to use a single network to learn both conditional and unconditional noise prediction, with a small dropout rate for conditioning. However, we observe that the joint learning of unconditional noise with limited bandwidth in training results in poor priors for the unconditional case. More importantly, these poor unconditional noise predictions become a serious reason for degrading the quality of conditional generation. Inspired by the fact that most CFG-based conditional models are trained by fine-tuning a base model with better unconditional generation, we first show that simply replacing the unconditional noise in CFG with that predicted by the base model can significantly improve conditional generation. Furthermore, we show that a diffusion model other than the one the fine-tuned model was trained on can be used for unconditional noise replacement. We experimentally verify our claim with a range of CFG-based conditional models for both image and video generation, including Zero-1-to-3, Versatile Diffusion, DiT, DynamiCrafter, and InstructPix2Pix.
GrounDiT: Grounding Diffusion Transformers via Noisy Patch Transplantation
Oct 27, 2024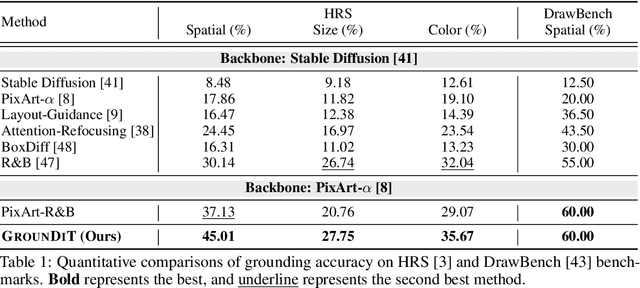
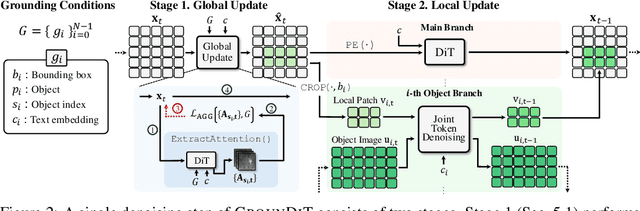

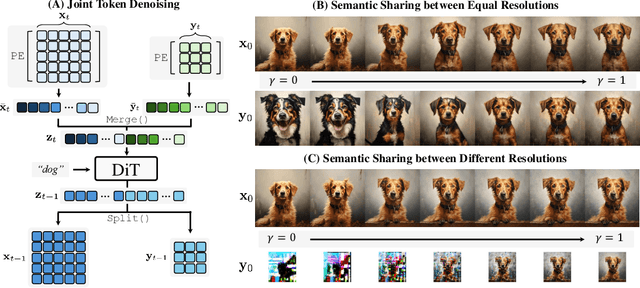
We introduce a novel training-free spatial grounding technique for text-to-image generation using Diffusion Transformers (DiT). Spatial grounding with bounding boxes has gained attention for its simplicity and versatility, allowing for enhanced user control in image generation. However, prior training-free approaches often rely on updating the noisy image during the reverse diffusion process via backpropagation from custom loss functions, which frequently struggle to provide precise control over individual bounding boxes. In this work, we leverage the flexibility of the Transformer architecture, demonstrating that DiT can generate noisy patches corresponding to each bounding box, fully encoding the target object and allowing for fine-grained control over each region. Our approach builds on an intriguing property of DiT, which we refer to as semantic sharing. Due to semantic sharing, when a smaller patch is jointly denoised alongside a generatable-size image, the two become "semantic clones". Each patch is denoised in its own branch of the generation process and then transplanted into the corresponding region of the original noisy image at each timestep, resulting in robust spatial grounding for each bounding box. In our experiments on the HRS and DrawBench benchmarks, we achieve state-of-the-art performance compared to previous training-free spatial grounding approaches.