 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in LLMs by Expectation Maximization
Dec 23, 2025

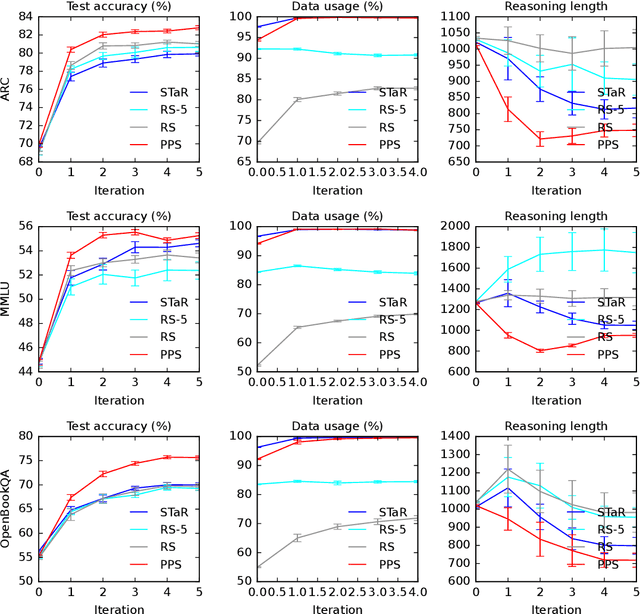
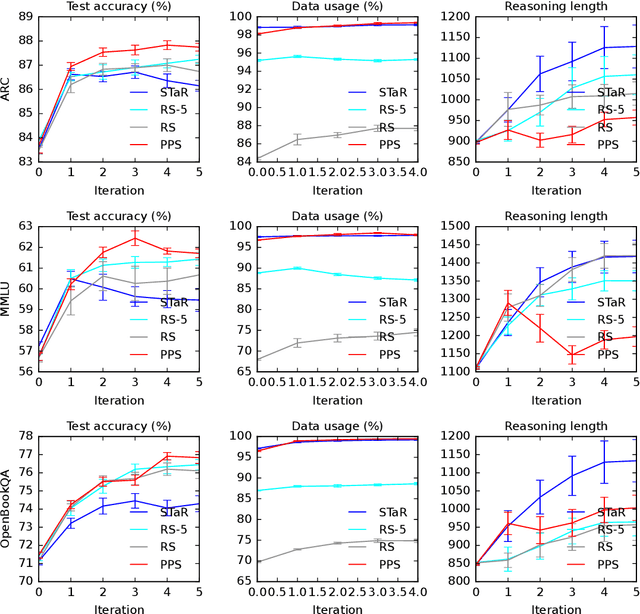
Large language models (LLMs) solve reasoning problems by first generating a rationale and then answering. We formalize reasoning as a latent variable model and derive an expectation-maximization (EM) objective for learning to reason. This view connects EM and modern reward-based optimization, and shows that the main challenge lies in designing a sampling distribution that generates rationales that justify correct answers. We instantiate and compare several sampling schemes: rejection sampling with a budget, self-taught reasoner (STaR), and prompt posterior sampling (PPS), which only keeps the rationalization stage of STaR. Our experiments on the ARC, MMLU, and OpenBookQA datasets with the Llama and Qwen models show that the sampling scheme can significantly affect the accuracy of learned reasoning models. Despite its simplicity, we observe that PPS outperforms the other sampling schemes.
AdaSTaR: Adaptive Data Sampling for Training Self-Taught Reasoners
May 22, 2025Self-Taught Reasoners (STaR), synonymously known as Rejection sampling Fine-Tuning (RFT), is an integral part of the training pipeline of self-improving reasoning Language Models (LMs). The self-improving mechanism often employs random observation (data) sampling. However, this results in trained observation imbalance; inefficiently over-training on solved examples while under-training on challenging ones. In response, we introduce Adaptive STaR (AdaSTaR), a novel algorithm that rectifies this by integrating two adaptive sampling principles: (1) Adaptive Sampling for Diversity: promoting balanced training across observations, and (2) Adaptive Sampling for Curriculum: dynamically adjusting data difficulty to match the model's evolving strength. Across six benchmarks, AdaSTaR achieves best test accuracy in all instances (6/6) and reduces training FLOPs by an average of 58.6% against an extensive list of baselines. These improvements in performance and efficiency generalize to different pre-trained LMs and larger models, paving the way for more efficient and effective self-improving LMs.
Probability-Flow ODE in Infinite-Dimensional Function Spaces
Mar 13, 2025Recent advances in infinite-dimensional diffusion models have demonstrated their effectiveness and scalability in function generation tasks where the underlying structure is inherently infinite-dimensional. To accelerate inference in such models, we derive, for the first time, an analog of the probability-flow ODE (PF-ODE) in infinite-dimensional function spaces. Leveraging this newly formulated PF-ODE, we reduce the number of function evaluations while maintaining sample quality in function generation tasks, including applications to PDEs.
