 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling for Flow Models via Stochastic Generation and Rollover Budget Forcing
Mar 26, 2025We propose an inference-time scaling approach for pretrained flow models. Recently, inference-time scaling has gained significant attention in LLMs and diffusion models, improving sample quality or better aligning outputs with user preferences by leveraging additional computation. For diffusion models, particle sampling has allowed more efficient scaling due to the stochasticity at intermediate denoising steps. On the contrary, while flow models have gained popularity as an alternative to diffusion models--offering faster generation and high-quality outputs in state-of-the-art image and video generative models--efficient inference-time scaling methods used for diffusion models cannot be directly applied due to their deterministic generative process. To enable efficient inference-time scaling for flow models, we propose three key ideas: 1) SDE-based generation, enabling particle sampling in flow models, 2) Interpolant conversion, broadening the search space and enhancing sample diversity, and 3) Rollover Budget Forcing (RBF), an adaptive allocation of computational resources across timesteps to maximize budget utilization. Our experiments show that SDE-based generation, particularly variance-preserving (VP) interpolant-based generation, improves the performance of particle sampling methods for inference-time scaling in flow models. Additionally, we demonstrate that RBF with VP-SDE achieves the best performance, outperforming all previous inference-time scaling approaches.
GrounDiT: Grounding Diffusion Transformers via Noisy Patch Transplantation
Oct 27, 2024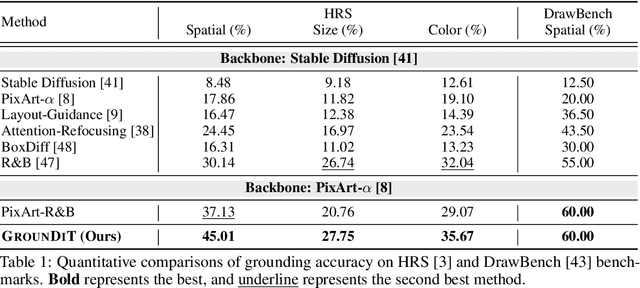
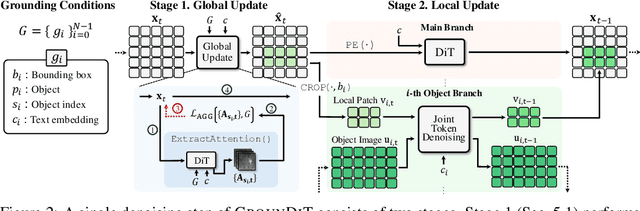

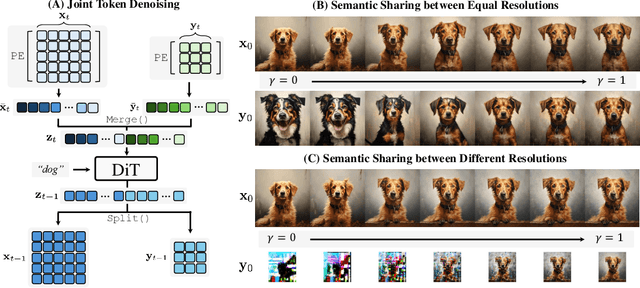
We introduce a novel training-free spatial grounding technique for text-to-image generation using Diffusion Transformers (DiT). Spatial grounding with bounding boxes has gained attention for its simplicity and versatility, allowing for enhanced user control in image generation. However, prior training-free approaches often rely on updating the noisy image during the reverse diffusion process via backpropagation from custom loss functions, which frequently struggle to provide precise control over individual bounding boxes. In this work, we leverage the flexibility of the Transformer architecture, demonstrating that DiT can generate noisy patches corresponding to each bounding box, fully encoding the target object and allowing for fine-grained control over each region. Our approach builds on an intriguing property of DiT, which we refer to as semantic sharing. Due to semantic sharing, when a smaller patch is jointly denoised alongside a generatable-size image, the two become "semantic clones". Each patch is denoised in its own branch of the generation process and then transplanted into the corresponding region of the original noisy image at each timestep, resulting in robust spatial grounding for each bounding box. In our experiments on the HRS and DrawBench benchmarks, we achieve state-of-the-art performance compared to previous training-free spatial grounding approaches.