 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuerying Easily Flip-flopped Samples for Deep Active Learning
Jan 18, 2024
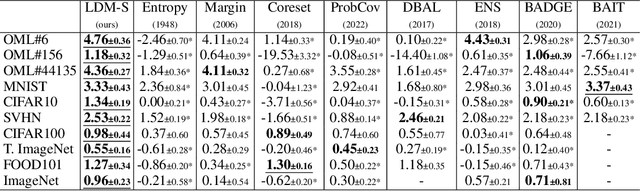

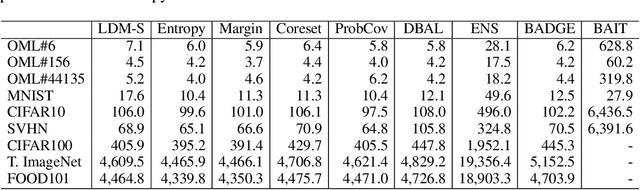
Active learning is a machine learning paradigm that aims to improve the performance of a model by strategically selecting and querying unlabeled data. One effective selection strategy is to base it on the model's predictive uncertainty, which can be interpreted as a measure of how informative a sample is. The sample's distance to the decision boundary is a natural measure of predictive uncertainty, but it is often intractable to compute, especially for complex decision boundaries formed in multiclass classification tasks. To address this issue, this paper proposes the {\it least disagree metric} (LDM), defined as the smallest probability of disagreement of the predicted label, and an estimator for LDM proven to be asymptotically consistent under mild assumptions. The estimator is computationally efficient and can be easily implemented for deep learning models using parameter perturbation. The LDM-based active learning is performed by querying unlabeled data with the smallest LDM. Experimental results show that our LDM-based active learning algorithm obtains state-of-the-art overall performance on all considered datasets and deep architectures.
A Resizable Mini-batch Gradient Descent based on a Multi-Armed Bandit
Feb 27, 2018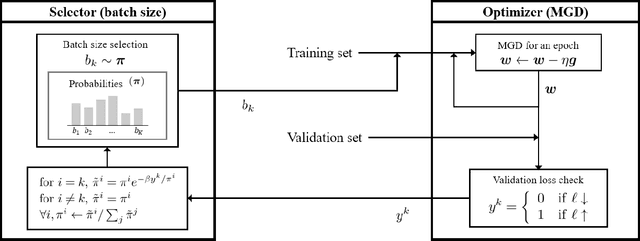

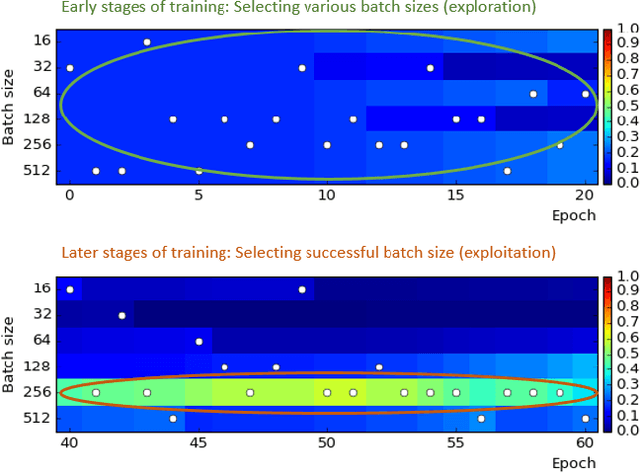
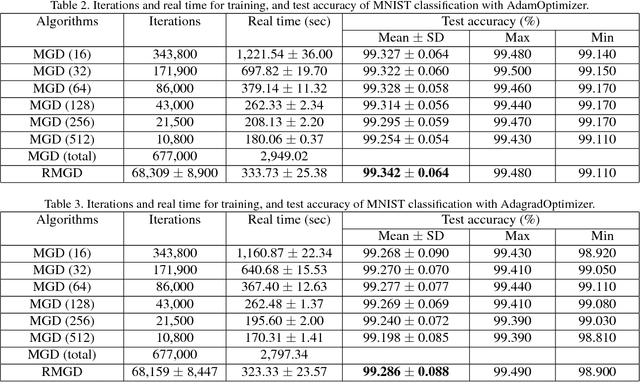
Determining the appropriate batch size for mini-batch gradient descent is always time consuming as it often relies on grid search. This paper considers a resizable mini-batch gradient descent (RMGD) algorithm based on a multi-armed bandit for achieving best performance in grid search by selecting an appropriate batch size at each epoch with a probability defined as a function of its previous success/failure. This probability encourages exploration of different batch size and then later exploitation of batch size with history of success. At each epoch, the RMGD samples a batch size from its probability distribution, then uses the selected batch size for mini-batch gradient descent. After obtaining the validation loss at each epoch, the probability distribution is updated to incorporate the effectiveness of the sampled batch size. The RMGD essentially assists the learning process to explore the possible domain of the batch size and exploit successful batch size. Experimental results show that the RMGD achieves performance better than the best performing single batch size. Furthermore, it, obviously, attains this performance in a shorter amount of time than grid search. It is surprising that the RMGD achieves better performance than grid search.