 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconditional Priors Matter! Improving Conditional Generation of Fine-Tuned Diffusion Models
Mar 26, 2025



Classifier-Free Guidance (CFG) is a fundamental technique in training conditional diffusion models. The common practice for CFG-based training is to use a single network to learn both conditional and unconditional noise prediction, with a small dropout rate for conditioning. However, we observe that the joint learning of unconditional noise with limited bandwidth in training results in poor priors for the unconditional case. More importantly, these poor unconditional noise predictions become a serious reason for degrading the quality of conditional generation. Inspired by the fact that most CFG-based conditional models are trained by fine-tuning a base model with better unconditional generation, we first show that simply replacing the unconditional noise in CFG with that predicted by the base model can significantly improve conditional generation. Furthermore, we show that a diffusion model other than the one the fine-tuned model was trained on can be used for unconditional noise replacement. We experimentally verify our claim with a range of CFG-based conditional models for both image and video generation, including Zero-1-to-3, Versatile Diffusion, DiT, DynamiCrafter, and InstructPix2Pix.
Large Catapults in Momentum Gradient Descent with Warmup: An Empirical Study
Nov 25, 2023
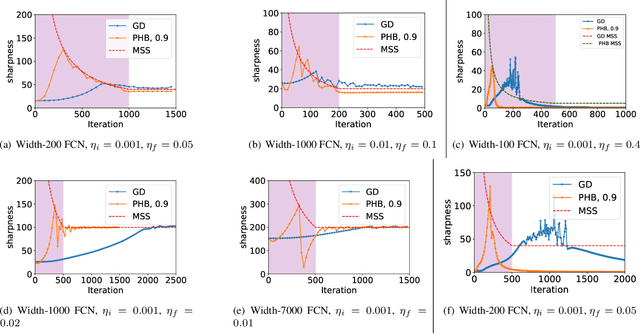
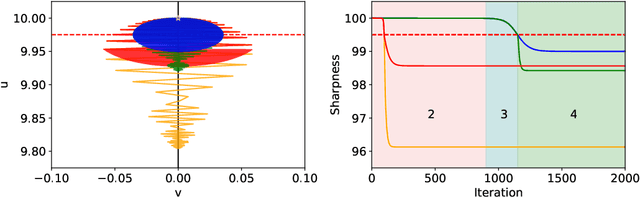

Although gradient descent with momentum is widely used in modern deep learning, a concrete understanding of its effects on the training trajectory still remains elusive. In this work, we empirically show that momentum gradient descent with a large learning rate and learning rate warmup displays large catapults, driving the iterates towards flatter minima than those found by gradient descent. We then provide empirical evidence and theoretical intuition that the large catapult is caused by momentum "amplifying" the self-stabilization effect (Damian et al., 2023).