FlickerFusion: Intra-trajectory Domain Generalizing Multi-Agent RL
Oct 21, 2024



Multi-agent reinforcement learning has demonstrated significant potential in addressing complex cooperative tasks across various real-world applications. However, existing MARL approaches often rely on the restrictive assumption that the number of entities (e.g., agents, obstacles) remains constant between training and inference. This overlooks scenarios where entities are dynamically removed or added during the inference trajectory -- a common occurrence in real-world environments like search and rescue missions and dynamic combat situations. In this paper, we tackle the challenge of intra-trajectory dynamic entity composition under zero-shot out-of-domain (OOD) generalization, where such dynamic changes cannot be anticipated beforehand. Our empirical studies reveal that existing MARL methods suffer significant performance degradation and increased uncertainty in these scenarios. In response, we propose FlickerFusion, a novel OOD generalization method that acts as a universally applicable augmentation technique for MARL backbone methods. Our results show that FlickerFusion not only achieves superior inference rewards but also uniquely reduces uncertainty vis-\`a-vis the backbone, compared to existing methods. For standardized evaluation, we introduce MPEv2, an enhanced version of Multi Particle Environments (MPE), consisting of 12 benchmarks. Benchmarks, implementations, and trained models are organized and open-sourced at flickerfusion305.github.io, accompanied by ample demo video renderings.
A Unified Confidence Sequence for Generalized Linear Models, with Applications to Bandits
Jul 19, 2024We present a unified likelihood ratio-based confidence sequence (CS) for any (self-concordant) generalized linear models (GLMs) that is guaranteed to be convex and numerically tight. We show that this is on par or improves upon known CSs for various GLMs, including Gaussian, Bernoulli, and Poisson. In particular, for the first time, our CS for Bernoulli has a poly(S)-free radius where S is the norm of the unknown parameter. Our first technical novelty is its derivation, which utilizes a time-uniform PAC-Bayesian bound with a uniform prior/posterior, despite the latter being a rather unpopular choice for deriving CSs. As a direct application of our new CS, we propose a simple and natural optimistic algorithm called OFUGLB applicable to any generalized linear bandits (GLB; Filippi et al. (2010)). Our analysis shows that the celebrated optimistic approach simultaneously attains state-of-the-art regrets for various self-concordant (not necessarily bounded) GLBs, and even poly(S)-free for bounded GLBs, including logistic bandits. The regret analysis, our second technical novelty, follows from combining our new CS with a new proof technique that completely avoids the previously widely used self-concordant control lemma (Faury et al., 2020, Lemma 9). Finally, we verify numerically that OFUGLB significantly outperforms the prior state-of-the-art (Lee et al., 2024) for logistic bandits.
Querying Easily Flip-flopped Samples for Deep Active Learning
Jan 18, 2024
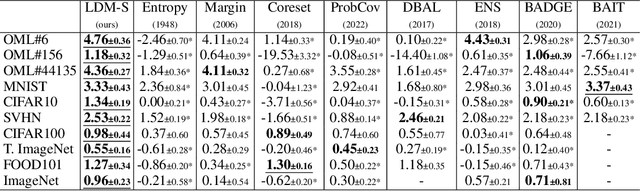

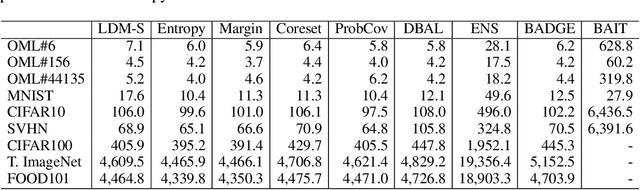
Active learning is a machine learning paradigm that aims to improve the performance of a model by strategically selecting and querying unlabeled data. One effective selection strategy is to base it on the model's predictive uncertainty, which can be interpreted as a measure of how informative a sample is. The sample's distance to the decision boundary is a natural measure of predictive uncertainty, but it is often intractable to compute, especially for complex decision boundaries formed in multiclass classification tasks. To address this issue, this paper proposes the {\it least disagree metric} (LDM), defined as the smallest probability of disagreement of the predicted label, and an estimator for LDM proven to be asymptotically consistent under mild assumptions. The estimator is computationally efficient and can be easily implemented for deep learning models using parameter perturbation. The LDM-based active learning is performed by querying unlabeled data with the smallest LDM. Experimental results show that our LDM-based active learning algorithm obtains state-of-the-art overall performance on all considered datasets and deep architectures.
