 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuerying Easily Flip-flopped Samples for Deep Active Learning
Jan 18, 2024
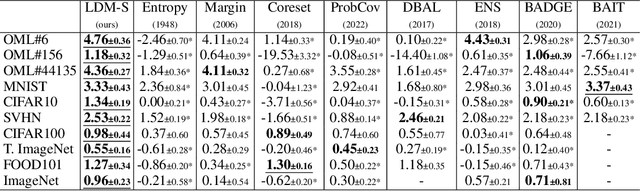

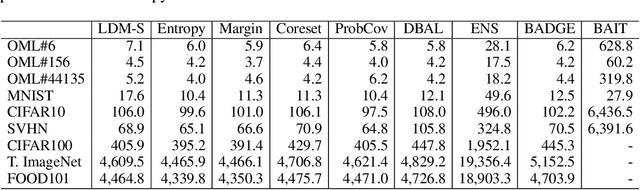
Active learning is a machine learning paradigm that aims to improve the performance of a model by strategically selecting and querying unlabeled data. One effective selection strategy is to base it on the model's predictive uncertainty, which can be interpreted as a measure of how informative a sample is. The sample's distance to the decision boundary is a natural measure of predictive uncertainty, but it is often intractable to compute, especially for complex decision boundaries formed in multiclass classification tasks. To address this issue, this paper proposes the {\it least disagree metric} (LDM), defined as the smallest probability of disagreement of the predicted label, and an estimator for LDM proven to be asymptotically consistent under mild assumptions. The estimator is computationally efficient and can be easily implemented for deep learning models using parameter perturbation. The LDM-based active learning is performed by querying unlabeled data with the smallest LDM. Experimental results show that our LDM-based active learning algorithm obtains state-of-the-art overall performance on all considered datasets and deep architectures.
ESD: Expected Squared Difference as a Tuning-Free Trainable Calibration Measure
Mar 04, 2023



Studies have shown that modern neural networks tend to be poorly calibrated due to over-confident predictions. Traditionally, post-processing methods have been used to calibrate the model after training. In recent years, various trainable calibration measures have been proposed to incorporate them directly into the training process. However, these methods all incorporate internal hyperparameters, and the performance of these calibration objectives relies on tuning these hyperparameters, incurring more computational costs as the size of neural networks and datasets become larger. As such, we present Expected Squared Difference (ESD), a tuning-free (i.e., hyperparameter-free) trainable calibration objective loss, where we view the calibration error from the perspective of the squared difference between the two expectations. With extensive experiments on several architectures (CNNs, Transformers) and datasets, we demonstrate that (1) incorporating ESD into the training improves model calibration in various batch size settings without the need for internal hyperparameter tuning, (2) ESD yields the best-calibrated results compared with previous approaches, and (3) ESD drastically improves the computational costs required for calibration during training due to the absence of internal hyperparameter. The code is publicly accessible at https://github.com/hee-suk-yoon/ESD.
Deep Neural Network Based Accelerated Failure Time Models using Rank Loss