Large Catapults in Momentum Gradient Descent with Warmup: An Empirical Study
Nov 25, 2023
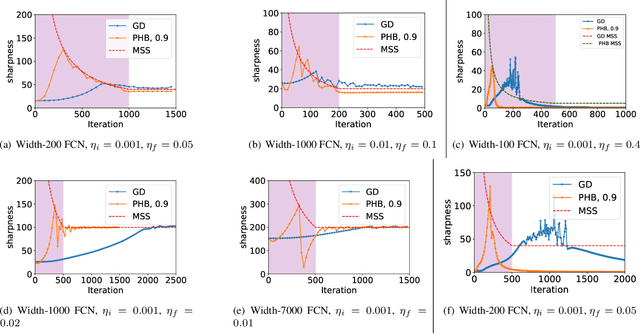
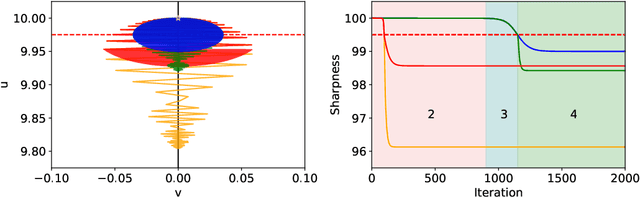

Although gradient descent with momentum is widely used in modern deep learning, a concrete understanding of its effects on the training trajectory still remains elusive. In this work, we empirically show that momentum gradient descent with a large learning rate and learning rate warmup displays large catapults, driving the iterates towards flatter minima than those found by gradient descent. We then provide empirical evidence and theoretical intuition that the large catapult is caused by momentum "amplifying" the self-stabilization effect (Damian et al., 2023).
Improved Regret Bounds of (Multinomial) Logistic Bandits via Regret-to-Confidence-Set Conversion
Oct 28, 2023Logistic bandit is a ubiquitous framework of modeling users' choices, e.g., click vs. no click for advertisement recommender system. We observe that the prior works overlook or neglect dependencies in $S \geq \lVert \theta_\star \rVert_2$, where $\theta_\star \in \mathbb{R}^d$ is the unknown parameter vector, which is particularly problematic when $S$ is large, e.g., $S \geq d$. In this work, we improve the dependency on $S$ via a novel approach called {\it regret-to-confidence set conversion (R2CS)}, which allows us to construct a convex confidence set based on only the \textit{existence} of an online learning algorithm with a regret guarantee. Using R2CS, we obtain a strict improvement in the regret bound w.r.t. $S$ in logistic bandits while retaining computational feasibility and the dependence on other factors such as $d$ and $T$. We apply our new confidence set to the regret analyses of logistic bandits with a new martingale concentration step that circumvents an additional factor of $S$. We then extend this analysis to multinomial logistic bandits and obtain similar improvements in the regret, showing the efficacy of R2CS. While we applied R2CS to the (multinomial) logistic model, R2CS is a generic approach for developing confidence sets that can be used for various models, which can be of independent interest.
Fair Streaming Principal Component Analysis: Statistical and Algorithmic Viewpoint
Oct 28, 2023Fair Principal Component Analysis (PCA) is a problem setting where we aim to perform PCA while making the resulting representation fair in that the projected distributions, conditional on the sensitive attributes, match one another. However, existing approaches to fair PCA have two main problems: theoretically, there has been no statistical foundation of fair PCA in terms of learnability; practically, limited memory prevents us from using existing approaches, as they explicitly rely on full access to the entire data. On the theoretical side, we rigorously formulate fair PCA using a new notion called \emph{probably approximately fair and optimal} (PAFO) learnability. On the practical side, motivated by recent advances in streaming algorithms for addressing memory limitation, we propose a new setting called \emph{fair streaming PCA} along with a memory-efficient algorithm, fair noisy power method (FNPM). We then provide its {\it statistical} guarantee in terms of PAFO-learnability, which is the first of its kind in fair PCA literature. Lastly, we verify the efficacy and memory efficiency of our algorithm on real-world datasets.
Optimizing Layerwise Polynomial Approximation for Efficient Private Inference on Fully Homomorphic Encryption: A Dynamic Programming Approach
Oct 16, 2023Recent research has explored the implementation of privacy-preserving deep neural networks solely using fully homomorphic encryption. However, its practicality has been limited because of prolonged inference times. When using a pre-trained model without retraining, a major factor contributing to these prolonged inference times is the high-degree polynomial approximation of activation functions such as the ReLU function. The high-degree approximation consumes a substantial amount of homomorphic computational resources, resulting in slower inference. Unlike the previous works approximating activation functions uniformly and conservatively, this paper presents a \emph{layerwise} degree optimization of activation functions to aggressively reduce the inference time while maintaining classification accuracy by taking into account the characteristics of each layer. Instead of the minimax approximation commonly used in state-of-the-art private inference models, we employ the weighted least squares approximation method with the input distributions of activation functions. Then, we obtain the layerwise optimized degrees for activation functions through the \emph{dynamic programming} algorithm, considering how each layer's approximation error affects the classification accuracy of the deep neural network. Furthermore, we propose modulating the ciphertext moduli-chain layerwise to reduce the inference time. By these proposed layerwise optimization methods, we can reduce inference times for the ResNet-20 model and the ResNet-32 model by 3.44 times and 3.16 times, respectively, in comparison to the prior implementations employing uniform degree polynomials and a consistent ciphertext modulus.