Jun 13, 2022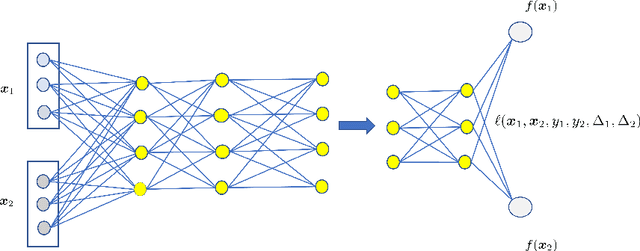
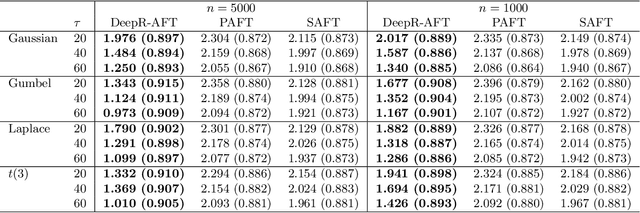
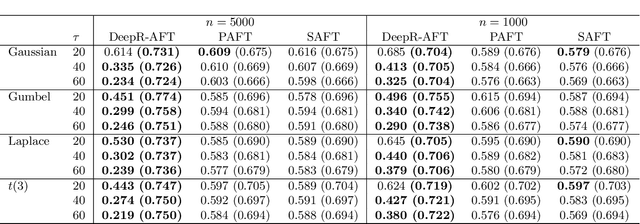
An accelerated failure time (AFT) model assumes a log-linear relationship between failure times and a set of covariates. In contrast to other popular survival models that work on hazard functions, the effects of covariates are directly on failure times, whose interpretation is intuitive. The semiparametric AFT model that does not specify the error distribution is flexible and robust to departures from the distributional assumption. Owing to the desirable features, this class of models has been considered as a promising alternative to the popular Cox model in the analysis of censored failure time data. However, in these AFT models, a linear predictor for the mean is typically assumed. Little research has addressed the nonlinearity of predictors when modeling the mean. Deep neural networks (DNNs) have received a focal attention over the past decades and have achieved remarkable success in a variety of fields. DNNs have a number of notable advantages and have been shown to be particularly useful in addressing the nonlinearity. By taking advantage of this, we propose to apply DNNs in fitting AFT models using a Gehan-type loss, combined with a sub-sampling technique. Finite sample properties of the proposed DNN and rank based AFT model (DeepR-AFT) are investigated via an extensive stimulation study. DeepR-AFT shows a superior performance over its parametric or semiparametric counterparts when the predictor is nonlinear. For linear predictors, DeepR-AFT performs better when the dimensions of covariates are large. The proposed DeepR-AFT is illustrated using two real datasets, which demonstrates its superiority.
Fast and Efficient MMD-based Fair PCA via Optimization over Stiefel Manifold
Sep 23, 2021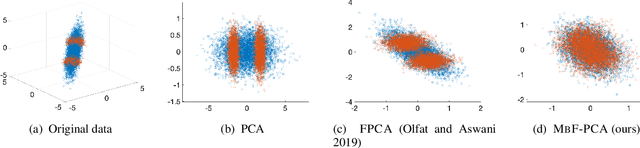
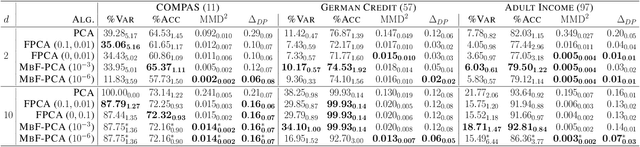
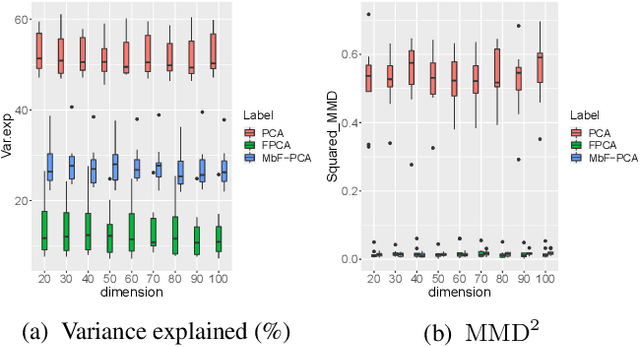
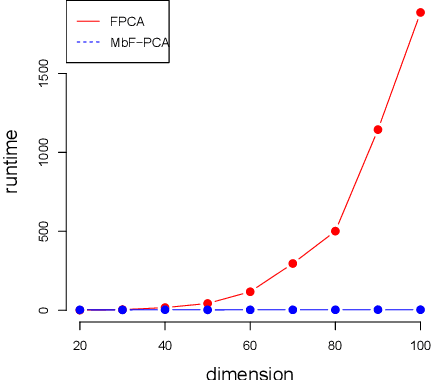
This paper defines fair principal component analysis (PCA) as minimizing the maximum mean discrepancy (MMD) between dimensionality-reduced conditional distributions of different protected classes. The incorporation of MMD naturally leads to an exact and tractable mathematical formulation of fairness with good statistical properties. We formulate the problem of fair PCA subject to MMD constraints as a non-convex optimization over the Stiefel manifold and solve it using the Riemannian Exact Penalty Method with Smoothing (REPMS; Liu and Boumal, 2019). Importantly, we provide local optimality guarantees and explicitly show the theoretical effect of each hyperparameter in practical settings, extending previous results. Experimental comparisons based on synthetic and UCI datasets show that our approach outperforms prior work in explained variance, fairness, and runtime.